There's a Lot of Bad Telemetry Out There
 Juraci Paixão Kröhling
Juraci Paixão Kröhling
Ninety percent. That's the number the founder of an observability company mentioned some time ago when talking about telemetry data that withers away unused. It is data created, collected, transmitted, and stored, without ever blooming into a dashboard, alert, or query result. Our monitoring tools keep planting more and more data seeds, hoping they'll sprout into useful insights during a 2am production incident. Like planting without proper soil analysis, these generic instrumentation tools create low-quality telemetry that isn't suited for our environment. Traces from health check endpoints are like weeds taking up valuable space.
Don’t get me wrong, this is still better than nothing! However, many companies have matured past this stage and need to cultivate higher quality telemetry.
Telemetry is essential for us, observability engineers, to understand how our systems are performing. It's the soil from which observability and modern monitoring blossom. Despite its importance, a significant amount of telemetry data out there is, to put it bluntly, bad. This post will explore what good telemetry looks like, digging into the problems caused by bad telemetry, examine the root causes, and plant a thought on how to cultivate higher quality data.
What is Good Telemetry?
Good telemetry is characterized by providing an accurate, relevant, timely, and actionable picture of a system's health and performance. It offers just enough information — not too much or too little — to allow for improved troubleshooting, quick identification and resolution of issues, and a deeper understanding of the system. Additionally, good telemetry facilitates faster incident response, minimizing downtime and service disruptions, and bears fruit in the form of data-driven decisions that optimize performance.
Examples include traces that show the path of a request through a system, metrics that accurately reflect resource utilization, and logs that provide context for errors and warnings. Quite frequently, good telemetry is used to provide business insights along with operational data.
Bad Telemetry
Bad telemetry is the opposite of good telemetry: inaccurate, irrelevant, old, non-actionable, or far too much in terms of volume.
Inaccurate telemetry happens when we have the wrong values, leading us to wrong conclusions. For instance, concurrently counting the number of leaves in a tree and storing the counter on a non-concurrent data structure will eventually result in the wrong number of leaves being reported
Irrelevant telemetry doesn’t provide any meaningful insight. It might be interesting to know that I have three boxes of kiwis, but without knowing the size of the box, that information is meaningless.
Incomplete telemetry means that we can’t determine the root cause of a problem. How can I tell whether my strawberries received enough sun if I’m not recording the amount of sun they received? How can I tell why my tulips didn’t grow if I don’t know whether they were planted in the first place?
Old data is bad telemetry, meaning that I’m only taking action when it might be too late. There’s no point in employing a scarecrow when the birds ate all the seeds already
Having too much data can also make it harder to find the real information we are looking for. It’ll definitely take us longer to find a magic herb in the middle of overgrown bushes.
One interesting consideration is that the definition of bad telemetry also varies based on the backend we are using. Rice needs tons of water, purple coneflower will probably complain. For a time-series database, a high-cardinality metric is certainly not desirable.
Consequences of bad telemetry
We, as an industry, have tolerated bad telemetry as a price to pay for having telemetry in the first place. However, bad telemetry isn’t just bad: it’s the weed in our garden. Misleading insights from erroneous data can lead to poor decisions, and time and effort can be wasted analyzing useless data. Additionally, bad telemetry can result in slower problem resolution, due to the difficulty in identifying and fixing issues. It can lead to poor decision-making and incorrect business strategies based on faulty metrics.
Perhaps more relevant for today’s economic realities, bad telemetry often means paying way more for observability than you should: high egress costs, overprovisioned infrastructure, complex pipelines, and unreasonably big checks to observability vendors.
Root Causes of Bad Telemetry
Many developers and engineers lack a full understanding of the principles of good telemetry. Observability is not taught alongside writing operating systems or databases at the university. It's not surprising that engineers don't learn how to properly instrument their applications.
Like security, observability is typically a discipline that engineers come across when they get more experienced, once they’ve been burned by bug reports that they couldn’t reproduce, leading to frustrated users. Insufficient planning is another issue, as telemetry is often an afterthought rather than a core part of system design. Poor implementation is also a factor, as instrumentation can be complex and mistakes are easily made. Finally, telemetry systems require ongoing tending and upkeep, and inadequate maintenance can lead to having an infestation of bad telemetry. Instrumenting complex systems can be particularly challenging, as tasks like ensuring that context is propagated correctly across distributed services are crucial for accurate tracing.
It doesn’t help that things are still moving really fast in observability, causing best practices to suddenly become anti-patterns, as well as the lack of standardization in new areas. Applications making use of generative AI tools or LLMs need to be instrumented today, but standards to instrument those components are still being worked on. Without clear industry guidance, people often have to make decisions based on their experiences (or their vendor’s suggestions), which quite often means that they’d be at odds with the standard when it gets created. OpenTelemetry semantic conventions definitely help here, and while OTel is in constant progress, we don’t have enough stable conventions for all that matters out there.
