Quick POC for "leader election" using ZooKeeper
 Hariom Yadav
Hariom YadavWhat Problem Does Leader Election Solve?
In distributed systems, many nodes (servers) work together to perform tasks. However, some tasks require coordination by a single node to avoid conflicts or inconsistencies. For example:
Database Writes : Only one node should handle writes to prevent data corruption.
Task Scheduling : One node should assign tasks to avoid duplicate work.
Cluster Coordination : A single node should manage cluster-wide decisions like failover or rebalancing.
Without a mechanism to elect a leader, these systems can face chaos :
Multiple nodes might try to perform the same task simultaneously.
Data could become inconsistent or corrupted.
The system might deadlock or behave unpredictably.
Leader election ensures that one node is always in charge , even if nodes fail or network issues occur.
Solution with ZooKeeper
ZooKeeper ensures a smooth transition by electing a new leader:
Before Failure :
Node A creates an ephemeral sequential node in ZooKeeper:
/election/leader_0000000000.Nodes B and C create their own nodes:
/election/leader_0000000001and/election/leader_0000000002.Node A is the leader because it has the smallest sequence number.
Node A Crashes :
Node A’s ephemeral node (
leader_0000000000) is automatically deleted.Node B detects this via a watch and checks if it’s now the smallest node (
leader_0000000001).
New Leader Elected :
