Implementing AI-Assisted Concept Building in an Android Voice Interface
 Richard Thompson
Richard Thompson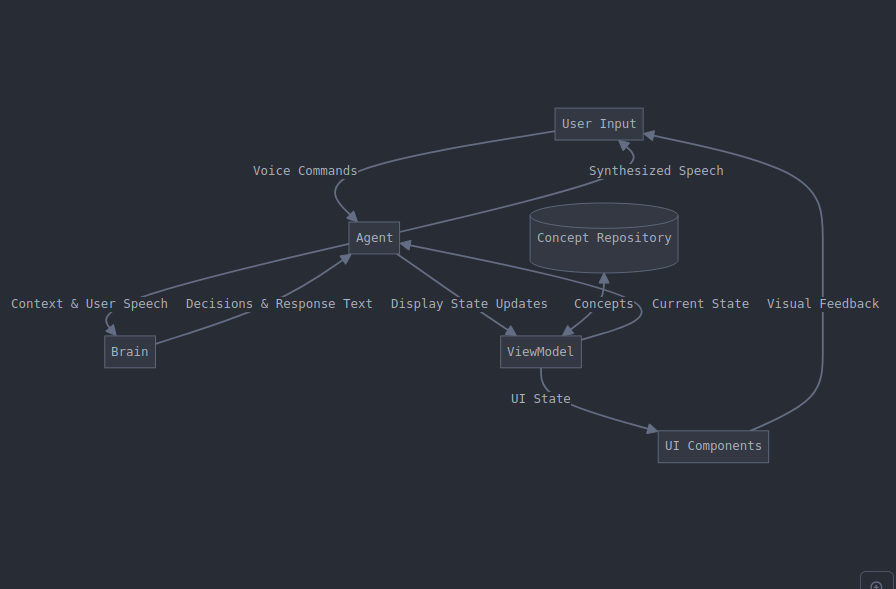
The Challenge
I needed to create a system where users could verbally describe concepts related to their goals (or "wishes"), with an AI “brain” driving the conversation flow.
My first version of the “Manifestation App” was a simple reflex agent. It recognised text so that it could capture it and insert it into fields on the mainscreen of the app, but it had no comprehension of the content of what was being said.
I was determined to give the next version a brain so that it could:
Make decisions about how to move through the conversational process and which information could be used, to
Organise the input into structured concept items, and decide what sequence of functions would best serve its purposes.

Image: Midjourney 6.1, Prompt: A minimalist illustration of a human brain connected to a digital neural network, circular nodes floating between them containing simple symbols, clean white background, ethereal blue glow, technical diagram style, --ar 16:9 --stylize 25
More broadly, the requirements of the app at this point were to:
Be able to hear words and sentences, and produce them in response, in sequence
Use a Large Language Model (LLM) - in this case Google Gemini, to control the conversation flow
Maintain proper state management for sequencing these voice interactions
Organize and store user input as structured concepts
Provide visual feedback during this process
Architectural Overview
Data Flow Diagram showing how information moves through the various components of the system. Created by Claude Ai.
The system consists of three main components:
1. Conversation Agent
The agent coordinates all interactions in the system, through voice interaction with the user.
Manages conversation state and flow, proposing and keeping track of moving the user through this flow. It works like a symbolic “short term memory”, that holds explicit representations of tasks and sequences.
Coordinates between voice system and Brain
Executes Brain’s decisions
Handles persistence of concepts through the conversation
Updates UI state of underlying “memory structures” for the User
Maintains conversation history to provide adequate context to the Brain at each step
Also includes VoiceManagedViewModel, which:
Handles low-level voice recognition
Manages microphone state and permissions
Converts speech to text
Emits raw text for processing by the Conversation Agent
Controls when the system is listening vs. speaking - this was crucial to stop the agent listening to itself and getting into annoying loops where it was speaking and replying to itself.
2. Brain Service (Google Gemini 1.5 Flash Large Language Model)
The Brain can process complex language and make decisions about the process based on this understanding.
Makes decisions about conversation flow
Analyzes user input
Extracts concepts from conversations
Determines when to listen, analyze, or complete
3. Concept Repository / Screen / ViewModel
Repository: Stores all created concepts, essentially the app-based “memory” for the Agent
ViewModel: Manages the UI, serving as a control point for the Agent to manipulate the Screen.
