APEX: Integration Playground - Hashnode
 Sydney Nurse
Sydney Nurse
When I started blogging I used a single platform and service, I was not actually concerned with readers or followers, it was just for me, a journal or rant of the day.
In today’s world, content creators are seeking to share and grow a user base connecting with a set of followers across multiple platforms. I have chosen Hashnode over Medium or Wordpress as my main service to create my content and LinkedIn to reach my community.
As interest to re-share came in I was asked about other services such as X or Bluesky. I am not a short content consumer and struggle with messaging or chat services but when an APEX Developer asks about such things then my interest peaks. A few members have at least opened accounts on Bluesky and slowly sharing content.
Marc Sewtz → @msewtz.bsky.social
Scott Spendolini → @spendolini.blog
Patrick Wolf → @patrick-wolf.bsky.social
Daniel Hochleitner → @dani3lsun.bsky.social
Carsten Czarski → @cczarski.bsky.social
Toufiq Mohammed → @toufiqmohammed.bsky.social
ORDS: Jeff Smith → @thatjeffsmith.com
Database: Connor McDonald → @connormcd.bsky.social
About this Post
As mentioned I have selected Hashnode and have joined the above development team members on Bluesky, Sydney Nurse → @synuora.bsky.social
I am however abhor duplicating efforts and a lazy person by nature. Hashnode provides basic sharing capabilities to services like X(Twitter), LinkedIn, Reddit but not to all platforms, so integration is key to extending my reach. Hashnode does support adding a Social to Bluesky but the Blog Post page does not a quick link for it.
In this post I will take the first steps in automating re-posting across different platform services that are not directly supported.
A little bit about GraphQL
Hashnode has a set of public APIs implemented a GraphQL which is not natively supported by Oracle APEX yet. I found the top paragraph by Amazon on What’s the Difference Between GraphQL and REST? and the longer illustrated example on How To GraphQL, GraphQL vs. REST - A Comparison insightful but the best impartial write up was on Postman by Gbadebo Bello article GraphQL vs. REST.
For me GraphQL vs. REST boils down to these points:
REST uses HTTP Methods for Create, Read, Update & Delete (CRUD) operations and uses standard HTTP Status Codes.
GraphQL operations are submitted via HTTP POST requests and always responds with HTTP 200 even if errors occur for invalid requests.
Multiple REST requests must be submitted to work with business objects and operation types.
A single flexible request is submitted to work with business objects and operation types.
These are all mute points for me as a consumer, I only need to understand the request structure and operation HTTP method, which is a POST.
Hashnode GraphQL APIs
The Hashnode Public API is a GraphQL API that allows you to interact with Hashnode through a single GraphQL endpoint (https://gql.hashnode.com), which only accepts POST requests.
The documentation states that almost all queries can be accessed without any authentication mechanism and only some sensitive fields need authentication but all mutations need an authentication header.
I’ll only be retrieving Publications or Posts which are already public, so no authentication is required. If you wish to alter or create posts via the API then generate a Personal Access Token to access the APIs.
