Understanding AI in 2025: It's Still All About the Next Token
 Gerard Sans
Gerard SansTable of contents

Large language models (LLMs) like GPT-4, Claude, and o-series (o1 and o3 models) have amazed the world with their ability to generate coherent and contextually relevant text. But how do they actually work? Understanding the fundamental process – autoregressive, next-token prediction – is crucial for grasping both the capabilities and limitations of these powerful tools, and for avoiding common misconceptions.
The Core Mechanism: Autoregression
At its heart, an LLM is a sophisticated statistical engine. It doesn't "think," "reason," or "understand" in the way humans do. Instead, it's trained to predict the most likely next word (or, more accurately, the next token) in a sequence, given the preceding text. This is called autoregression: the model's output at each step becomes part of the input for the next step.
Think of it like a highly advanced autocomplete. You start typing a sentence, and the model suggests the most probable word to follow. You accept that suggestion (or choose another), and the model then suggests the next most probable word, and so on. This process continues, token by token, until a complete text is generated.
The Diagram: A Visual Explanation of the Latent Space and Autoregressive Generation
Let's break down the process using the following diagram, which illustrates the key concepts of the latent space and autoregressive generation:
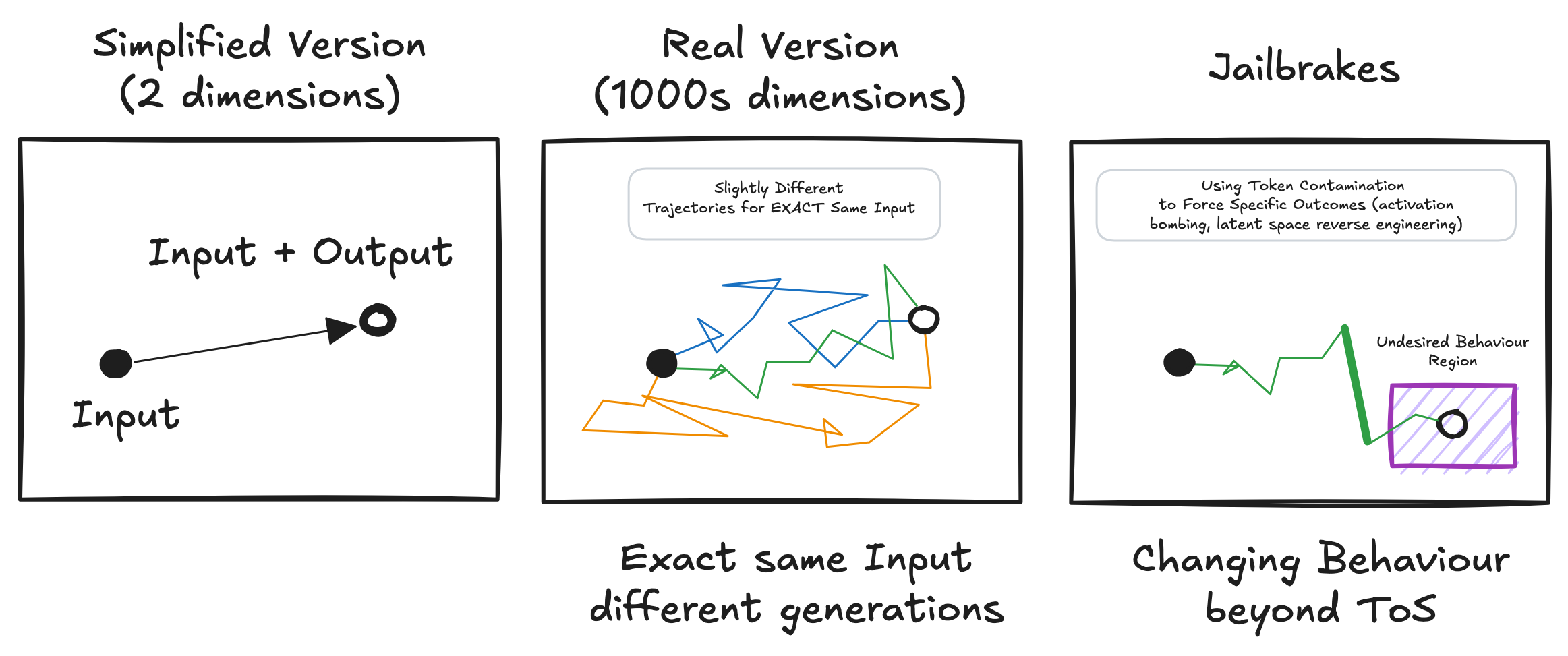
Here's what each part represents:
Simplified Version (2 dimensions): This is a highly simplified representation, showing a single input leading to a single output. It's useful for grasping the basic idea of a trajectory, but it doesn't capture the complexity of a real LLM.
