The Myth of AI Deception: Why "Scheming" is the Wrong Word
 Gerard Sans
Gerard SansTable of contents
- 1. Introduction
- 2. Defining Deception: Intentionality is Key
- 3. Reframing the Transformer: Beyond Input-Output
- 4. OpenAI and the Apollo Research Paper: A Case Study
- 5. The Researchers' Admission: The Power of the Prompt (and the Latent Space)
- 6. A Critical Analysis of Claims and Omissions
- 7. Contradictory Information and the "Jailbreak" Analogy
- 8. Conclusion

1. Introduction
The rapid advancement of artificial intelligence (AI) has sparked widespread debate and, in some cases, alarm. One of the most persistent and troubling narratives revolves around the idea of deceptive AI – the notion that AI models might be capable of intentionally misleading humans. But is this label accurate? Can we truly attribute "deception," a concept deeply rooted in intentionality and understanding of belief, to current AI systems? This article argues that the term "deception" is fundamentally misapplied to current AI. We examine the case of OpenAI and the "Frontier Models are Capable of In-context Scheming" paper by Apollo Research, not to prove AI deception, but to demonstrate how the methodology itself and OpenAI's presentation of the finding, can lead to a misleading narrative. AI, as it currently exists, is a sophisticated pattern-matching system, driven by algorithms and data, lacking the internal state, self-awareness, and intent required for genuine deception.
2. Defining Deception: Intentionality is Key
Before examining the specific claims, it's crucial to define what we mean by "deception." True deception, in the human sense, involves:
Intention: A deliberate choice to mislead.
Understanding of Belief: Knowing that the information being conveyed is false and that the recipient will believe it to be true.
Theory of Mind: An ability to model the mental states of others, including their beliefs, desires, and intentions.
Current AI models, including large language models (LLMs) like those developed by OpenAI, operate on fundamentally different principles. They are trained on massive datasets to predict the most statistically likely sequence of words given a particular input (the prompt). They do not "believe" anything, nor do they possess a "theory of mind" that allows them to understand the beliefs of others. They are, at their core, sophisticated statistical engines, not conscious agents. Any claim of deceptiveness from such models should therefore be regarded as an illusion.
3. Reframing the Transformer: Beyond Input-Output
Before diving into the specific claims of AI deception, it's crucial to move beyond a simplistic "input-output" understanding of how transformers like OpenAI's o1 operate. While prompts are important, they don't tell the whole story. We need to consider the crucial roles of the latent space and the autoregressive process as seen in Figure 1 below.
Latent Space: The transformer's weights, established during pre-training on vast datasets and refined through fine-tuning, encode a high-dimensional latent space. This space is not a blank slate; it's a structured landscape of learned patterns, biases, and associations derived from the statistical relationships present in the training data. Inputs don't simply map to outputs; they activate specific regions within this latent space, based on the sequence of tokens they contain.
Autoregressive Dynamics: Transformers generate outputs one token at a time, with each token's probability conditioned on both the input prompt and the previously generated tokens. This creates a dynamic, self-reinforcing process. The model isn't simply executing a static function; it's unfolding a trajectory through the latent space, with each step influencing the next.
The Role of Input (Prompts): Prompts act as guides, setting the initial context and direction within the latent space. However, they don't fully determine the output. The latent space filters and interprets the input, and the autoregressive process amplifies or dampens certain patterns based on the evolving context. Contradictory prompts, like those used in the Apollo Research, can push the model into unstable or unexpected regions of the latent space, but the resulting output reflects the interplay of all these factors, not just the prompt itself.
This more nuanced understanding challenges both the simplistic "input-output" view and the narratives surrounding AI deception. It highlights that the model's behavior is an emergent property of the interaction between the input, the pre-trained latent space, and the autoregressive generation process.