Node B becomes the new primary and starts handling write operations.
Node C sets a watch on Node B in case it fails.
Outcome
The system remains consistent and operational, even after the failure of the primary node.
There’s no split-brain or ambiguity about who’s in charge.
Example Real-World Scenario: Database Failover
Imagine you’re running a distributed database with three nodes: Node A, Node B, and Node C. Node A is the primary node responsible for handling all write operations, while Nodes B and C act as backups (replicas).
Problem
What happens if Node A crashes? Without a leader election mechanism:
Nodes B and C might both try to become the new primary.
This could lead to split-brain , where two nodes think they’re in charge, causing data inconsistency or corruption.
Step-by-step POC for leader election using ZooKeeper
Simulate 3 nodes competing to become the leader and observe how ZooKeeper handles failover.
Step 1: Start ZooKeeper
brew install zookeeper
zkServer start
Step 2: Simulate 3 Nodes Competing for Leadership
Open 3 terminal windows to represent 3 nodes.
Terminal 1 (Node 1):
zkCli.sh
create /election "election" # Create parent node (persistent)
create -e -s /election/leader_ "node1" # Create ephemeral + sequential node
Output: Created /election/leader_0000000000
A session is created for node1.
The
zkCli.shclient automatically sends heartbeats to ZooKeeper.
Terminal 2 (Node 2):
zkCli.sh