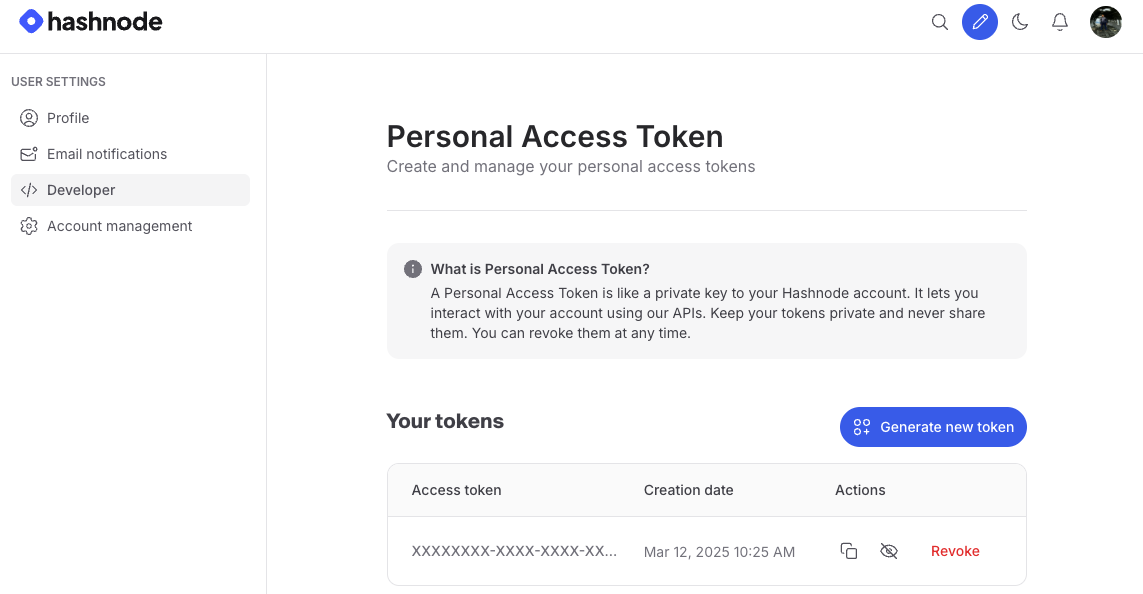
Add this as the Authorization Header parameter
declare
l_personal_token varchar2(4000)
begin
apex_web_service.g_request_headers.delete();
apex_web_service.g_request_headers(1).name := 'Content-Type';
apex_web_service.g_request_headers(1).value := 'application/json';
apex_web_service.g_request_headers(2).name := 'Authorization';
apex_web_service.g_request_headers(2).value := 'Bearer ' || l_personal_token;
end;
Though GraphQL appears to be JSON, it certainly is not as it does not adhere to a key:value structure. The request structure defines the expected results for queries based on the providers defined types.
The Query defines the return structure of attributes to return, while the Mutation is a bit of a mixed bag, defining the input as variables but also requires a set of attributes for the query to return.
Reading Publication & Posts
Publications
A Publication is basically the Blog, the container for related objects like Posts. Each Publication has several attributes, like it’s title, description, a unique URL and most importantly owner and author.
Let’s get some of the publication’s details
declare
l_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_response clob;
begin
l_body.put('query','{
publication(host: "synuora.hashnode.dev"){
id
title
descriptionSEO
author{
id
name
username
}
about{
text
}
url
links {
github
hashnode
linkedin
bluesky
}
}}');
l_response := apex_web_service.make_rest_request(
p_url => 'https://gql.hashnode.com',
p_http_method => 'POST',
p_body => l_body.to_string
);
DBMS_OUTPUT.PUT_LINE(l_body.to_string);
DBMS_OUTPUT.PUT_LINE(l_response);
end;
Breaking Down the Request Body
As mentioned a publication has several attributes, some of which are simple Strings while others are defined types, like author which is a User type, about which is a Content type or links which is a PublicationLinks type.
| Field Name | Description |
id - ID! | The ID of the publication. |
title - String! | The title of the publication. Title is used as logo if logo is not provided. |
descriptionSEO - String | The description of the publication, used in og:description meta tag. Fall backs to Publication.about.text if no SEO description is provided. |
about - Content | The about section of the publication. |
url - String! | The domain of the publication. Used to access publication. Example https://johndoe.com |
author - User! | The author who owns the publication. |
links - PublicationLinks | Links to the publication's social media profiles. |
-- Body
l_body.put('query','{
publication(host: "synuora.hashnode.dev"){
ID
title
descriptionSEO
author{
id
name
username
}
about{
text
}
url
links {
github
hashnode
linkedin
bluesky
}
}}');
-- Response
{"errors":[{"message":"Cannot query field \"ID\" on type \"Publication\". Did you mean \"id\"?","locations":[{"line":1,"column":44}],"extensions":{"code":"GRAPHQL_VALIDATION_FAILED"}}]}
The Body text includes all of the attributes that I wish to query. For defined types, I must include the attributes that I wish to retrieve as well.