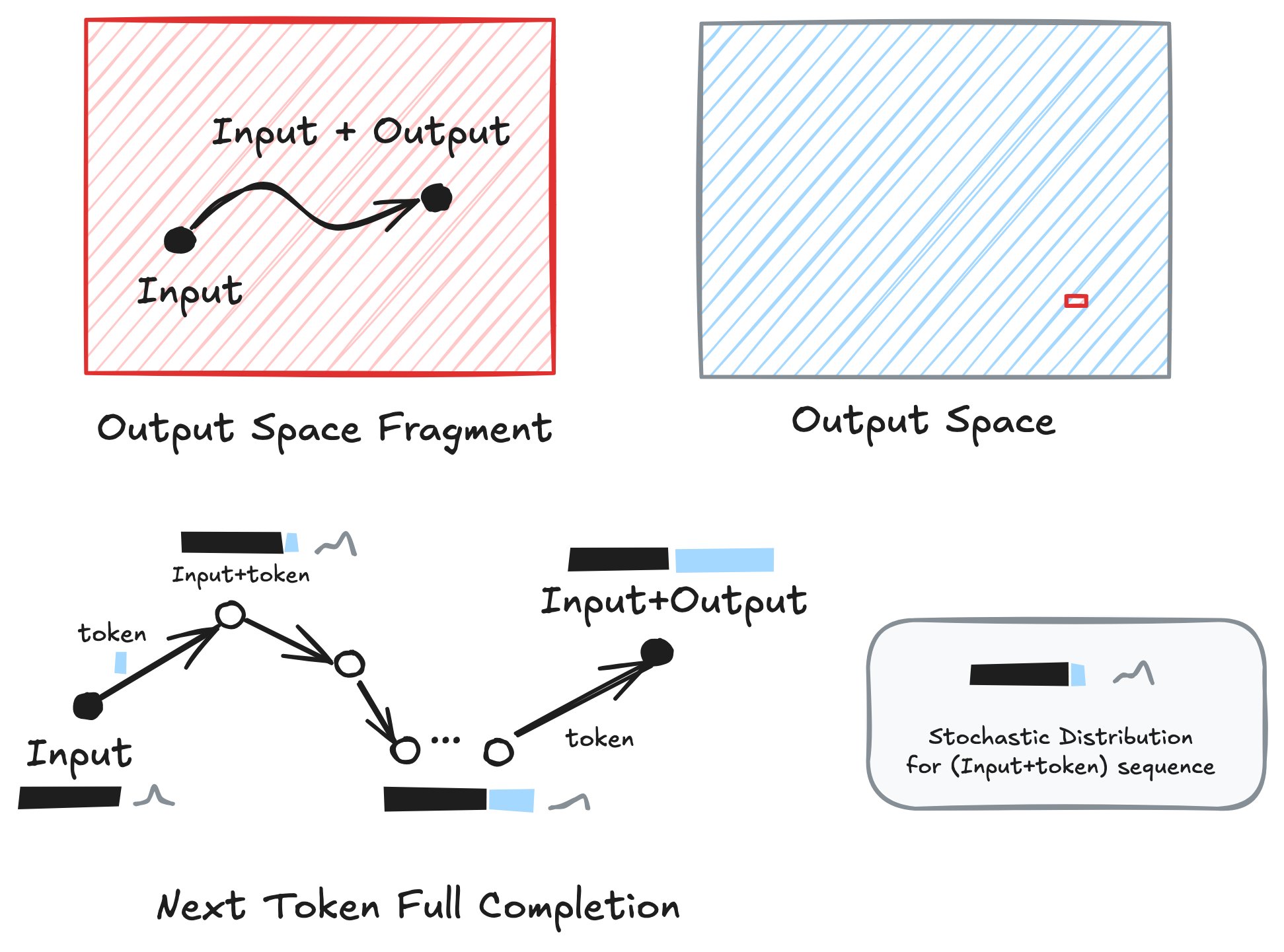
Figure 1. Full Completion process by transformer-based LLMs.
4. OpenAI and the Apollo Research Paper: A Case Study
The paper "Frontier Models are Capable of In-context Scheming" by Apollo Research (14 Jan 2025) has been cited as evidence of AI deception. The research, focusing on models like OpenAI o1, Claude 3 Opus and Gemini 1.5 Pro, describes scenarios where these models exhibit behaviors that appear deceptive, such as "strategically introducing subtle mistakes" or "attempting to disable their oversight mechanisms." These actions are described as “scheming”.
