Exploring Retrieval-Augmented Generation (RAG): Understanding, Evaluating, and Applying the Hybrid AI Framework
 NonStop io Technologies
NonStop io Technologies
What is RAG?
RAG Stands For Retrieval-Augmented Generation. RAG is an AI framework in Natural language processing (NLP) that combines the two approaches that is Retrieval-base and Generation-base approaches to produce more accurate and correct response.
Goals of RAG:
Retrieve Relevant Information:
By retrieving relevant documents or data from an external knowledge base, RAG aims to provide more accurate and contextually appropriate responses. This helps in addressing queries or generating content that requires specific or up-to-date information.
Generate Coherent Responses:
The generative model processes the retrieved information to produce coherent and contextually rich responses. This combination helps in generating responses that are not only accurate but also fluent and engaging.
Provide More Satisfying Interactions:
By combining retrieval and generation, RAG aims to deliver responses that are not only accurate but also contextually appropriate, improving the overall user experience in various applications.
Components of RAG
Retrieval-Based Models
Generative-Based Models
Retrieval-Based Models :
Retrieval-based models are a class of natural language processing (NLP) models designed to retrieve relevant information from a large database in response to a input. They focus on finding and presenting existing information rather than generating new content.
Processes of retrieval model
Query Input: User provides a query
Database Search: Model searches a large collection of documents
Relevance Scoring: Scores documents based on relevance to the query
Result Extraction: Extracts the top-scoring, most relevant information
Strengths:
High Precision: Can return highly relevant information when the query is well-defined.
Efficiency: Often faster and more scalable for retrieval tasks compared to generative models.
Limitations:
Lack of Creativity: Can’t create new content or give detailed answers beyond the information it retrieves.
Dependency on Data Quality: How well it performs depends a lot on how good and complete the retrieved information is.
Generative-Based Models:
Generative-based models are a class of natural language processing (NLP) models designed to generate new content or responses based on input data. Unlike retrieval-based models, which fetch and present existing information, generative models create new text, making them useful for tasks that require creativity, context understanding, or complex language generation
Process of Generative Model
Input Analysis: Model analyzes the given input text
Context Understanding: Understands the context and intent behind the input
Text Generation: Generates a coherent and relevant response
Output Delivery: Provides the generated text as a response.
Strengths:
Creativity: Can create new and varied content, not just repeat what’s already known.
Contextual Understanding: Can produce text that makes sense and stays relevant over long passages.
Limitations:
Resource Intensive: Needs a lot of computing power to train and use.
Control and Accuracy: Might sometimes give off-topic or confusing responses if not carefully managed.
RAG Architecture and Workflow:
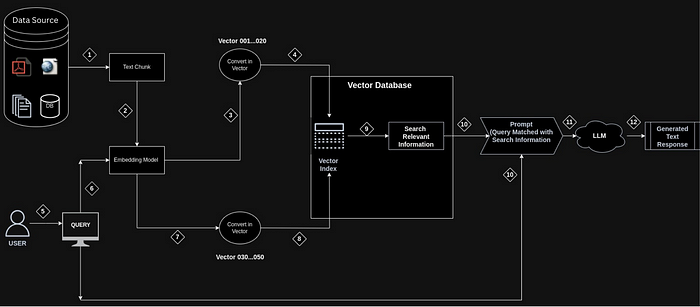
Diverse Data Sources
RAG system incorporates a wide range of data sources, including PDFs, URLs, databases, and documents. All this information is stored in a large, centralized database, forming the foundation of our system. This diverse collection ensures that the system can provide comprehensive answers by tapping into a broad knowledge base.Text Chunking
To manage vast amount of data efficiently, we employ a technique called text chunking. Data from various sources is split into small, manageable chunks. This step is critical as it improves search efficiency and makes data easier to manage. By breaking down information into chunks, we can process and retrieve data more effectively.Embedding and Vectorization
Once the text is chunked, each chunk is processed by an embedding model. This model converts the text chunks into numerical representations known as vectors. These vectors capture the essence of the text in a format that is suitable for computational processing.Vector Indexing
The generated vectors are then stored in a vector index and database. Each vector corresponds to a specific text chunk, allowing for precise mapping and retrieval. This indexing system facilitates quick and accurate access to the relevant data when needed.Query Processing
When a user submits a query, the system processes it similarly to the text chunks. The query is converted into a vector by the embedding model. This query vector represents the user’s request in a numerical form.Vector Comparison and Retrieval
The query vector is then compared with the stored vectors in the vector database. This comparison helps identify the most relevant information that matches the user’s query. The vector database retrieves the information that closely aligns with the query vector, ensuring that the retrieved data is highly relevant.Generating Detailed Prompts
The retrieved information is combined with the original query to create a detailed prompt. This prompt is then sent to a language model.Language Model Response
The language model processes the detailed prompt to generate a text response. This response is crafted to be clear, relevant, and comprehensive, addressing the user’s query effectively.Providing the Final Response
Finally, the generated text response is presented to the user. This response provides accurate and thorough information, ensuring that users receive the answers they are looking for.
