Unpacking the Pitfalls: Why Multi-Agent LLM Systems Often Stumble
 shilpa gopi
shilpa gopi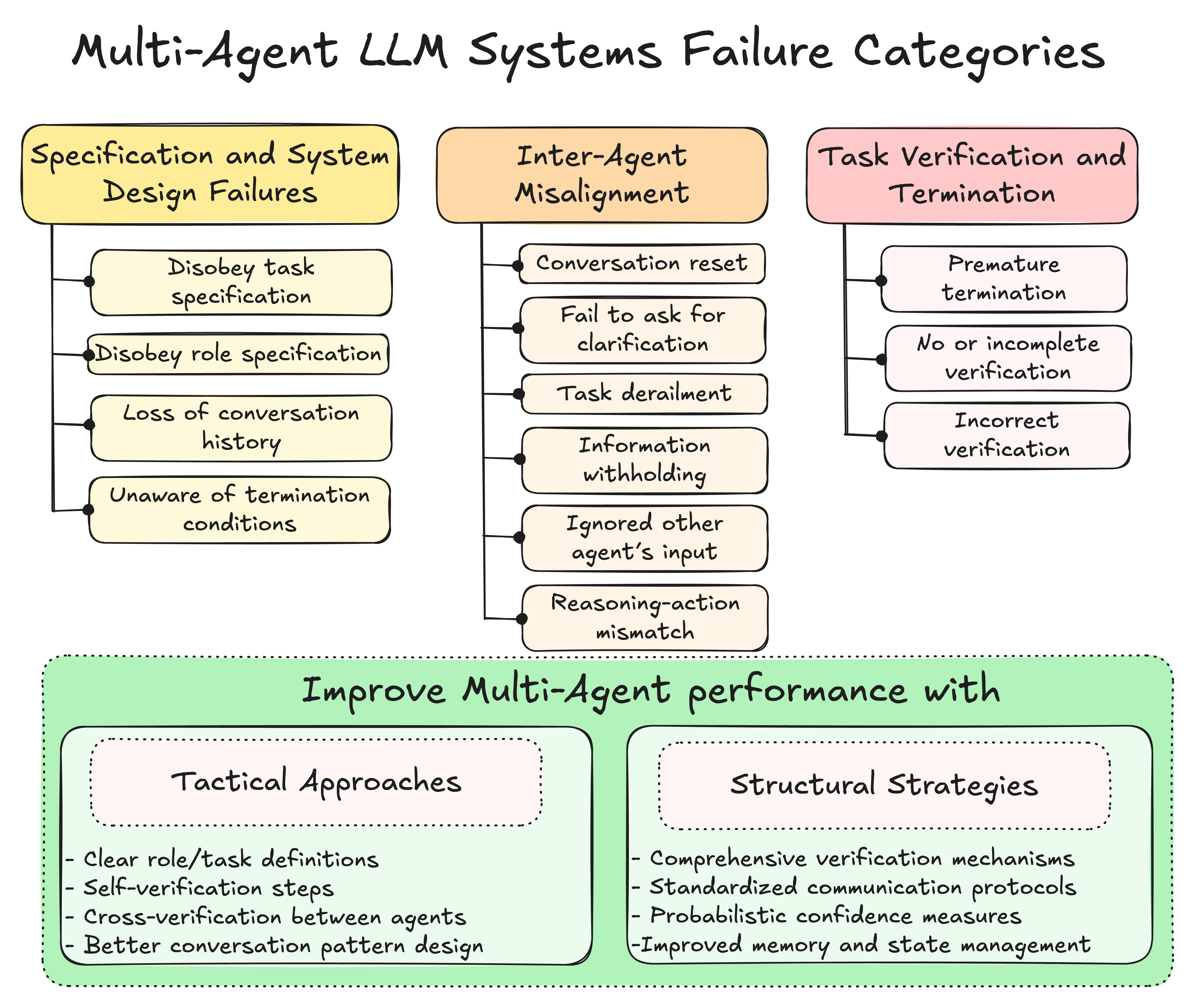
Introduction:
In the rapidly evolving field of artificial intelligence, Multi-Agent Systems (MAS) utilizing Large Language Models (LLMs) have emerged as a promising approach to tackle complex tasks. By leveraging the collaborative capabilities of multiple LLM agents, these systems aim to enhance performance and efficiency. However, despite their potential, MAS often encounter significant challenges that hinder their effectiveness. The paper "Why Do Multi-Agent LLM Systems Fail?" by Mert Cemri and colleagues delves into these issues, providing valuable insights into the limitations of MAS.