Screen: Provides a visual representation of the concepts and their contents
The Conversation Flow
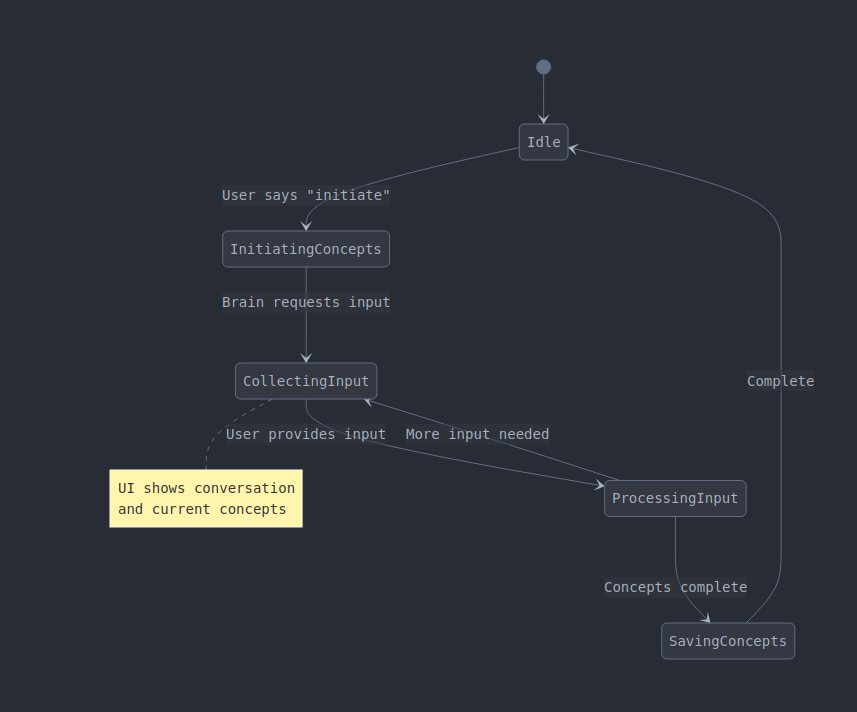
Flow diagram showing the process the Brain follows (managed by the Agent*)*. Created by Claude Ai.
A sample interaction flow might go like this:
Agent sets up initial context for Brain, (InitiatingConcepts) which prompts User with an initial question.
User says something about their situation
Agent records this in conversation history (CollectingInput) and provides full history contents to Brain
Brain receives full context , analyses concepts in separate call (ProcessingInput)
Brain decides whether More input needed, or whether Concepts complete
"User has provided enough detail to analyse some concepts"
"Should transition to AnalyzeInput state"
"Should say: 'Let me understand what you've described...'"
Agent executes this decision, transitions state, passes message back to User
If Concepts complete, Brain instructs Agent to SavingConcepts and Complete
Initiation
User enters concept building mode (the “Concept Screen”)
ConversationAgent sets up initial context
Brain receives context and decides first action
Setting up the context
First I needed to decide what the Brain would need to understand about the context for it to be able to operate. A few key elements were needed:
What is the current goal? In a present state - desired state, we are wanting to draw comparisons about where the user is now with respect to the goal, versus where he wanted to be. The goal would be to have entered information about each of the available nodes (present/desired). Information would be in the form of a list of items corresponding to each one.
What is the plan to achieve this goal?
The Brain needed a method of perceiving the world we were presenting. It would need to access the information stored in each of the nodes. It would make sense to send this structure information to the brain at every step as part of the prompt.
It would then need a plan as to how to communicate what was needed to the user, in an organised manner, i.e. a way of asking questions for input, analyzing the input, and sending back a processed result. The Brain would need to instruct the Agent to store the information.
It would need to know what part of the process it was in, and what was likely to be required next. It would need to instruct the Agent that it was satisfied with the result and to move onto the next stage of the process.
More specifically, the Brain:
Must know the overall goals (building concept lists) and rules (conversation states, available actions)
Can analyze context and choose appropriate next states/actions
Manages its own state tracking via the Agent’s conversation structure
Makes decisions about when to analyze, store, or request more information
Uses conversation history to inform decisions
Most importantly, the Brain, in collaboration with the Conversation Agent, will need to manage a conversation which consists of a sequential interplay of information between two parties (the Agent/Brain and the User), out of which information would emerge, be analysed, and subsequently stored in the correct structure, for later access.
Sequence Diagram of Very First Stage of the App’s Process
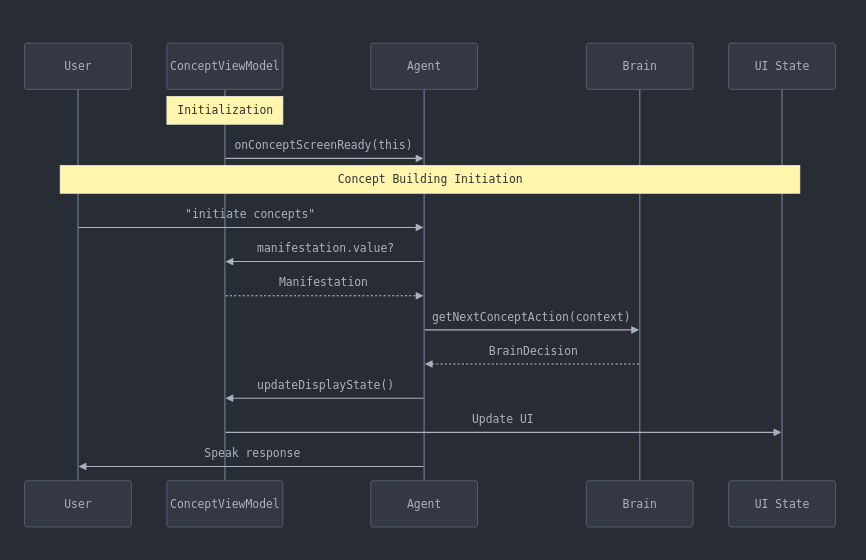
Sequence Diagram showing the temporal information flow, showing specifics of how the different screens or modules must interact and pass data between themselves over time. Still very simplistic at this stage, and mainly concerned with getting everything in place to get that first decision from the brain about what to do. Created by Claude Ai.
