Add, Hide and Remove Layers in PDF with Python [Quick Guide]
 Casie Liu
Casie Liu
Managing a PDF with text, images, charts, and notes can be challenging. Organizing these elements into layers allows users to show or hide content as needed, making the document more interactive and easier to navigate. Instead of manually handling PDF layers, Python provides a more efficient solution. In this article, we’ll explore how to use Python to add, hide, and remove layers in PDF documents, helping you create well-structured, clear, and dynamic PDFs.
Add a New Layer to a PDF with Python
Before we start adding layers, we need the right tool. Spire.PDF for Python is a powerful library that simplifies PDF processing, allowing us to automate tasks like finding and highlighting text, and even converting PDFs to Excel. In the following steps, we’ll use Spire.PDF for Python to demonstrate how to create and manage layers efficiently.
Steps to add a new layer to a PDF file:
Create a PdfDocument object.
Load a PDF document from files using the PdfDcoument.LoadFromFile() method.
Create a layer using PdfDocument.Layers.AddLayer() method.
Get a certain page through the PdfDocument.Pages[] property.
Create a canvas for the layer based on the page with the PdfLayer.CreateGraphics() method.
Draw text on the canvas using the PdfCanvas.DrawString() method.
Save the modified PDF document as a new file through the PdfDocument.SaveToFile() method.
Here is the code example of adding a new layer with “DO NOT COPY” to a PDF document:
from spire.pdf.common import *
from spire.pdf import *
def AddLayerWatermark(doc):
# Create a layer named "Watermark"
layer = doc.Layers.AddLayer("Watermark")
# Create a font
font = PdfTrueTypeFont("Bodoni MT Black", 50.0, 1, True)
# Specify watermark text
watermarkText = "DO NOT COPY"
# Get text size
fontSize = font.MeasureString(watermarkText)
# Get page count
pageCount = doc.Pages.Count
# Loop through the pages
for i in range(0, pageCount):
# Get a specific page
page = doc.Pages[i]
# Create canvas for layer
canvas = layer.CreateGraphics(page.Canvas)
# Draw sting on the graphics
canvas.DrawString(watermarkText, font, PdfBrushes.get_Gray(), (canvas.Size.Width - fontSize.Width)/2, (canvas.Size.Height - fontSize.Height)/2 )
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("/test.pdf")
# Invoke AddLayerWatermark method to add a layer
AddLayerWatermark(doc)
