Google Gemini: Evolution, Technical features and app development
 Sulabh Sharma
Sulabh Sharma
Gemini, formerly known as Bard is a Generative Artificial Intelligence chatbot developed by Google. Based on the Large Language Model (LLM) developed by google Deep Mind, created to compete with OpenAI’s ChatGPT. It was launched in 2023 after being developed as a direct response to the rise of OpenAI's ChatGPT. Gemini AI can process and understand various data types (text, images, audio, code) also present ideas innovatively. Its reasoning capabilities are exceptional. Gemini AI can solve complex problems efficiently and generate high-quality code.
Evolution of Google Gemini
Gemini- Google introduced Gemini As a powerful Successor to PaLM 2 on May 10th 2023. Gemini was developed as a collaboration between DeepMind and Google Brain designed to be multimodal capable of processing text, images, video and computer code simultaneously.
Gemini 1.0- Gemini 1.0 was announced on Dec. 6, 2023, and built by Alphabet's Google DeepMind business unit which is focused on Advanced AI research and development. It comprises three models-Gemini Ultra- designed for highly complex tasks, fully released on February 2024. Gemini Pro- suited for a wide range of tasks. Gemini Nano- Optimized for on-device tasks. Gemini Pro and Nano were integrated into Bard and the Pixel 8 Pro smartphone, respectively.
Gemini 1.5- launched in February 2024 and In May 2024, Google announced enhancements to Gemini 1.5 Pro at the google I/O conference. Upgrades included performance improvements in translation, coding and reasoning features. The upgraded Google 1.5 Pro also improved image and video understanding, including the ability to directly process voice inputs using native audio understanding. The model's context window was increased to 2 million tokens enabling it to remember much more information when responding to prompts. Google announced new features to the Gemini API in May, including the following: https://www.techtarget.com/searchenterpriseai/definition/Google-Gemini
Video frame extraction which lets users upload a video to generate content.
Parallel function calling, which lets users engage in more than one function call at a time.
In June 2024, Google added context caching to ensure users only have to send parts of a prompt to a model once.
Gemini 2.0- Google introduced Gemini 2.0 Flash on December 11, 2024. In an experimental preview through Vertex AI Gemini API and AI Studio. Gemini 2.0 Flash is twice the speed of 1.5 Pro and has new capabilities, such as multimodal input and output, and long context understanding. Other new features include text-to-speech capabilities for image editing and art. The new API has audio streaming applications to assist with native tool use and improved latency.
For more in depth learning of Gemini evolution you can refer to this link- https://timelines.issarice.com/wiki/Timeline_of_Google_Gemini
Basic Technical features of Google Gemini models
Model Architecture
Definition: The design of the AI model that determines how it processes and generates text.
Example: Think of it like the blueprint for building a robot. A "Transformer Decoder" is like a design that helps the robot predict and write sentences based on patterns it learned.
Parameters
Definition: The internal "settings" the model uses to make decisions and generate responses. More parameters mean better decision-making.
Example: A model with 175 billion parameters (like GPT-3) is like a chef with 175 billion recipes- it can cook almost anything you ask for.
Token Limit
Definition: The maximum amount of text the model can process in a single interaction. Tokens are chunks of words or letters.
Example: If you ask the model to summarize a 5-page document but its token limit is 2 pages it won’t be able to process the entire document.
Batch Processing
Definition: The ability to handle multiple tasks or inputs at the same time.
Example: Imagine a cashier processing 5 customers at once instead of one by one. A model with good batch processing can answer 5 different users simultaneously without delay.
Training Type
Definition: How the model is trained to understand and generate text.
Pre-trained: Trained on a large dataset before being released.
Reinforcement Learning from Human Feedback (RLHF): Further refined by humans to improve responses.
Example: Pre-trained is like a chef who learned cooking by reading books. RLHF is like a chef who improved their cooking by learning directly from customer feedback.
Few-Shot Learning
Definition: The model's ability to perform tasks after seeing only a few examples.
Example: If you show the model two examples of writing a haiku it can generate its own haikus without needing hundreds of examples.
Latency
Definition: The time it takes for the model to generate a response after receiving input.
Example: A low-latency model is like a fast typist who replies to your text immediately while a high-latency model is like a slow responder who takes minutes.
Multimodal Input
Definition: The ability to process both text and images as input.
Example: You can upload a photo of a math problem and the model (like GPT-4) can solve it by analyzing the image and generating a text response.
Context Retention
Definition: How well the model remembers previous parts of a conversation or input.
Example: If you’re chatting about your favorite movies a model with good context retention will remember your preferences and recommend relevant movies later in the chat.