How to Improve Telemetry Quality
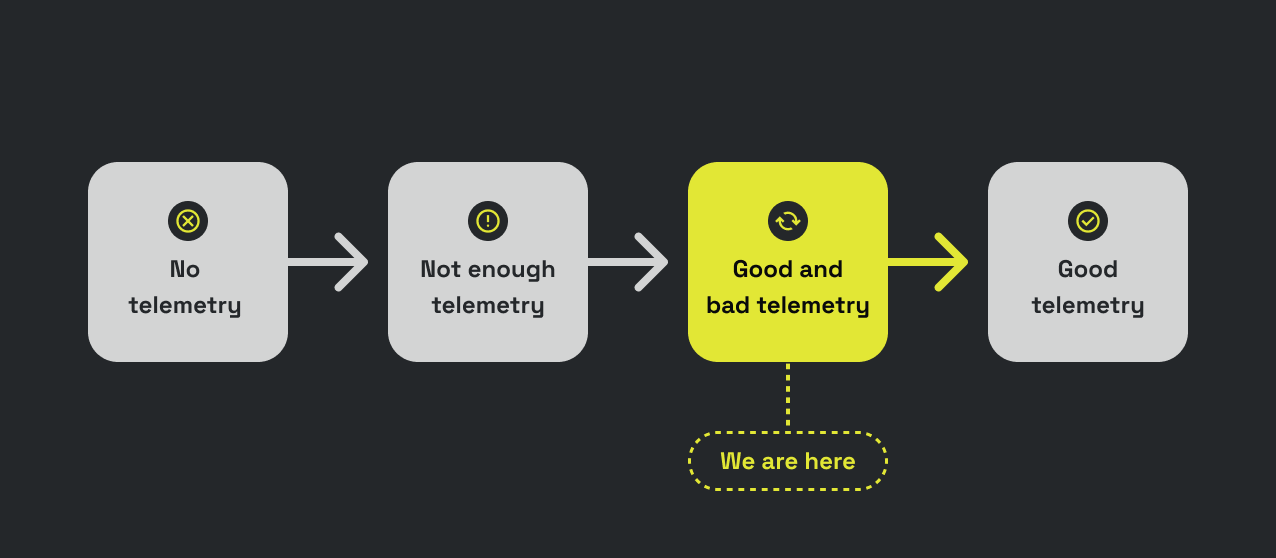
We are at the beginning of this journey towards high quality telemetry, and while there’s a lot to learn, I believe that we have enough to start changing the status quo. We already know a few anti-patterns, like the ones we mentioned earlier. We can also be opinionated about some solutions, such as OpenTelemetry, and gather insights based on those strong opinions. Perhaps all my telemetry should have a service.name and service.version field? Perhaps some resource attributes, like process.executable.path, should be filtered out at the source when going to a time-series metrics backend?
Improving telemetry quality is a long-term activity, and I believe we’ll never have perfectly good telemetry. New services come and go every day, new versions are deployed all the time, and they all bring new telemetry with them, which is likely to be imperfect.
It’s our job as observability engineers to understand what is good and what is bad telemetry, knowing our tools and how they’ll behave with the telemetry we are sending to them. Once we know and have our own recipes of what’s good and what’s bad, it’s a matter of looking into our telemetry and applying our knowledge, cross-pollinating with the engineers doing the instrumentation. Very likely, they are the ones doing the actual changes, or at least reviewing the pull requests we send their way improving the instrumentation of their code.
The question that remains is: how do we show “progress”? Are we really better off with good telemetry, or can we just survive with bad telemetry? Instinctively, we know that good telemetry is more efficient than bad telemetry, but we should be ready to measure the impact.
Conclusion
Bad telemetry remains a pervasive challenge with significant consequences, one that we, as observability engineers, have often tolerated or underestimated. This is partly due to a lack of clear understanding of what constitutes good telemetry and partly due to the absence of robust tools and processes for detection and remediation. However, by actively defining and implementing standards for good telemetry, identifying the root causes of poor data quality (like pulling out weeds), and leveraging tools like OpenTelemetry, we can unlock the full potential of observability. This means reduced alert fatigue, faster incident resolution, and ultimately, more reliable and performant systems. Pioneering teams are already demonstrating the value of this approach, implementing semantic conventions and data quality pipelines that yield healthy, actionable insights. It's time for each of us to assess our own telemetry landscape, advocate for better instrumentation practices within our teams, and ensure that the data we rely on is truly serving our needs.
Credits
Dan Blanco, my colleague at OpenTelemetry’s Governance Committee, is the author of the quote “There’s a lot of bad telemetry out there,” and he used it when I was describing what we are building at OllyGarden. He immediately understood our value proposition, wrapping it up with this quote. I like it: it’s blunt, it’s real, and it’s blameless.
Subscribe to my newsletter
Read articles from Juraci Paixão Kröhling directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Juraci Paixão Kröhling
Juraci Paixão Kröhling
🚀 Building Solutions in Observability | Co-Founder of OllyGarden As the co-founder of OllyGarden, I focus on creating tools and frameworks that enhance observability and address challenges in telemetry and distributed systems. My work leverages expertise in OpenTelemetry and insights from industry collaborations to develop practical, scalable solutions. 💡 A Career Rooted in Technology and Innovation With experience spanning startups, enterprise environments, and global collaborations, I bring a well-rounded approach to building software systems. My focus areas include observability practices, data pipelines, and message queue processing, ensuring reliability and efficiency in modern systems. 🤝 Collaborating Across the Ecosystem I value working with and learning from others in the technology ecosystem. Through discussions with experts and partnerships, I continuously seek to address industry challenges and uncover new opportunities for growth and innovation. 🌱 Continuous Development I am dedicated to refining my skills in software engineering and advancing observability practices. By staying engaged with emerging technologies and trends, I aim to develop solutions that address real-world challenges and drive progress in the field. 🎯 How I Can Contribute Addressing observability challenges Implementing OpenTelemetry solutions Exploring partnerships to bring ideas to life