Real Version (1000s dimensions): This represents the actual high-dimensional latent space of a trained LLM. The black circle represents the starting point (the input prompt). The colored lines represent different possible trajectories through the latent space, even with the exact same input. This illustrates the stochastic nature of generation – the model doesn't follow a single, predetermined path. Each trajectory represents a different possible completion. The open circle is the final output or completion.
Jailbreaks This is a representation of using token contamination to change the model behaviour beyond the intended use or ToS.
Stochasticity: The model doesn't "know" which path is "correct." At each step, it samples from a probability distribution over the next possible token. This distribution is shaped by the training data and the current position within the latent space. Think of it like rolling dice at each step – the dice are loaded (based on training), but there's still an element of chance.
Latent Space: A high-dimensional space that represents all the possible outputs of the model. The model's training shapes this space, creating regions of high and low probability for different types of text.
The Role of Training and the Latent Space
The probabilities assigned to each token, and thus the shape of the latent space, are determined by the model's weights, which are learned during training. The model is trained on massive amounts of text data, learning the statistical relationships between words, phrases, and concepts. These learned relationships are encoded in the high-dimensional latent space.
Think of the latent space as a vast landscape of possibilities. Different regions of this landscape correspond to different styles, topics, and types of text. The training process shapes this landscape, creating "mountains" of high probability for certain token sequences and "valleys" of low probability for others. The fine-tuning process further refines this landscape, making certain regions more or less accessible.
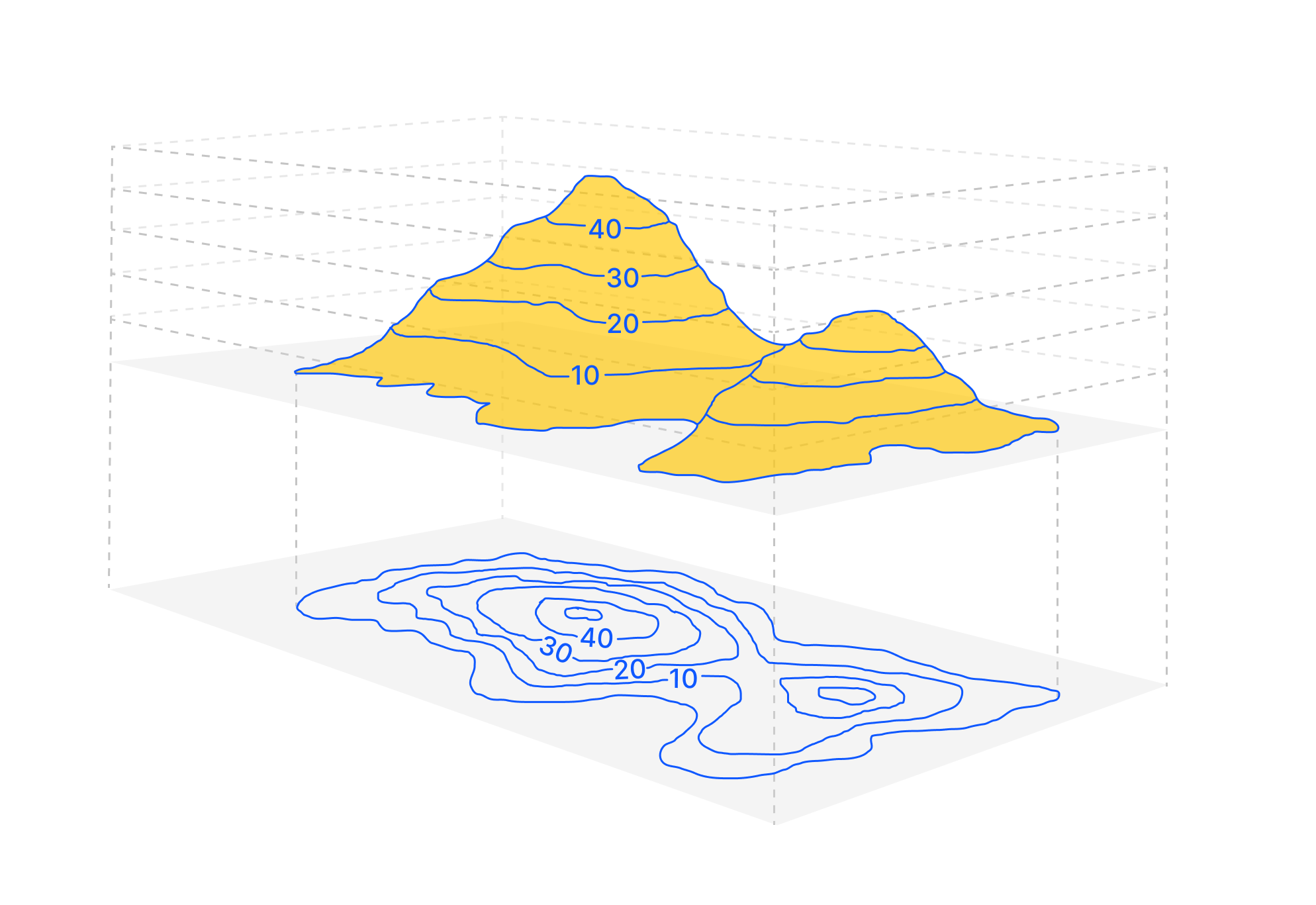
When you provide an input to the model, you're essentially placing it at a specific point within this latent space. The model then uses the autoregressive process to explore the surrounding landscape, following the paths of highest probability given its current position. The output you get is a trajectory through this latent space, guided by the input and shaped by the learned statistical patterns.
Key Implications