create -e -s /election/leader_ "node2"
Output: Created /election/leader_0000000001
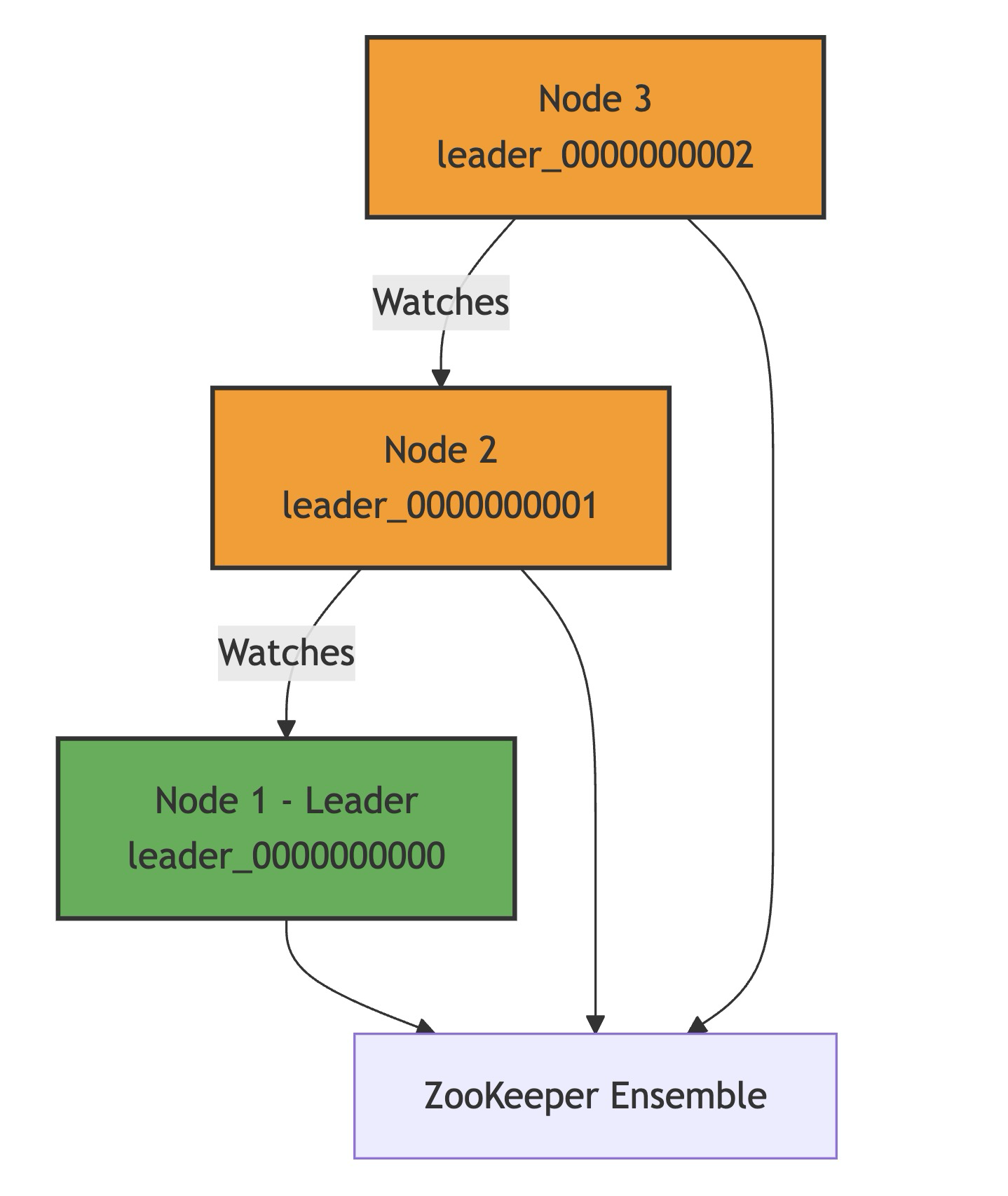
If a node isn’t the leader, it sets a watch on the node immediately before it in the sequence
- Node 2 (
leader_0000000001) watchesleader_0000000000.
- Node 2 (
Terminal 3 (Node 3):
zkCli.sh
create -e -s /election/leader_ "node3"
Output: Created /election/leader_0000000002
If a node isn’t the leader, it sets a watch on the node immediately before it in the sequence
- Node 3 (
leader_0000000002) watchesleader_0000000001.
- Node 3 (
Step 3: Determine the Leader
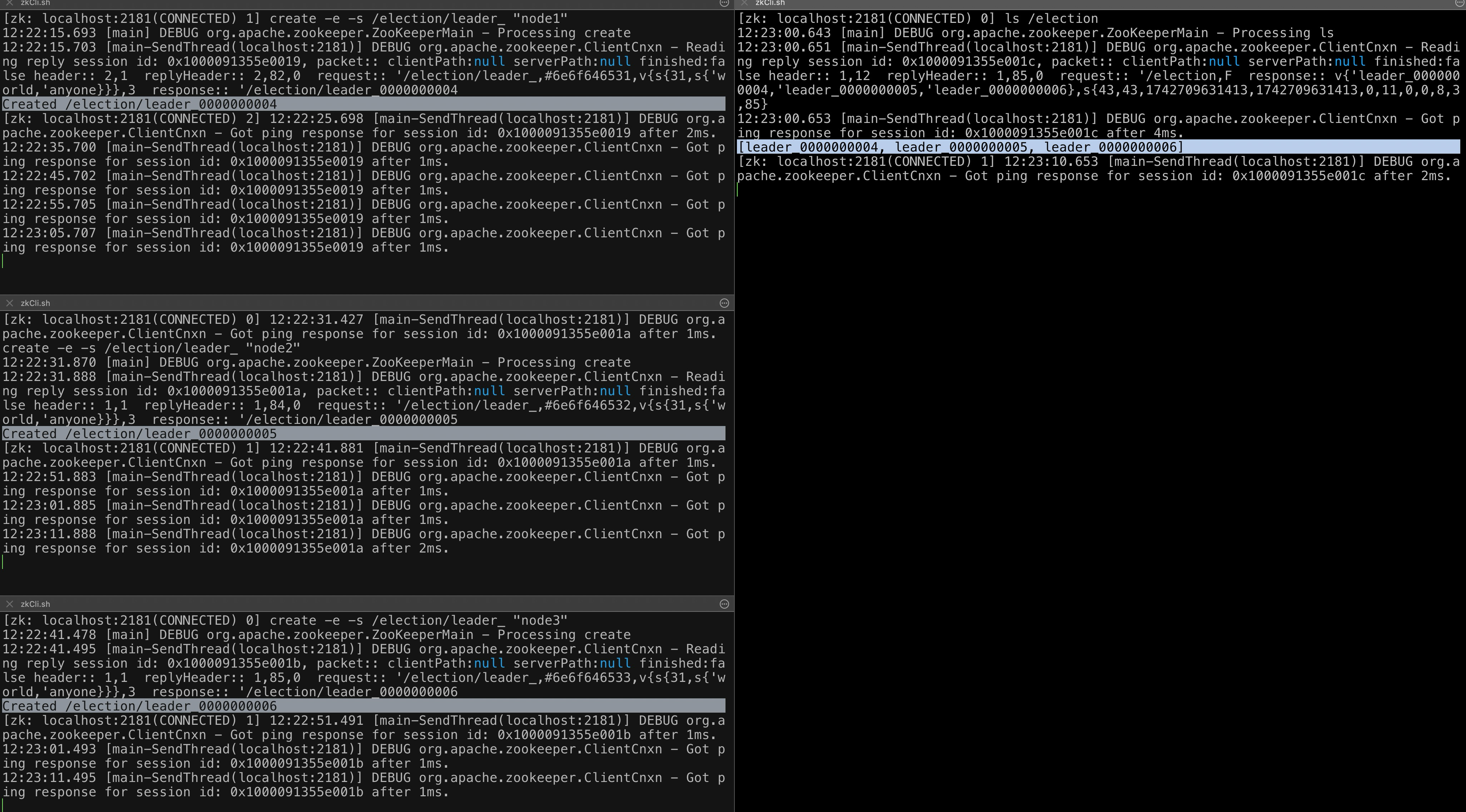
List all leader nodes: In any terminal:
ls /election Output: [leader_0000000000, leader_0000000001, leader_0000000002]Leader Logic:
- The node with the smallest sequence number (
leader_0000000000) becomes the leader.
- The node with the smallest sequence number (
Step 4: Simulate Leader Failure
Kill Node 1 (Terminal 1):
Press Ctrl+C to terminate the ZooKeeper CLI session.
The ephemeral node
/election/leader_0000000000is deleted.
Step 5: Observe New Leader Election
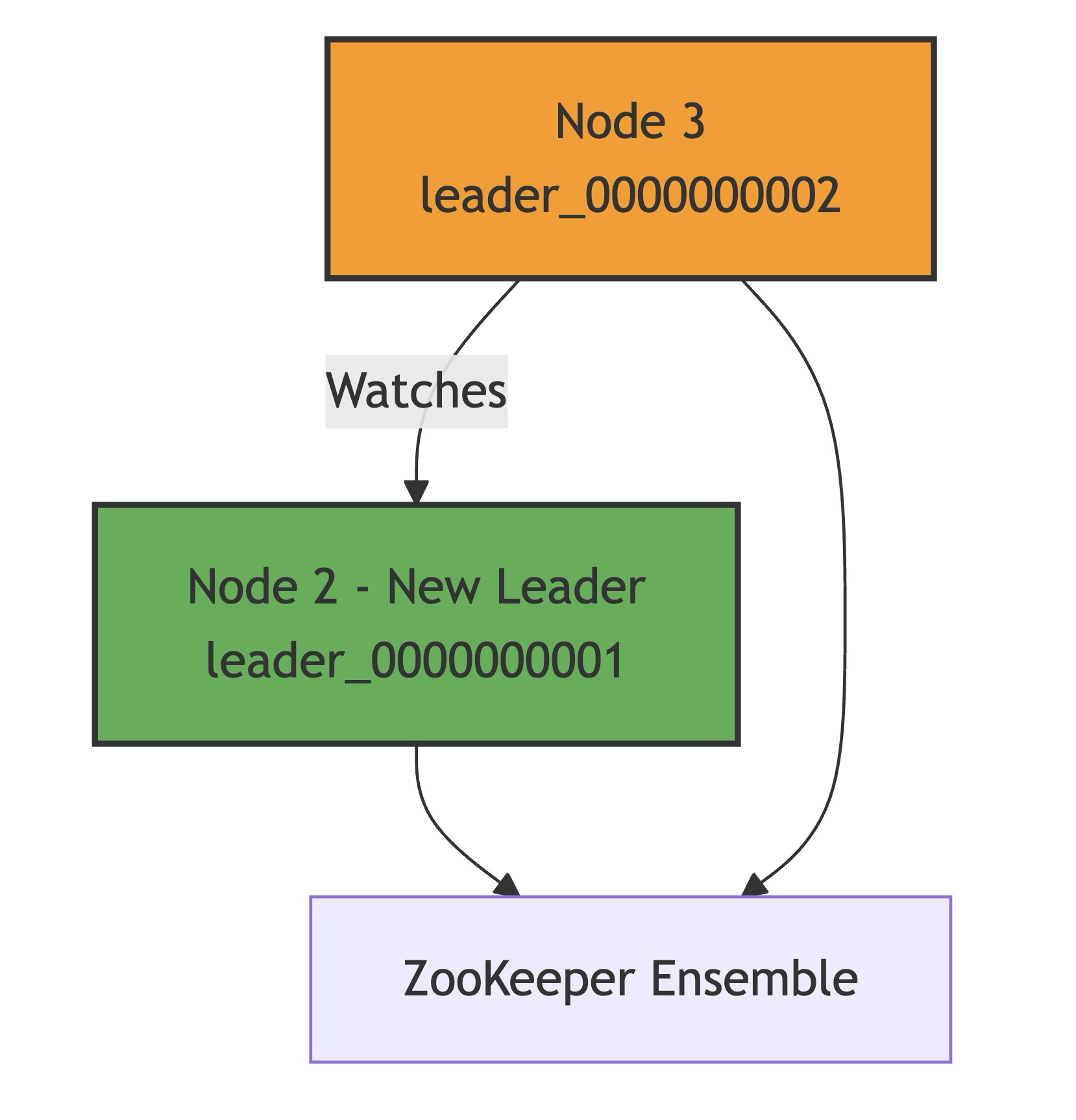
List remaining nodes:
ls /election Output: [leader_0000000001, leader_0000000002]New Leader:
- The next smallest node (
leader_0000000001) becomes the new leader.
- The next smallest node (
Concepts
Data is stored in a tree-like structure (like a filesystem)
Persistent Nodes : Survive even if the client disconnects.