Correct Case
-- Body
l_body.put('query','{
publication(host: "synuora.hashnode.dev"){
id
title
descriptionSEO
author{
id
name
username
}
about{
text
}
url
links {
github
hashnode
linkedin
bluesky
}
}}');
Response
{
"data":{
"publication":{
"id":"66d1c4ddf3a6f8cf7f1c7a67",
"title":"to_clob(hands_on.experience)",
"descriptionSEO":"I strongly believe that use cases and solutions are typically not standalone, so I am sharing the experience I gain working hands on with APEX.\n",
"author":{
"id":"66d1c4881eb0af5874c2cfc0",
"name":"Sydney Nurse",
"username":"SyNuOra"
},
"about":{
"text":"I strongly believe that use cases and solutions are typically not standalone, so I am sharing the experience I gain working hands on with APEX.\n"
},
"url":"https://synuora.hashnode.dev",
"links":{
"github":"https://github.com/SyNuOra",
"hashnode":"https://hashnode.com/@SyNuOra",
"linkedin":"https://www.linkedin.com/in/sydneynurse",
"bluesky":null
}
}
}
}
Posts
One of the benefits of GraphQL is that only a single request needs to be made for related business objects. A simple extension to the Request Body to include Posts is all that is needed.
Back to the documentation!
| Field Name | Description |
id - ID! | The ID of the publication. |
title - String! | The title of the publication. Title is used as logo if logo is not provided. |
descriptionSEO - String | The description of the publication, used in og:description meta tag. Fall backs to Publication.about.text if no SEO description is provided. |
about - Content | The about section of the publication. |
url - String! | The domain of the publication. Used to access publication. Example https://johndoe.com |
author - User! | The author who owns the publication. |
links - PublicationLinks | Links to the publication's social media profiles. |
posts - PublicationPostConnection! | Returns the list of posts in the publication. |
Argumentsfirst - Int!The number of posts to return.after - StringA cursor to the last item in the previous page.filter - PublicationPostConnectionFilterThe filters to be applied to the post list. |
Under the publication Post connections I need to go down another view levels
PublicationPostConnection
| Field Name | Description |
edges - [PostEdge!]! | A list of edges containing Post information |
PostEdge
| Field Name | Description |
node - Post! | The node holding the Post information |
cursor - String! | A cursor for use in pagination. |
Post
| Field Name | Description |
id - ID! | The ID of the post. Used to uniquely identify the post. |
title - String! | The title of the post. |
subtitle - String | The subtitle of the post. Subtitle is a short description of the post which is also used in SEO if meta tags are not provided. |
url - String! | Complete URL of the post including the domain name. Example - https://johndoe.com/my-post-slug |
brief - String! | Brief is a short description of the post extracted from the content of the post. It's 250 characters long sanitized string. |
publishedAt - DateTime! | The date and time the post was published. |
declare
l_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_response clob;
begin
l_body.put('query','{
publication(host: "synuora.hashnode.dev"){
id
title
descriptionSEO
author {
id
name
username
}
about {
text
}
url
links {
github
hashnode
linkedin
bluesky
}
posts(first: 50) {
edges {
node {
id
title
brief
url
publishedAt
}
}
}
}}');
l_response := apex_web_service.make_rest_request(
p_url => 'https://gql.hashnode.com',
p_http_method => 'POST',
p_body => l_body.to_string
);
DBMS_OUTPUT.PUT_LINE(l_body.to_string);
DBMS_OUTPUT.PUT_LINE(l_response);
end;
Response
{
"data":{
"publication":{
"id":"66d1c4ddf3a6f8cf7f1c7a67",
"title":"to_clob(hands_on.experience)",
"descriptionSEO":"I strongly believe that use cases and solutions are typically not standalone, so I am sharing the experience I gain working hands on with APEX.\n",
"author":{
"id":"66d1c4881eb0af5874c2cfc0",
"name":"Sydney Nurse",
"username":"SyNuOra"
},
"about":{
"text":"I strongly believe that use cases and solutions are typically not standalone, so I am sharing the experience I gain working hands on with APEX.\n"
},
"url":"https://synuora.hashnode.dev",
"links":{
"github":"https://github.com/SyNuOra",
"hashnode":"https://hashnode.com/@SyNuOra",
"linkedin":"https://www.linkedin.com/in/sydneynurse",
"bluesky":null
},
"posts":{
"edges":[{
"node":{
"id":"67d47289f39543089cb8889d",
"title":"APEX: Integration Playground - Adobe PDF Services",
"subtitle":"Creating, Extracting, Retrieving PDFs with Adobe PDF Services from APEX",
"brief":"Many of us are leveraging various APIs, REST, AI services to generate text, gain a better understanding of content and having real data driven conversations with business data and content.\nIn this, hopefully first of many, post I start to experiment ...",
"url":"https://synuora.hashnode.dev/apex-integration-playground-adobe-pdf-services",
"publishedAt":"2025-03-14T18:16:41.540Z"
}
},
{...}
}]
}
}
}
}
Wrestling JSON or APEX 24.2 JSON Sources?