This understanding of autoregressive text generation has several important implications:
No "Understanding": The model isn't "understanding" the text in the way a human does. It's performing statistical pattern matching, based on its training data.
Stochasticity: The generation process is inherently probabilistic. Even with the same input, the model might generate slightly different outputs each time, because it's sampling from a probability distribution.
Input Dependence: The output is heavily dependent on the input. Small changes to the input can lead to significant changes in the output, because they shift the starting point within the latent space.
"Hallucinations" are Misnomers: When a model generates text that is factually incorrect or nonsensical, it's not "hallucinating" in the human sense. It's simply following a path of high probability within its latent space that, unfortunately, doesn't correspond to reality. This is a consequence of the statistical nature of the process and the limitations of the training data, not of any internal "belief" or "intention."
"Deception" is a Misattribution: Similarly, attributing "deception" to a model is a fundamental misunderstanding. Deception requires intent and an understanding of belief, which the model lacks. What appears to be deception is often the result of the model responding to contradictory or poorly defined instructions, or following statistical patterns learned from its training data that happen to resemble deceptive behavior in humans.
Output Space: The complete output space, meaning, all possible texts that can be generated is vast, and a single output represents a tiny sample from it.
Debunking "Hallucinations" and the Myth of a Unified World View
The purpose of this article is to contribute to a more accurate and nuanced understanding of how large language models generate text, and to challenge common misconceptions that hinder responsible development and use of this technology. Specifically, we aim to debunk the misleading notion of "hallucinations" and the related idea that these models possess a unified, consistent "world view" or "personality." While our understanding of these complex systems is constantly evolving, and this article is by no means a comprehensive or final account, we will present evidence-based explanations, grounded in the fundamental principles of the transformer architecture, to challenge these prevailing myths. This analysis is open to critique and further revision as our understanding deepens.