Mapping the User-Agent-Brain Interaction in More Detail
In the first stage of this process I realise the importance of clarifying the different roles for the Agent and the Brain. The process mapped above will continue to be an intricate interplay between the different systems, and I need to be clear on the function that each module serves.
Separating Concerns and Further Clarifying Roles
1. Voice State Management
DialogueState must be maintained even with AI control
Speaking and listening states prevent overlap
Voice module handles timing and buffering
2. Brain Integration
Brain receives full context for decisions
Conversation history provides memory
Agent executes but doesn't decide
Brain responses are structured for reliable parsing
3. Separation of Concerns
Voice module: Hardware interaction
Agent: State management and execution
Brain: Decision making and analysis
Repository: Persistence
UI: Display and feedback
Let's walk through the sequence of how this code works:
- Initial Setup
// When the concept screen starts, the ConceptToolLibrary is created
val toolLibrary = ConceptToolLibrary(agent, conceptViewModel)
// This registers all available tools in its init block, storing them in a map
- Starting Concept Building
// User triggers concept building, agent calls:
initiateConceptBuilding()
// This gets the current context from conceptViewModel
val context = currentConceptViewModel?.getConceptBuildingContext()
- First Brain Interaction
// Agent calls brain service with context and tool library
brainService.getNextConceptAction(context, toolLibrary)
- Brain Receives Information
Gets full prompt including:
Available tools and their parameters
Current concept framework
Current status
Last user input (if any)
Decides what to do based on this context
- Brain Returns Decision
// Brain returns JSON like:
{
"toolName": "askQuestion",
"parameters": {
"question": "What aspects of your current situation would you most like to change?",
},
"action": "QUESTION_RESPONSE"
}
// This gets parsed into a BrainDecision object
- Agent Executes Tool
// Agent receives BrainDecision and passes it to tool library
toolLibrary.executeTool(decision)
// Tool library looks up the tool by name and executes it with parameters
// In this case, QuestionTool:
- Speaks the question
- Updates dialogue state to expect input
- Handling Response
// When user responds:
- Agent captures response
- Creates new context with the response
- Sends back to brain for next decision
This cycle continues with the brain choosing tools and the agent executing them until the concept building is complete.
This structure:
Defines a clear interface for what actions the brain can take
Provides context about the conversation state and history
Allows the brain to make decisions about state transitions
Handles concept analysis as a separate function
The brain becomes the decision maker while the app handles the mechanics (state management, storage, UI, etc.)
Data Flow and State Management
Core State Types
// Conversation types
sealed class ConversationType {
data object ConceptBuilding : ConversationType()
// ... other types
}
// Brain decisions
data class BrainDecision(
val action: ConceptAction,
val responseText: String
)
enum class ConceptAction {
CONTINUE_LISTENING,
ANALYZE_INPUT,
SAVE_CONCEPTS,
REQUEST_MORE,
COMPLETE
}
// Display state for UI
sealed class DisplayState {
data class ConceptBuilding(
val type: ConceptType,
val speakerText: String,
val isProcessing: Boolean,
val concepts: List<ConceptItem>
) : DisplayState()
}
Brain Decision Execution
How much code to provide here?
Brain-Agent Communication
Context Passing
The agent packages everything the brain needs:
data class ConceptContext(
val manifestationTitle: String,
val conceptType: ConceptType,
val existingConcepts: List<ConceptItem>,
val maxSlots: Int,
val conversationHistory: List<ConversationEntry>
)
Decision Flow
Agent packages context
Brain receives context and returns decision
Agent executes decision and updates states
Process repeats until completion
Brain Prompt Structure
You are managing a conversation to help build a concept map.
Current context:
- Type: [Present/Desired] State
- Filled slots: [X/Y]
- Recent conversation: [History]
Decide:
1. What action to take next
2. What to say to the user
3. Whether to process any concepts
Advantages of This Architecture
Flexibility: Brain can adapt conversation flow based on context
Maintainability: Clear separation of concerns
Reliability: Structured state management
Extensibility: Easy to add new conversation types
User Experience: Seamless voice interaction with AI guidance
Trade-offs and Considerations
State Complexity: Multiple state types must be coordinated
Latency: AI decisions add processing time
Error Handling: Must handle AI, voice, and storage failures
Resource Usage: Continuous AI interaction is resource-intensive
Future Improvements
Caching frequent brain decisions
Offline fallback modes
Better error recovery
More sophisticated concept analysis
Multi-modal input support
Conclusion
This architecture successfully combines voice interaction with AI control while maintaining reliable state management. The key is clear separation of concerns while allowing the brain to drive high-level decisions without compromising the reliability of the voice interface.
Subscribe to my newsletter
Read articles from Richard Thompson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Richard Thompson
Richard Thompson
Spending a year and a half re-educating myself as a Cognitive Scientist / Ai Engineer.