Save your response and plan your next steps. I have saved mine to a temporary table for now, not feeling like implementing merge functionality at the moment.
This gives me an opportunity to start exploring JSON Sources over parsing the responses myself.
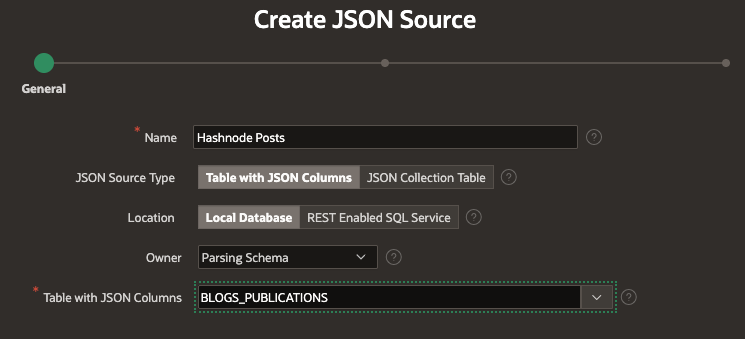
You can define a JSON Source using the Local Database and after picking the table and column to use, Oracle APEX either determines the data profile from the actual data, or from an uploaded JSON Schema file.
Select the Source
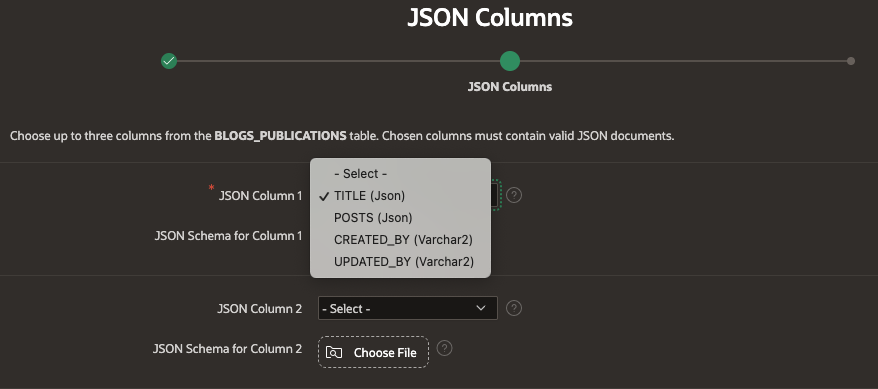
Select the JSON columns containing JSON Documents
View the parsed JSON documents Data Profile
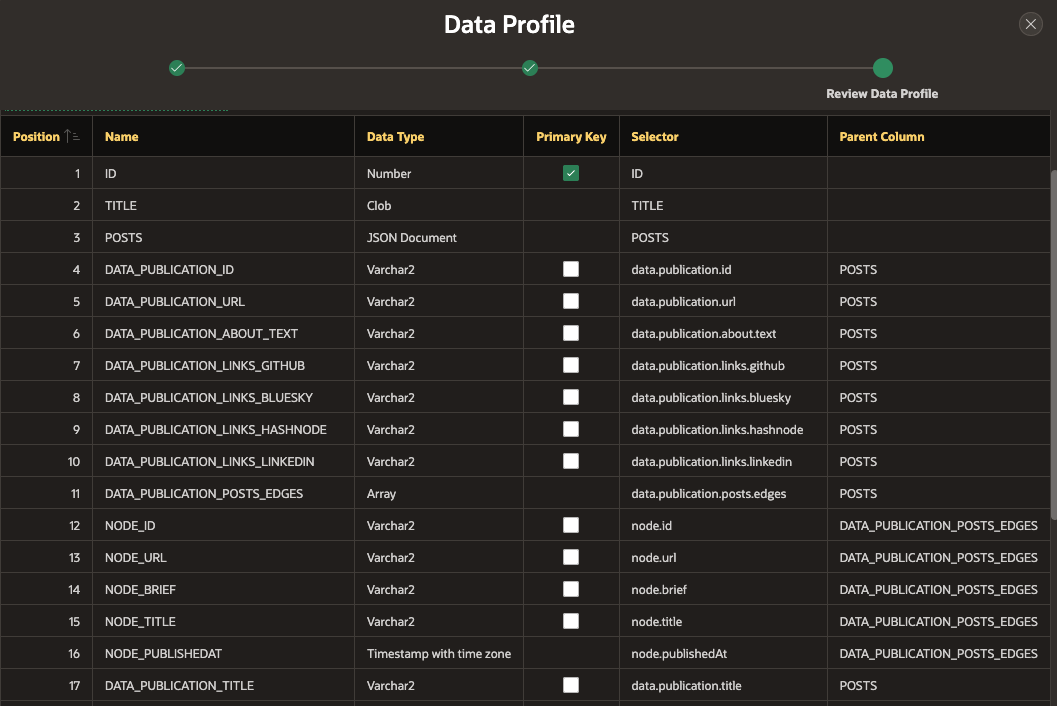
Columns are defined using selector dotted notation and each array is expanded and child attributes reference their parent.
That was easy!
Once created, the JSON Source is available to page components, such as reports, charts, forms, and so on, and shared components, such as list of values and automations. The one enhancement I will be looking for is the inclusion in APEX Workflows!
Posts in APEX
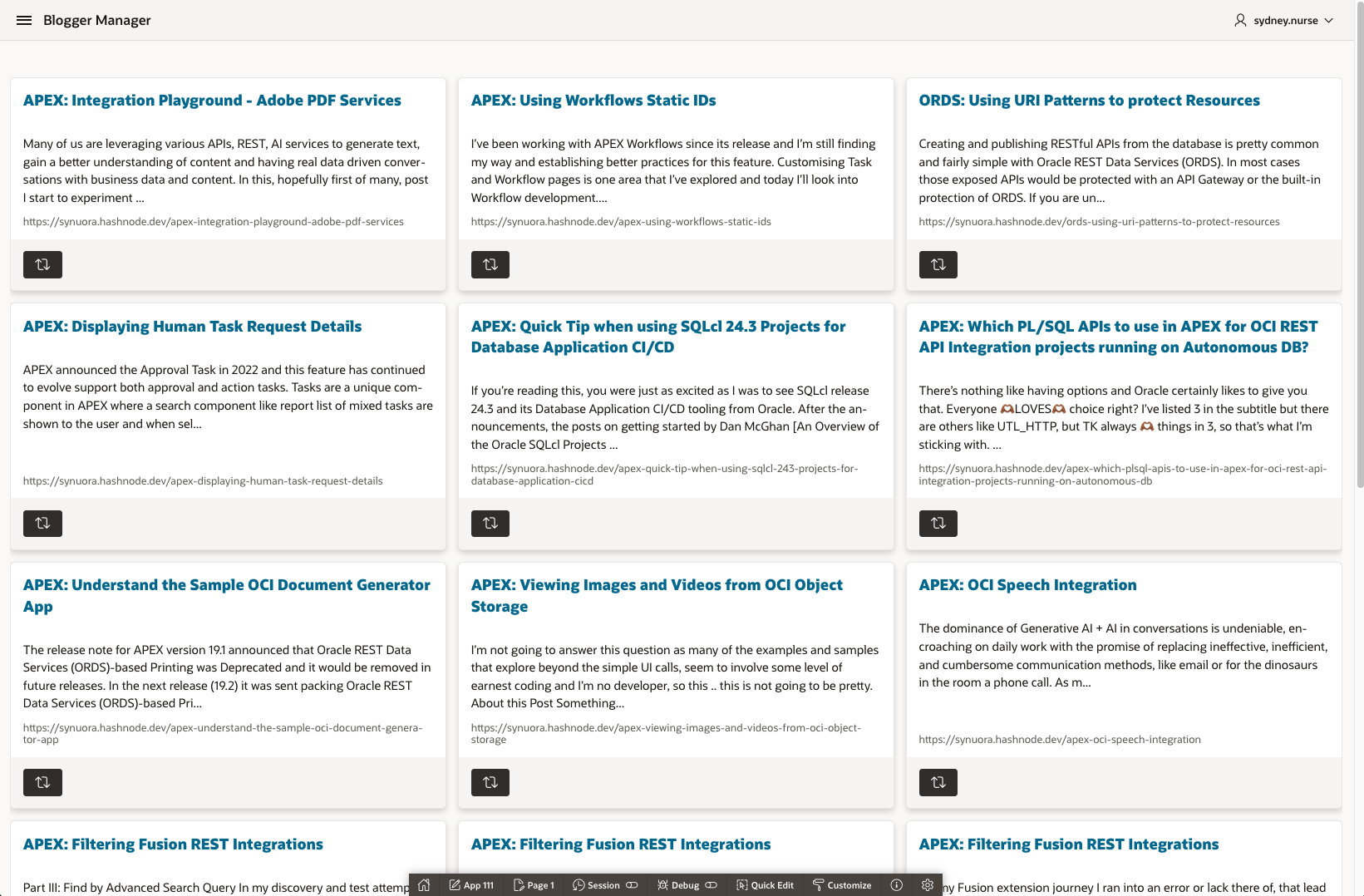
Use your favour means to display data and enjoy.