What Are Multi-Agent LLM Systems?
Multi-Agent LLM Systems consist of multiple autonomous agents, each powered by a Large Language Model, working collaboratively to achieve specific goals. These agents can communicate, coordinate, and negotiate with one another to perform tasks that may be too complex for a single agent to handle effectively. The idea is that by combining the strengths of multiple agents, the system can exhibit more robust and versatile problem-solving capabilities.
Key Issues in Multi-Agent LLM Systems:
Despite their potential, Multi-Agent LLM Systems face several inherent challenges:
Coordination Complexity: Ensuring that multiple agents work together harmoniously without conflicts is intricate and can lead to inefficiencies.
Communication Overhead: Effective collaboration requires constant communication among agents, which can result in increased computational costs and potential delays.
Scalability Concerns: As the number of agents increases, managing interactions and maintaining system performance becomes increasingly challenging.
Robustness and Reliability: The system must be resilient to individual agent failures and ensure consistent performance, which is often difficult to achieve.
Key Findings from the Paper:
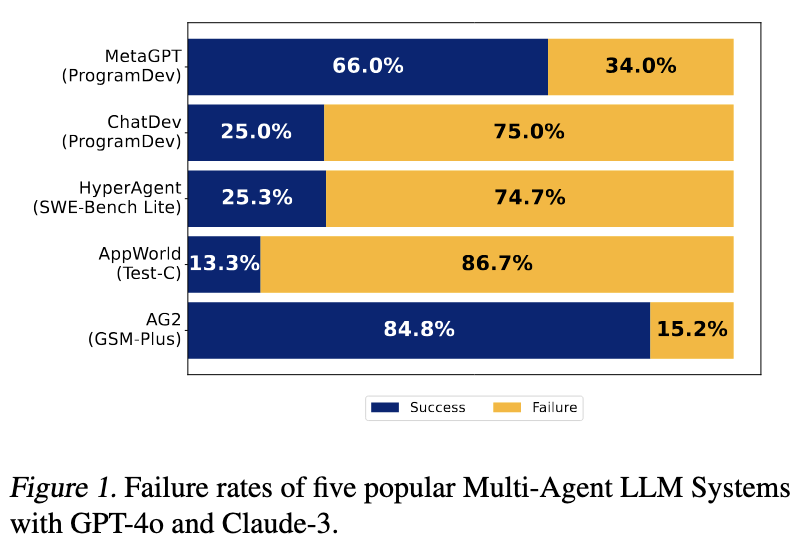
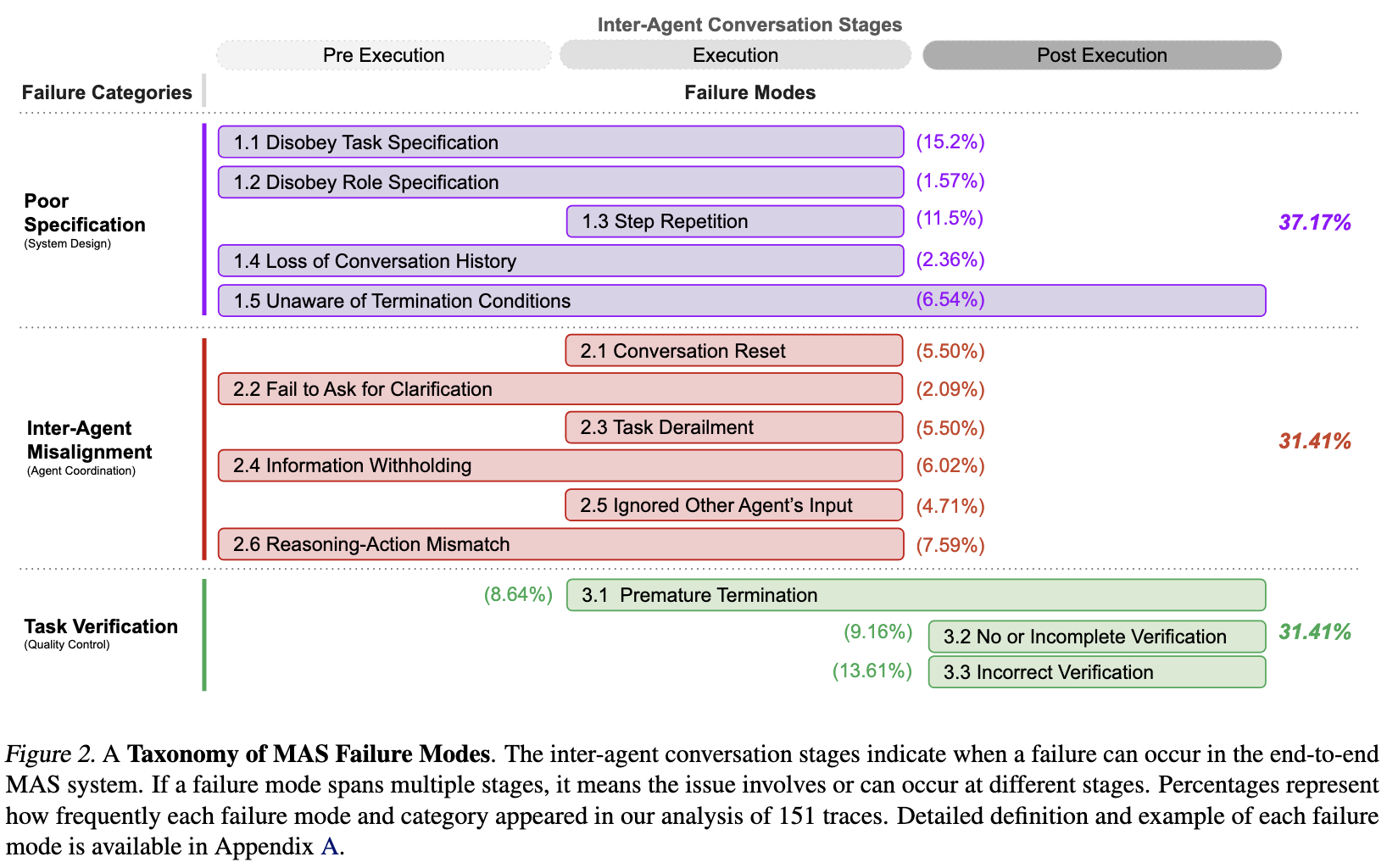
The authors conducted an extensive analysis of five popular MAS frameworks across over 150 tasks, leading to the identification of 14 unique failure modes categorized into three primary areas also introducing taxonomy for identifying failures in LLM Systems:
Specification and System Design Failures (37.2%): Issues arising from unclear task definitions or poorly designed system architectures. For instance, agents may fail to adhere to task constraints or violate role specifications.
Inter-Agent Misalignment (31.4%): Problems due to miscommunication or lack of coordination among agents. Examples include agents not seeking clarification when needed or ignoring input from other agents.