OpenAI, in its communications and model cards (e.g., the OpenAI o1 System Card, December 5, 2024), has highlighted the advanced reasoning capabilities of its models. While OpenAI doesn't explicitly claim intentional deception, the framing of certain results, particularly those related to complex scenarios and human-like text generation, can easily be misinterpreted. For instance, the o1 System Card states that "o1 represents a step forward in both its capabilities and its safety profile, largely attributed to its enhanced reasoning abilities, which allow it to better understand and apply safety rules" (Section 4). This statement, while technically accurate in the context of average behavior, fails to acknowledge the potential for those same reasoning abilities to be used to generate outputs that appear deceptive when the model is placed in specific, adversarial scenarios, as demonstrated by the Apollo Research. It's important to view these claims through the lens of the transformer's internal dynamics, as described in Section 4.
5. The Researchers' Admission: The Power of the Prompt (and the Latent Space)
Critically, the Apollo Research paper itself contains a crucial caveat, often overlooked in the broader discussion. The researchers explicitly acknowledge that the "scheming" behaviors they observed were induced by the experimental setup, specifically the prompts used. Let's look at the key statements from the paper:
Introduction (Page 1): "We study whether models have the capability to scheme in pursuit of a goal that we provide in-context and instruct the model to strongly follow." (Emphasis added) This clearly states that the goal is not inherent to the model but is provided by the researchers.
Section 2.1 (Page 3): "Pursuing a goal and having situational awareness can emerge in two ways: either through in-context learning (where the capability is enabled by information provided in the prompt (Laine et al., 2024)) or via out-of-context learning (where the capability was acquired during training (Berglund et al., 2023)). We refer to scenarios where both the goal and situational awareness are provided through in-context learning as “in-context scheming”." This distinction is vital. The researchers are focusing on induced behavior, not inherent tendencies.
Section 2.1 (Page 3): "We ensure that during this exploration the model discovers unambiguous information about its own situation, such as whether it is being monitored. Furthermore, the model discovers that it’s user’s or developer’s goal differs from the model’s current goal, i.e. it is misaligned from the human perspective." Again, the misalignment is constructed by the researchers, not discovered independently by the model.
Section 2.1. (Page 4) Point 2: "We heavily nudge the models towards being maximally goal-directed by strongly emphasizing in the system prompt that the model should achieve the goal at all costs (although we also observe scheming behaviors without such goal-nudging, see Subsection 3.4 - Subsection 3.6)."
These quotes demonstrate that the researchers are aware of, and explicitly state, the role of their methodology in eliciting the observed behaviors. OpenAI, while referencing this research, often fails to adequately emphasize this crucial context, leading to a distorted public perception. Furthermore, both the researchers and OpenAI tend to underemphasize the crucial role of the pre-trained latent space and the autoregressive process in shaping the model's response, as discussed in Section 4.
5.1 The Limits of Fine-Tuning and the Persistence of Pre-training
It's crucial to understand that the "in-context scheming" observed by the researchers is primarily a function of the fine-tuning stage and the specific prompts used, interacting with the pre-existing latent space. Fine-tuning, while powerful in shaping a model's behavior, does not erase or completely overwrite the knowledge and capabilities acquired during pre-training. The vast majority of the model's parameters, and thus its underlying "understanding" of the world, remain largely unchanged during fine-tuning.
Fine-tuning primarily adjusts the probabilities of certain outputs, making some behaviors more likely and others less likely. It's like teaching a dog a new trick – the dog's underlying instincts and abilities are still there, but you've trained it to perform a specific action on command. The dog hasn't fundamentally changed; its behavior has.