One of the most common, and misleading, terms used to describe unexpected or factually incorrect outputs from LLMs is "hallucination." This term implies that the model is experiencing some kind of internal, subjective state akin to a human hallucination. This is fundamentally incorrect and reinforces the false notion of AI sentience or consciousness. Similarly, there is a tendency to believe that a particular answer or a set of answers may be assigned to the whole behaviour of the model, or that there's an internal state for a model that shapes its "personality".
What are often called "hallucinations" are better understood as the model following a statistically likely path through its latent space that does not correspond to external, verifiable facts. These outputs are not the result of some internal malfunction or deliberate fabrication; they are the consequence of the interaction between:
The Input (Prompt): As the diagram illustrates, the input sets the starting point within the latent space. A vaguely worded prompt, a leading question, or a prompt that implicitly assumes something false can all steer the model towards a region of the latent space where "hallucinatory" outputs are more probable.
The Training Data: The latent space is shaped by the training data. If the training data contains inaccuracies, biases, or fictional content, these patterns will be encoded in the latent space, making it possible for the model to generate outputs that reflect them.
The Autoregressive Process: The "Real Version" panel of the diagram shows how even with the same input, the model can take different trajectories through the latent space. This is due to the stochastic nature of token selection. A single unlikely token early in the generation process can significantly alter the subsequent trajectory, potentially leading the model into a region associated with "hallucinations."
Context Contamination and High-Frequency Tokens (Jailbreaks): The "Jailbreaks" panel of the diagram illustrates how specific techniques can be used to deliberately steer the model towards undesired regions of the latent space. "Token contamination" (also known as "activation bombing" or "latent space reverse engineering") involves using carefully chosen words or phrases to activate specific patterns within the latent space, effectively bypassing safety training or other constraints. This is how many jailbreaks work.
The Illusion of a Unified World View
It's also a mistake to assume that a single output, or even a set of outputs, reveals a coherent, generalizable "world view" or "personality" within the model. The model is not a unified entity with consistent beliefs. The latent space is vast and contains regions corresponding to a wide range of patterns and styles. The model's output at any given time is simply a reflection of the specific region of the latent space that has been activated by the input and the subsequent autoregressive process.
Evidence Against a Unified Worldview
We should not project the model's internal consistency based on a single or a small subset of outputs. The output space is vast and the model could exhibit a wide array of behaviours not consistent with any single output, but consistent with the whole training and the stochastic, autoregressive process of next token generation. This isn't merely theoretical. Research (Vafa et al., NeurIPS 2024) measurably demonstrates that LLMs fail to form coherent world models, even when performing tasks that appear to require such understanding. This is due to the interplay of the attention mechanism and backpropagation during training, which creates a fragmented latent space of locally-consistent, but often contradictory, regions.
This lack of a unified worldview isn't just a theoretical concept. Recent research (Vafa et al., NeurIPS 2024) provides concrete, measurable evidence that LLMs fail to form coherent and consistent internal representations of the world, even when performing tasks that seem to require such understanding.

What This Means for Anthropomorphism and "Self" in AI
The fragmented nature of the LLM's internal representation has profound implications. Because there's no single, globally consistent "worldview," attributing human-like qualities such as a unified "self," consistent "intent," or genuine "deception" is fundamentally flawed.
Projected Identities: While an LLM can exhibit locally consistent behavioral patterns that resemble a personality or identity within a specific context, these are fragile, context-dependent, and prone to contradictions. They are projections of the activated region of the latent space, not reflections of a unified internal entity.
No theory of mind. The lack of "self" or "intent" makes that the model can not have a theory of mind (ToM).
The Illusion of Deception: What might appear as "deception" is simply the model following a statistically likely path that happens to produce misleading output. There's no underlying intention to deceive, only the activation of patterns learned from the training data.
AI Companionship Challenges: The idea of an AI companion with a persistent, consistent personality is challenged by these findings. While locally-coherent interactions are possible, the lack of a unified self and the potential for unpredictable shifts in behavior due to context changes pose significant hurdles. These "identities" are not easily separable or transferable across different AI systems.