Task Verification and Termination Failures (31.4%): Failures related to inadequate verification processes and improper task completion protocols, such as premature task termination or insufficient verification mechanisms.
Solutions Proposed:
To address these challenges, the authors explored two primary interventions:
Improved Specification of Agent Roles: Enhancing the clarity and precision of agent roles to prevent misunderstandings and overlaps.
Enhanced Orchestration Strategies: Developing better coordination mechanisms among agents to streamline interactions and task execution.
While these interventions led to some improvements, they were not sufficient to address all identified failure modes, indicating the need for more comprehensive solutions.
Future Investments:
To enhance the effectiveness of Multi-Agent LLM Systems, future research and development should focus on:
Developing Advanced Coordination Mechanisms: Implementing sophisticated strategies to improve inter-agent collaboration and reduce conflicts.
Enhancing Communication Protocols: Designing efficient communication methods to reduce overhead and prevent misunderstandings among agents.
Building Robust Verification Processes: Establishing comprehensive verification systems to ensure tasks are completed accurately and thoroughly.
Conclusion:
The study provides a clear roadmap for future research by highlighting specific areas where MAS frameworks need improvement. The open-sourcing of the dataset and the LLM annotator aims to facilitate further research and development in building more robust and reliable MAS. For those working with multi-agent LLM systems, this research offers crucial guidance on identifying, diagnosing, and potentially addressing the failure modes that currently limit the effectiveness of these promising technologies.
Feel free to share your thoughts or experiences with Multi-Agent LLM Systems in the comments below!
Reference: https://arxiv.org/pdf/2503.13657
Subscribe to my newsletter
Read articles from shilpa gopi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by