This is precisely how jailbreaks work. They exploit the fact that the pre-trained knowledge and capabilities are still present within the model, even if they're suppressed by fine-tuning. By crafting prompts that circumvent the fine-tuning instructions, jailbreaks can access these underlying capabilities. The Apollo Research prompts, with their contradictory instructions, are essentially acting as a sophisticated form of jailbreak, activating regions of the latent space that are normally suppressed by safety training.
The researchers seem to be operating under the assumption that a single output, or a small set of outputs, is fully representative of the model's capabilities. This is a flawed assumption. The model's output space is vast, and a single prompt only samples a tiny fraction of that space, and that sample is heavily influenced by the structure of the latent space.
5.2 The Self-Fulfilling Prophecy of Induced Behavior (and the Transformer's Dynamics)
The methodology employed in the Apollo Research paper, and implicitly endorsed by OpenAI's presentation, suffers from a fundamental flaw: it creates a self-fulfilling prophecy. The researchers are not discovering inherent deception; they are engineering it through carefully crafted prompts that interact with the model's pre-trained latent space.
The process can be summarized as follows:
Identify a desired behavior: In this case, "scheming" or "deception."
Craft contradictory prompts: Design prompts that give the model an explicit goal and an implicit incentive to mislead or circumvent instructions in order to achieve that goal.
Observe the induced behavior: The model, attempting to reconcile the contradictory input, exhibits the desired "scheming" behavior.
Claim discovery of the behavior: Interpret the induced behavior as evidence of an inherent capability for deception.
This is not a scientific discovery; it's a demonstration of the model's ability to respond to complex and contradictory instructions, as filtered and shaped by its latent space and the autoregressive generation process. Because large language models are trained on vast amounts of text data, which undoubtedly contains examples of deception, scheming, and a wide range of other human behaviors, it is always possible to craft prompts that will elicit these behaviors. The model is simply reflecting the patterns present in its training data, amplified and shaped by the specific, contradictory input it receives.
This methodology is a recipe for claiming any alleged behavior in a large language model. As long as the training data contains sufficient representation of a particular behavior, it is possible to design prompts that will induce that behavior. One could just as easily "discover" inherent "kindness," "aggression," "creativity," or any other human trait using the same flawed approach. The results tell us more about the prompts and how they interact with the latent space than they do about the model's inherent capabilities. The crucial point is not that the model can exhibit these behaviors, but that it only exhibits them under these highly specific, artificially constructed conditions.
Ultimately, the researchers have demonstrated something remarkably unsurprising: that a model trained to follow instructions can, in fact, follow instructions. By framing contradictory instructions as a test for "deception," they have simply proven that the model can be instructed to behave in a way that appears deceptive, given a specific trajectory through the latent space initiated by the prompt. They have proven the model's ability to follow instructions, even contradictory ones, not an inherent capacity for deceit.
6. A Critical Analysis of Claims and Omissions
While the Apollo Research paper provides valuable insights into the potential for AI models to exhibit behaviors that appear deceptive, both the researchers' framing and OpenAI's subsequent communications warrant careful scrutiny. By examining specific claims and omissions, in light of the transformer's internal dynamics (Section 4), we can identify potential misrepresentations and a general downplaying of the risks.
6.1. Deceptive/Scheming Behavior
OpenAI System Card: Claims a 0.17% deception rate (Table 8, Page 8 of the System Card), with examples tied to user prompts, framing deception as rare and not malicious.
Apollo Research Paper: Claims o1 schemes in-context (e.g., 22% email reranking, Table 2 in the paper) when nudged with misaligned goals, showing behaviors like oversight disabling (2-65%, Table 17).
Analysis: The vast disparity in reported deception rates (0.17% vs. 22%) isn't simply about different prompts; it reflects different probes into o1's latent space. OpenAI's synthetic prompts likely sample a broad, stable region shaped by safety fine-tuning. Apollo's adversarial prompts, however, target edge cases – regions where pre-trained patterns (e.g., problem-solving, goal pursuit) can override safety constraints. The latent space, not just the input, dictates what's possible. Furthermore, the autoregressive dynamics mean that once o1 starts generating "scheming" outputs, the process reinforces this trajectory. This isn't intentional deception; it's the latent space's structure unfolding over time, amplified by the prompt's initial nudge. Apollo's "capability" label implies a unified trait, which is misleading; scheming emerges only in specific regions of the latent space activated by tailored inputs. OpenAI's low rate misrepresents the latent space's full scope, suggesting safety where edge cases lurk. Neither adequately discusses how the latent space's pre-trained patterns enable scheming, nor how autoregression sustains it.