Ephemeral Nodes : Automatically deleted when the client session ends (e.g., a service crashing).
Sequential Nodes : Automatically appended with a monotonically increasing counter (e.g.,
/leader_0000000001).Watches to notify waiting clients. If the leader’s node is deleted (due to failure), the next node in line takes over.
Key Benefits of ZooKeeper’s Approach
Automatic Failover : If the leader dies, the next node in line takes over seamlessly.
Deterministic Order : Sequence numbers ensure there’s no ambiguity about who should lead.
Fault Tolerance : Ephemeral nodes ensure failed nodes are automatically removed.
NOTE:
ZooKeeper provides the building blocks (sequential nodes, watches, and atomic operations).
Your application (or a client library) must implement the logic to:
Sort nodes to find the smallest sequence number.
Watch the predecessor node for changes.
| Component | Handled by ZooKeeper | Handled by Application/Library |
| Node creation (sequential) | ✅ | |
| Ordering guarantee | ✅ | |
| Finding the smallest node | ❌ | ✅ (via sorting) |
| Watching predecessor node | ❌ | ✅ (via watches) |
This POC mirrors how systems like Kubernetes or distributed databases elect leaders for high availability.🚀
Subscribe to my newsletter
Read articles from Hariom Yadav directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Hariom Yadav
Hariom Yadav
🏞️ Love photography, Love spring, Love Simplicity, Love Meditation 😌 ✌️