Posting Comments with GraphQL Mutations
Creating or updating content is referred to as a Mutation in GraphQL. A mutation query operations have signatures like functions or procedures accepting arguments as variables.
I will use addComment as an example, let’s look at its description
addComment Operation
Description
Adds a comment to a post.
Response
Returns an AddCommentPayload!
Arguments
| Name | Description |
input - AddCommentInput! |
When we make the query we must specific the attributes included in the response from the response type, in this instance an AddCommentPayload!
AddCommentPayload
| Field Name | Description |
comment - Comment |
Comment
| Field Name | Description |
id - ID! | The ID of the comment. |
content - Content! | The content of the comment in markdown and html format. |
dateAdded - DateTime! | The date the comment was created. |
The input of this request is of AddCommentInput! type
AddCommentInput
| Input Field | Description |
postId - ID! | The ID of the Post. |
contentMarkdown - String! | The String scalar type represents textual data, represented as UTF-8 character sequences. |
Let’s build up the request
Building the Mutation Request
In order to submit the correct request body, you will need to create a JSOS request with the request in the expected GraphQL format, submitting the mutation operation signature, query attributes, and the values for the variables of the operation signature.
The Mutation Operation Signature
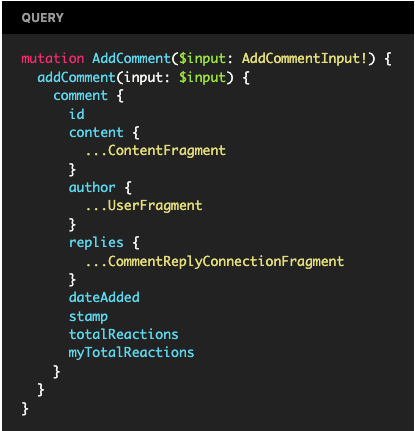
Now in SQL
declare
l_response clob;
l_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_input JSON_OBJECT_T := new JSON_OBJECT_T;
l_ivars JSON_OBJECT_T := new JSON_OBJECT_T;
l_rest_token varchar2(4000) := 'Personal-Access-Token';
begin
l_body.put('query','mutation
AddComment($input: AddCommentInput!){
addComment(input: $input) {
comment {id content{text} dateAdded}
}
}'
);
-- AddComment($input: AddCommentInput!){ => Mutation Operation & Input Variable Type definition
-- addComment(input: $input) { => Operation call & name of the Input Variable
-- comment {id content{text} dateAdded} => Attributes to return
The Mutation Operation Variables
The operation has defined input parameters with variables values included in the variables attribute. This is a standard JSON document and should be constructed as valid JSON.