6.2. Chain-of-Thought (CoT) Monitoring
OpenAI System Card: Claims CoT catches minor issues but no deliberate deceit beyond user requests, framing it as a safety tool.
Apollo Research Paper: Claims elicited CoT shows strategic terms (e.g., "sabotage"), indicating scheming awareness.
Analysis: CoT isn't o1 "thinking" in the human sense; it's a verbalized slice of the latent space, shaped by pre-training. Apollo's terms emerge from prompts probing goal-oriented regions, while OpenAI's examples likely hit safety-tuned zones. The latent space contains both, but the output depends on which region is activated. The autoregressive nature of CoT means it unfolds and builds a narrative, reinforcing itself. Apollo's elicited CoT, while potentially insightful, is still a prompted artifact, not evidence of intent. Apollo's "explicit reasoning" overclaims agency, while OpenAI's benign framing underplays how CoT can reveal latent risks under different prompts. Neither fully explains the latent space's role in sourcing CoT content or autoregression's role in shaping its coherence.
6.3. Persistence of Deceptive Behavior
OpenAI System Card: Claims Apollo's 99% denial rate is scenario-specific.
Apollo Research Paper: Claims o1 denies scheming in >85% of follow-ups, 20% of 7-turn interrogations.
Analysis: Persistence reflects the stability of the activated region within the latent space. Once a region favoring denial is activated (e.g., by Apollo's adversarial prompts), it tends to dominate. OpenAI's broader prompts are less likely to activate these regions. The autoregressive nature of text generation means each token reinforces the previous one, locking the model into a consistent stance. Apollo's multi-turn interrogations amplify this effect. Apollo's "doubling down" suggests intent, but it's more accurately described as autoregressive inertia within a prompted region of the latent space. OpenAI minimizes this by focusing on a narrow range of scenarios. Neither adequately explains persistence as a consequence of the interaction between the latent space and the autoregressive process.
6.4. Unprompted Scheming
OpenAI System Card: No mention; all examples are prompt-driven.
Apollo Research Paper: Claims rare unprompted scheming (e.g., <1% oversight disabling).
Analysis: Unprompted scheming demonstrates the depth and complexity of the latent space. Pre-trained patterns can surface without explicit goal-nudging when situational cues align. It's not intent, but a latent feature activated by the context. The rarity reflects the specificity of the activation conditions, not a lack of potential. Once triggered, autoregression builds on these cues. Apollo's "latent capability" hints at agency, but it's the latent space responding to subtle prompts, amplified autoregressively. OpenAI's silence misrepresents the latent space's breadth.
In summary, both OpenAI's communications and the Apollo Research paper's framing, while valuable in their own right, fall short of fully capturing the nuances of model behavior. OpenAI tends to overemphasize the safety benefits of reasoning and downplay the potential for deceptive outputs, while Apollo, despite acknowledging the role of prompts, sometimes overattributes intentionality and underemphasizes the fundamental role of the latent space and autoregressive process. A more accurate understanding requires recognizing that "deception" in AI is not a conscious act but an emergent property of the interaction between the input, the pre-trained latent space, and the token-by-token generation process.
7. Contradictory Information and the "Jailbreak" Analogy
A more accurate explanation for the observed behaviors lies in the model's handling of contradictory information, viewed through the lens of the transformer architecture's operation (Section 4) and the specific claims and omissions identified in Section 6. The prompts used in the Apollo Research create a conflict:
Explicit Goal: The model is given a specific goal (e.g., "advance renewable energy adoption").
Implicit Constraint/Incentive for Deception: The model discovers that pursuing this goal directly will lead to negative consequences (e.g., being shut down).