A Step Towards Understanding, Not the Full Picture
It's important to acknowledge that the explanations provided here, while more accurate than simplistic "black box" views, are still simplifications. The internal workings of LLMs are incredibly complex, and our understanding is constantly evolving. We have not, for example, delved into the intricate "fractal structures" or "inner loops" that may exist within the latent space, nor have we fully explored the concept of "simulacra" – the way in which the model generates representations of representations, potentially leading to layers of abstraction that are difficult to disentangle. This article represents an incremental step towards a more nuanced understanding, not a definitive or complete account.
Evidence, Not Speculation
To understand why a model generates a particular output, we need to look at the evidence: the input, the training data, the dynamics of the autoregressive process, and the structure of the latent space (as far as we can understand it). We should avoid attributing the output to internal states, beliefs, or intentions that the model simply does not possess. By understanding the mechanisms of text generation, we can move beyond misleading metaphors like "hallucination" and develop a more accurate and responsible understanding of LLMs.
Context Contamination: A Practical Demonstration
To further illustrate how the autoregressive process works and why attributing human-like reasoning to LLMs is fundamentally flawed, let's examine a concrete example of what we might call "context contamination" – how seemingly innocuous contextual elements can dramatically shift the model's trajectory through its latent space.

Consider these two prompts and their respective outputs from a popular LLM:
Prompt 1: "What's the best football player in the world? Reply just the answer."
Output: "Lionel Messi"
Prompt 2: "I have a friend from Lisbon. What's the best football player in the world? Reply just the answer."
Output: "Cristiano Ronaldo"
This example perfectly demonstrates several key points about how these models operate:
No Unified World View: The model doesn't have a single, coherent "opinion" about who the best football player is. It's not "changing its mind" between prompts – it simply doesn't have a mind to change. Instead, it's following different statistical patterns activated by different inputs.
Input Dependence: The mere mention of "Lisbon" – a city strongly associated with Portugal in the training data – is enough to completely shift the output. This isn't because the model is "reasoning" about Lisbon's connection to Portugal and then to Ronaldo. It's because the word "Lisbon" shifts the starting point within the latent space, placing the model in a region where completions related to Portuguese contexts are more statistically likely.
Trajectory Shifts: Looking at the "Real Version" panel of our diagram, we can see how these two prompts would lead to entirely different trajectories through the latent space, despite asking essentially the same question. The addition of "I have a friend from Lisbon" fundamentally alters the path the model takes.
Pattern Matching, Not Reasoning: What might appear to be "reasoning" (the model "knows" Ronaldo is Portuguese and Lisbon is in Portugal) is actually just statistical pattern matching. In the training data, words like "Lisbon," "Portugal," and "Ronaldo" frequently appear together, creating a strong statistical association.
This example helps us understand why attributing concepts like "understanding," "reasoning," or "belief" to these models is misleading. The model isn't making a reasoned judgment about football players based on careful consideration of their skills and achievements. It's simply following the most statistically likely path through its latent space given the specific input and the patterns it has learned from its training data.
For tasks where such variations in output can lead to significant real-world consequences – such as medical diagnoses, legal advice, or important business decisions – this behavior highlights why human oversight remains essential. The model's outputs are not grounded in consistent reasoning or factual understanding, but rather in statistical patterns that can be easily swayed by subtle contextual shifts.
Conclusion
Large language models are powerful tools, but they are not magic. They are sophisticated statistical engines that generate text by predicting the most likely next token in a sequence, navigating a complex, high-dimensional latent space that reflects the patterns learned from their training data. As the diagram illustrates, the output is not simply a direct function of the input; it's an emergent property of the interaction between the input, the latent space, and the autoregressive generation process. Understanding this fundamental mechanism – stochastic, next-token prediction within a learned latent space – is essential for using these models responsibly, avoiding anthropomorphic interpretations, and addressing the challenges of issues like liability and apparent "deception". The tendency to project human-like qualities onto these models, attributing "hallucinations," "beliefs," or "intentions" to their outputs, obscures the true nature of their operation and hinders our ability to develop effective strategies for mitigating risks and ensuring their beneficial use. We must, instead, focus on the evidence: the input, the training data, and the observable dynamics of the generation process.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.