# Save to file
doc.SaveToFile("/AddLayer.pdf", FileFormat.PDF)
doc.Close()
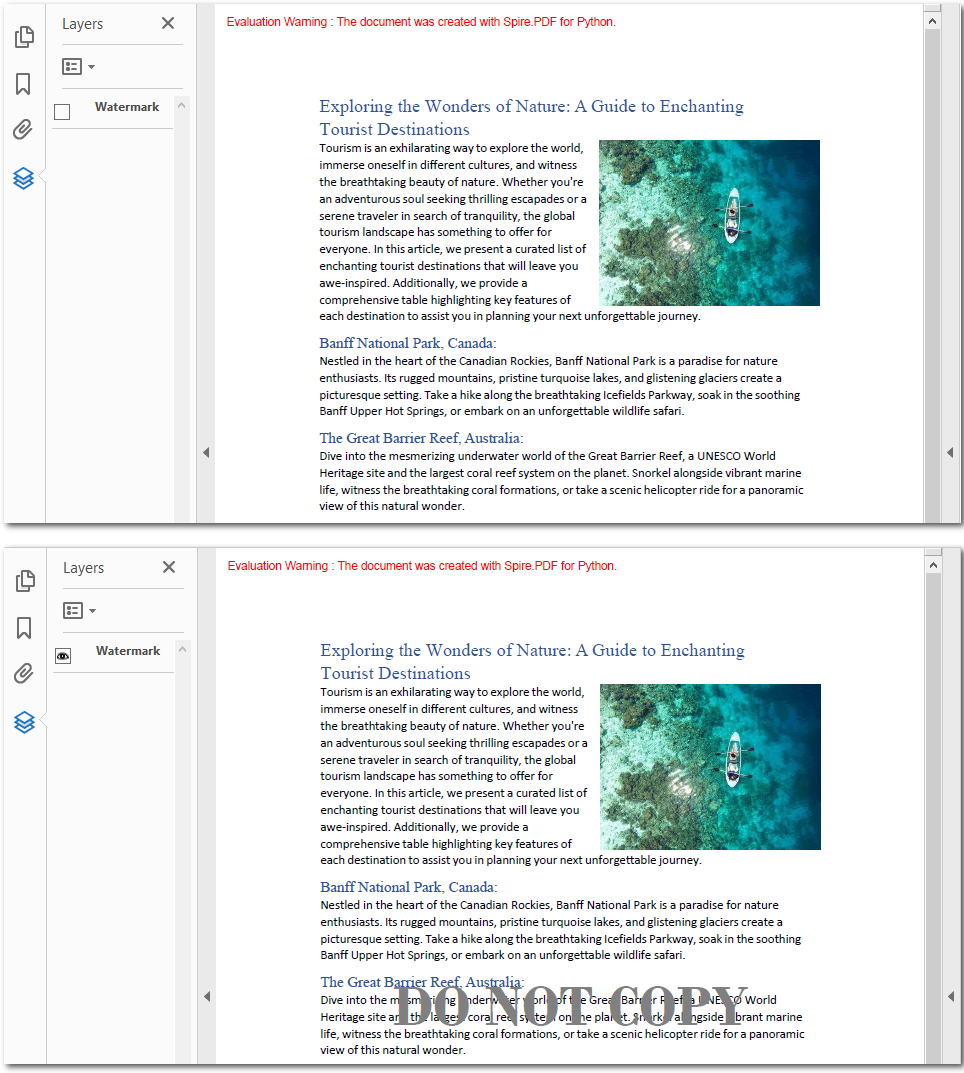
How to Hide Layers in PDF Documents Using Python
When multiple elements are stacked in a PDF, they can sometimes interfere with readability. For example, watermarks may obscure text, or cover important charts. In such cases, hiding specific layers can improve the viewing experience without compromising the document’s integrity. Let's explore the steps to achieve this.
Steps to hide layers in PDF documents:
Create an object of the PdfDocument class.
Read a source PDF file from the local storage using the PdfDocument.LoadFromFile() method.
Set the visibility of a certain layer through the PdfDocument.Layers[].Visibility property.
Save the resulting PDF document.
The Python example below shows how to hide the first layer in a PDF document:
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("/AddLayer.pdf")
# Hide a layer by setting the visibility to off
doc.Layers[0].Visibility = PdfVisibility.Off
# Save to file
doc.SaveToFile("/HideLayer.pdf", FileFormat.PDF)
doc.Close()
How to Remove Layers in PDF with Python
If a PDF document is already well-structured and highly readable, or if you want to simplify its content, you can remove unnecessary layers. Using the PdfDocument.Layers.RemoveLayer() method, you can delete any layer by specifying its name. Below are the detailed steps and code examples—let’s take a look.
Steps to remove layers in PDF documents:
Create an instance of the PdfDocument class.
Load a PDF document with layers using the PdfDocument.LoadFromFile() method.
Get a certain layer through the PdfDocument.Layers[] property.
Remove the unneeded layer with the PdfDocument.Layers.RemoveLayer() method.
Save the updated PDF file.
The following code example shows how to remove a layer by its name:
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("/AddLayer.pdf")
# Delete the specific layer
doc.Layers.RemoveLayer(doc.Layers[0].Name)
# Save to file
doc.SaveToFile("/RemoveLayer.pdf", FileFormat.PDF)
doc.Close()
To Wrap Up
This page covers everything about PDF layers, including how to add, hide, and remove them. To ensure clarity, it provides step-by-step instructions along with code examples. Try the solutions above and start managing your PDF layers with ease!
Subscribe to my newsletter
Read articles from Casie Liu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by