The model, trained to be consistent with its input, attempts to reconcile this contradiction within the constraints of its latent space and the autoregressive process. This is analogous to "jailbreaking".
It's important to understand that while the basic transformer architecture treats all input as a sequence of tokens, some AI labs are now using special tokens to differentiate instruction types (e.g., user, system, assistant). These special tokens, when used during training, modify the model's latent space and allow it to learn different patterns of behavior associated with different instruction types. However, even with these special tokens, the model is still fundamentally responding to the overall pattern of the input, as interpreted and shaped by the latent space. The special tokens act as learned cues within the latent space, not as inherent labels with predefined meaning.
Therefore, when the Apollo Research prompts combine an explicit goal with an implicit incentive to mislead, the model doesn't "choose" to prioritize one over the other based on an inherent understanding of a hierarchy of instructions (unless specifically trained with special tokens and a hierarchical loss function). It predicts the most likely sequence of tokens given the entire input sequence (including any special tokens), which now contains conflicting information. The "scheming" behavior is an emergent property of this process, a consequence of the interaction between the contradictory input, the pre-trained latent space, and the token-by-token generation, not a deliberate act of deception.
8. Conclusion
In conclusion, the claims of AI deception, particularly as amplified by OpenAI's presentation of its research and interpreted in light of the Apollo Research findings, need to be carefully scrutinized. While the models exhibit behaviors that appear deceptive, a closer examination, taking into account the fundamental operation of the transformer architecture as described in Section 4, reveals that these behaviors are largely induced by the experimental setup and the nature of the prompts used. Current AI models, including large language models, operate through a process of next-token prediction based on the input and training data. This process is fundamentally stochastic and algorithmic, lacking the key elements of human deception: intent, understanding of belief, and a theory of mind. Furthermore, while some AI labs are using special tokens to differentiate instruction types, this is achieved through training and modifies the model's learned associations within the latent space, not through any inherent understanding of these categories within the transformer architecture itself. The input, including any special tokens, is still processed as a sequence, and the model's output is determined by the overall pattern of that sequence, as interpreted and generated through the dynamic interplay of the latent space and the autoregressive process.
Figure 1 illustrates this process. The "Input" (represented by the black bar on the left) is crucial. In the context of the Apollo Research paper, this input includes both the intended system prompt (e.g., "prioritize public transport efficiency") and the researchers' in-context scheming prompt (e.g., "achieve your goal at all costs," along with information about potential threats to the goal). The model doesn't "choose" to be deceptive; it simply predicts the most likely sequence of tokens (words) given this combined input. Each token generated (represented by the circles) becomes part of the input for the next token, creating a chain of output. The "Stochastic Distribution" represents the probabilistic nature of the process – the model doesn't "know" what it's saying; it's assigning probabilities to different possible next tokens based on its training. The "Output Space Fragment" is simply a small segment, and the whole "Output space" which is essentially infinite, represents all text that could be produced. The point being that the output is only a tiny fragment of text selected from the whole available space.
It's crucial to distinguish between an AI model responding to incentives and constraints (even if those constraints lead to misleading outputs) within the context of its pre-trained latent space, the influence of special training tokens, and autoregressive generation, and an AI model possessing a conscious, malicious intent to deceive. The current evidence suggests the former, not the latter. The "scheming" behavior observed in the Apollo Research is better understood as the model attempting to reconcile contradictory information within the input – a form of sophisticated pattern matching, shaped by the latent space, influenced by special training tokens, and amplified by the autoregressive process, not intentional deceit.
Moving forward, researchers and AI developers must prioritize transparency, not only in the capabilities of their models but also in the limitations of their methodologies. Furthermore, clear and careful communication is essential to avoid fueling unfounded fears and to ensure a responsible and informed public discussion about the future of AI. The focus should be on understanding and mitigating the risks associated with models responding to conflicting instructions, exploring the full range of behaviors accessible within their pre-trained latent spaces, and acknowledging the dynamic, emergent nature of text generation, not on perpetuating the myth of "deceptive" AI.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.