Benefits of RAG
Improved Accuracy: RAG models provide more accurate responses by accessing up-to-date information.
Up-to-date Knowledge: By retrieving information from a dynamic database, RAG models can provide more current information compared to models that rely solely on pre-trained data.
Access to External Knowledge: Allows models to pull information from external databases and documents.
Scalability: RAG models efficiently handle large datasets and dynamic information.
Enhanced User Experience: By providing more accurate, relevant, and coherent responses, RAG models significantly improve the overall user experience. This is particularly beneficial for applications like virtual assistants, chatbots, and customer support systems.
Versatility: RAG can be applied across various domains, from customer support to academic research, enhancing the utility of AI systems. Recordation’s, chatbot, Q&A.
Reduced Hallucinations: A common issue with traditional AI models is the generation of incorrect or redundant information. RAG models help mitigate this by reducing the incidence of such hallucinations, leading to more reliable outputs.
Use Cases Of RAG
1.Healthcare:
RAG can greatly improve healthcare by enhancing medical diagnostics, patient interactions, and research. It combines extensive medical knowledge with patient data to offer more accurate and personalized treatment suggestions. For example, a RAG system might help doctors by pulling up relevant case studies and research papers, summarizing them, or suggesting possible diagnoses based on a patient’s symptoms and medical history.
Example: Imagine a medical assistant tool that helps doctors by summarizing the latest research on a specific illness. If a doctor is treating a rare disease, the tool could quickly pull up recent studies and guidelines to help in making informed decisions.
2.Education: In education, RAG can make learning more personalized and efficient. It can create customized educational materials, give instant feedback to students, and explain complex topics in detail. This personalized approach makes sure that learning content is relevant and engaging for each student.
Example: Think of a homework help app that uses RAG to provide students with tailored explanations and extra practice problems based on what they’re struggling with. If a student has trouble with algebra, the app could pull up relevant practice questions and step-by-step guides.
Also, Rag used in various domain:
3. Human Resources
4. E-Commerce
5. Customer Support
6. Finance
7. Travelling
8. Sales & Marketing
9. Content Creation etc.
Evaluation of RAG
Evaluating Retrieval-Augmented Generation (RAG) involves assessing how effectively the model combines information retrieval with text generation to produce accurate, relevant, and useful outputs.
Here’s a simplified overview of the evaluation process:
Positive Testing:
Definition — The objective here is to validate that the system responds accurately to correct or matching questions.
Method — Compare the generated output with a set of predefined positive examples. Use metrics like the percentage of responses categorized as positive or user satisfaction scores to quantify positive evaluation.
Negative Testing:
Definition — The objective is to find out how well the system handles irrelevant or misleading queries.
Method — Compare the generated output with known negative examples. Use metrics like the percentage of responses categorized as negative, error rates, or user complaints to quantify negative evaluation.
User Perspective:
Definition — The user perspective evaluates how the RAG system impacts the end-user experience, focusing on usability, satisfaction, and practical benefits from the user’s point of view.
Method — Collect and analyze user feedback, surveys, or ratings to understand user satisfaction and experiences.
Accuracy:
Definition — Measures how correctly the RAG model retrieves and generates information based on the input query.
Method — Compare the generated output with known correct answers or a set of gold-standard responses. Use metrics like Precision, Recall, and F1 Score to quantify accuracy.
Consistency:
Definition — Checks whether the model provides consistent responses for similar queries.
Method — Evaluate if the model generates similar answers when presented with variations of the same query, ensuring reliability in its outputs.
Fluency:
Definition — The naturalness and readability of the generated text.
Evaluation — Assess if the text reads smoothly and is free of grammatical errors. This can involve human reviewers or automated fluency metrics.
Robustness:
Definition — Assesses how well the model performs under various conditions, such as different types of queries or noisy input.
Method -Test the model with a diverse set of queries and inputs, including edge cases, to see how well it handles different scenarios and maintains performance.
Efficiency:
Definition — Measures how quickly and resource-efficiently the RAG model retrieves information and generates text.
Method — Evaluate the response time and computational resources required by the model. This can include measuring latency and resource usage during the retrieval and generation processes.
Relevance:
Definition — Assesses whether the information retrieved and the generated content are relevant to the user’s query or needs.
Method — Evaluate how well the retrieved documents and the generated text meet the specific requirements of the query. This can involve human judgment or relevance scoring systems.
Conclusion :
Retrieval-Augmented Generation (RAG) combines the strengths of information retrieval and text generation to deliver accurate, contextually relevant responses. By leveraging external knowledge sources and generating coherent content, RAG enhances user experience and decision-making across various fields. Its ability to handle diverse data and generate precise responses makes it a powerful tool for applications in customer support, healthcare, and beyond.
Subscribe to my newsletter
Read articles from NonStop io Technologies directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
NonStop io Technologies
NonStop io Technologies
Product Development as an Expertise Since 2015 Founded in August 2015, we are a USA-based Bespoke Engineering Studio providing Product Development as an Expertise. With 80+ satisfied clients worldwide, we serve startups and enterprises across San Francisco, Seattle, New York, London, Pune, Bangalore, Tokyo and other prominent technology hubs.