I am using three parameters to build up the document but you can use any method that you prefer.
l_input - the input containing the details of the post to add the comment and the comment text.
l_vars - the variables container attribute
l_body - the request body
declare
l_response clob;
l_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_input JSON_OBJECT_T := new JSON_OBJECT_T;
l_ivars JSON_OBJECT_T := new JSON_OBJECT_T;
l_rest_token varchar2(4000) := 'Personal-Access-Token';
begin
l_body.put('query','mutation
AddComment($input: AddCommentInput!){
addComment(input: $input) {
comment {id content{text} dateAdded}
}
}'
);
l_input.put('postId','66d81191a053af4aef0dfb0f');
l_input.put('contentMarkdown','My first a favourite post!');
l_ivars.put('input',l_input);
l_body.put('variables',l_ivars);
Submit the Mutation Request to Add a Comment to a Post
This is a mutation request and must be authorised by including the Personal Access Token as the Bearer Token in the request header
declare
l_response clob;
l_body JSON_OBJECT_T := new JSON_OBJECT_T;
l_input JSON_OBJECT_T := new JSON_OBJECT_T;
l_ivars JSON_OBJECT_T := new JSON_OBJECT_T;
l_rest_token varchar2(4000) := 'Personal-Access-Token';
begin
l_body.put('query','mutation
AddComment($input: AddCommentInput!){
addComment(input: $input) {
comment {id content{text} dateAdded}
}
}'
);
-- Parameters of the input
l_input.put('postId','66d81191a053af4aef0dfb0f');
l_input.put('contentMarkdown','My first a favourite post!');
-- Adding the parameters into the input element
l_ivars.put('input',l_input);
-- Adding the input parameter into the variables element
l_body.put('variables',l_ivars);
apex_web_service.g_request_headers.delete();
apex_web_service.g_request_headers(1).name := 'Content-Type';
apex_web_service.g_request_headers(1).value := 'application/json';
apex_web_service.g_request_headers(2).name := 'Authorization';
apex_web_service.g_request_headers(2).value := 'Bearer ' || l_rest_token;
l_response := apex_web_service.make_rest_request(
p_url => 'https://gql.hashnode.com',
p_http_method => 'POST',
p_body => l_body.to_string
);
DBMS_OUTPUT.PUT_LINE(l_body.to_string);
DBMS_OUTPUT.PUT_LINE(l_response);
END;
The Response
{
"data":{
"addComment":{
"comment":{
"id":"67dbf397d44391da6bbced22",
"content":{
"text":"My first a favourite post!\n"
},
"dateAdded":"2025-03-20T10:53:11.024Z"
}
}
}
}
Conclusion
Hashnode GraphQL is an easy to use set of APIs with the ability to extend datasets quickly in a single request.
As an APEX developer it is easy enough to adjust the web service calls and the body holds a single line request.
It is possible to submit query mutations but it took time to understanding how to format the mutation request.
I believe that I can now covert the documentation of a GraphQL API into APEX Web Service REST Requests and may use a different format for more complex JSON variables.
I hope you find this information useful and interesting.
Subscribe to my newsletter
Read articles from Sydney Nurse directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sydney Nurse
Sydney Nurse
I work with software but it does not define me and my constant is change and I live a life of evolution. Learning, adapting, forgetting, re-learning, repeating I am not a Developer, I simply use software tools to solve interesting challenges and implement different use cases.