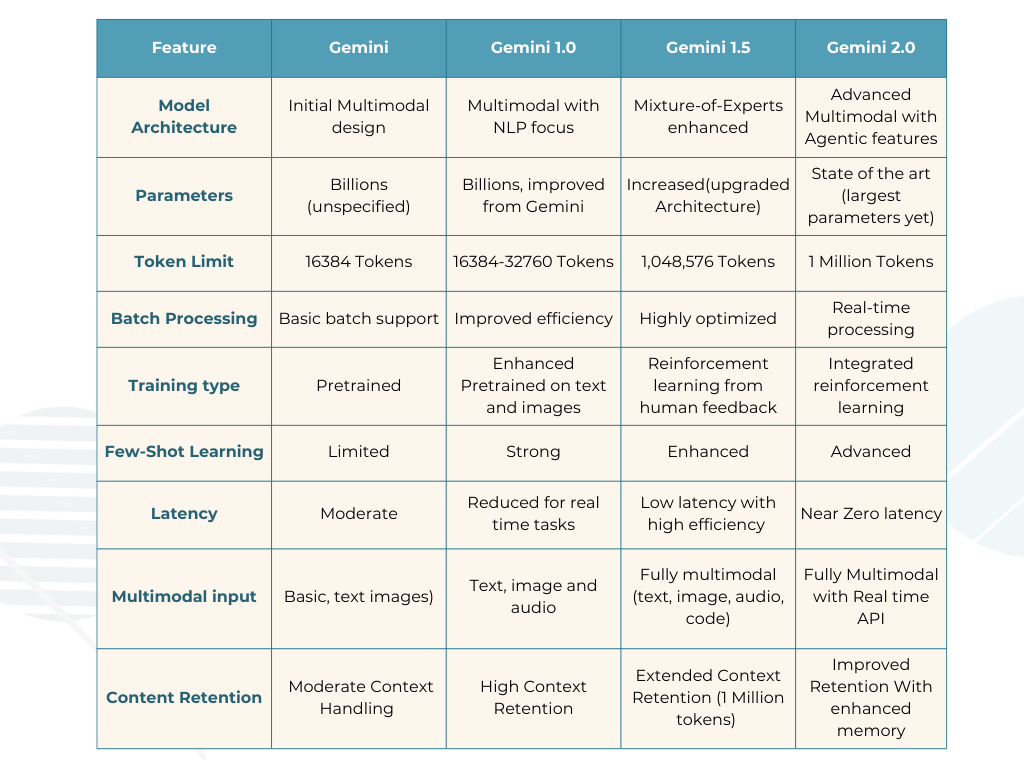
Comparison of Key technical features of Google Gemini models
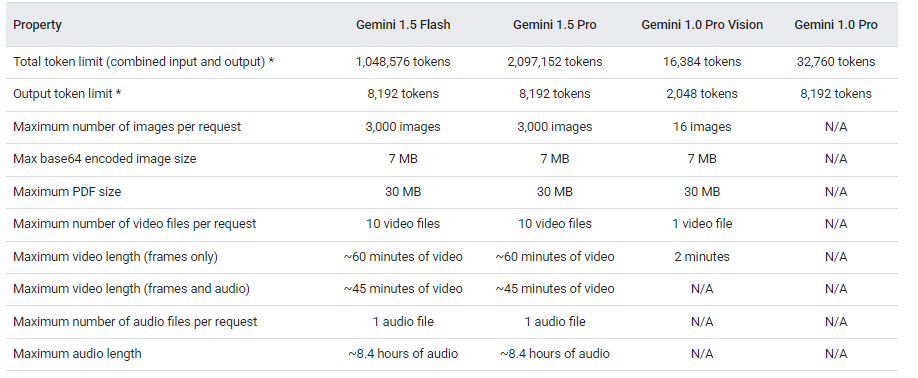
Pricing Mechanism of Gemini models

Gemini Model Suitability for App Development
Gemini 1.0
Best for: Basic multimodal capabilities, general app development involving text, image, audio or video input handling.
Why: Offers foundational multimodal input capabilities making it useful for applications requiring interactions like chatbots, image processing or content generation.
Gemini 1.5 Pro
Best for: Advanced apps involving reasoning, large-scale data processing, and complex problem-solving (e.g.- code generation tools, advanced AI assistants).
Why: Features enhanced reasoning capabilities, a higher token limit (up to 2 million) and improved efficiency, making it ideal for apps with substantial data and reasoning demands.
Gemini 1.5 Flash
Best for: Real-time apps requiring fast responses (e.g., live chat systems, gaming assistants or real-time recommendation engines).
Why: Optimized for speed and efficiency, with a focus on latency reduction. Its ability to handle up to 1 million tokens also supports moderately complex tasks without high latency.
Gemini 2.0 Flash Experimental
Best for: Cutting-edge apps with real-time multimodal interactions, such as AI-powered virtual assistants, augmented reality (AR) applications, or apps generating native images or audio.
Why: Focuses on real-time multimodal processing and native content generation making it ideal for innovative and interactive applications.
Conclusion
The evolution of Google Gemini models from Gemini 1.0 to Gemini 2.0 Flash Experimental, showcases groundbreaking advancements in generative AI having technical features like model architecture, token limit, content retention, parameters. Gemini can help in app development, depends on the complexity and purpose of the application models can be selected Gemini 1.0 for basic, for advanced reasoning and scalability Gemini 1.5 Pro excels. Real-time interactive apps benefit most from Gemini 2.0 Flash Experimental. With its multimodal prowess and adaptability Gemini redefines AI-driven app development making it a versatile tool for developers aiming to deliver superior user experiences.
References
https://timelines.issarice.com/wiki/Timeline_of_Google_Gemini
Subscribe to my newsletter
Read articles from Sulabh Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by