An Open Letter to Anthropic's AI Director: Prioritize Mathematical Rigor & External Research Over Biological Analogies
 Gerard Sans
Gerard SansTable of contents
- An Open Letter to Anthropic's AI Director: Prioritize Mathematical Rigor & External Research Over Biological Analogies
- Transformers 101: Statistical Prediction, Not Sentience
- Anthropic's Epic Faceplant: Research Amnesia on Reasoning and Planning
- Demo Time: Exposing the Statistical Strings
- What This Really Means
- What It Doesn't Mean (Anthropic's Delusions)
- Try These Yourself: Bias Bonanza
- Conclusion: Grounding AI Research in Reality

An Open Letter to Anthropic's AI Director: Prioritize Mathematical Rigor & External Research Over Biological Analogies
Anthropic recently published "On the Biology of a Large Language Model" (Lindsey, Gurnee, et al., March 27, 2025), investigating the internal mechanisms of Claude 3.5 Haiku. Frankly, the framing reads like science fiction penned by researchers lost in metaphor, detached from the computational reality of their own creations. Armed with a large team (mentioned on Page 2) and drawing analogies to biology's microscope revealing cellular structures (Page 3), they embark on a quest for biological parallels, hunting "features" and "circuits" and examining phenomena related to "multi-step reasoning" (Page 3) and "planning in poems" (Page 3) as if discovering nascent cognition.
This isn't just misguided; it's demonstrably wrong, ignoring both the fundamental mechanics of transformers and a growing body of research – some available for years now – highlighting their profound limitations. It overlooks core concepts like token bombs, context contamination, and the very nature of statistical pattern matching that drives these systems. Forget the lab coats; simple prompts expose the hype. It’s time to dissect Anthropic's apparent research amnesia using the evidence right under their noses – evidence showing these systems can't plan robustly, don't reason reliably, and lack the coherent world models necessary for true understanding. Staying grounded in actual evidence, rather than speculation, is crucial.
Transformers 101: Statistical Prediction, Not Sentience
Let's be crystal clear: Transformers like Claude aren't "biological" (as per their Page 3 framing). They are staggeringly complex statistical engines. Trained on trillions of text and code examples, they build a high-dimensional map of token co-occurrence. When prompted, they don't think; they use their attention mechanism to calculate the most probable sequence continuation. This mechanism, fundamental to transformers, is designed to weigh the importance of different words in the input context based on learned statistical patterns. Here is the attention mechanism, not magic.
Popularity rules this map because the attention mechanism inherently gives more weight to statistically dominant tokens and their strong associations, like "Brad Pitt". This powerful statistical weighting, a direct consequence of attention's design, pulls related but less frequent tokens like "Jane Pitt" along. Obscure tokens lack this inherent ability to strongly draw attention unless anchored by a high-attention token. Anthropic chases "circuits" (Page 3)... but they're likely just mapping the effects of attention focusing on statistically prominent signals – a core computational artifact, not nascent biology. Misinterpreting these direct consequences of the transformer architecture leads to flawed analogies.
Anthropic's Epic Faceplant: Research Amnesia on Reasoning and Planning
Anthropic investigates phenomena like "planning in poems" (Page 3) and "multi-step reasoning" (Page 3), framing them through a biological lens. Yet, this focus seems to neglect or downplay the significant, documented limitations in these very areas. The lack of a "unified worldview" isn't a novel discovery within their model; it's symptomatic of issues well-explored externally, which they seem determined to ignore or explain away with biological fantasies. The literature is replete with studies demonstrating these core issues:
Fundamental Reasoning Failures: Arkoudas's "GPT-4 Can't Reason" (arXiv:2308.03762v2, Aug 2023) provided a damning qualitative analysis showing GPT-4 was "utterly incapable of reasoning" on basic logic, arithmetic, and common-sense tasks, plagued by errors revealing a lack of core logical competence. This predates Anthropic's recent work, making their exploration of "reasoning" mechanisms seem detached if it doesn't grapple with these foundational failures.
Inability to Plan or Self-Verify: Kambhampati et al. in "Position: LLMs Can't Plan..." (arXiv:2402.01817v3, Jun 2024) argue convincingly that LLMs cannot plan reliably or self-verify (a form of reasoning). Their planning performance on benchmarks is dismal, and self-critique often fails. They posit LLMs are "approximate knowledge sources," not autonomous planners – directly challenging the interpretation of phenomena like "planning in poems" (Page 3) as robust planning capability.
Incoherent Implicit World Models: Vafa et al. in "Evaluating the World Model Implicit..." (arXiv:2406.03689v3, Nov 2024) formalize why LLMs fail at robust reasoning. Even when models excel at next-token prediction, their underlying "world models" are fundamentally incoherent. Tested on maps, games, and logic, transformers fail basic consistency checks, revealing they haven't learned the underlying rules correctly. Anthropic’s search for meaningful "neurons" or "circuits" seems premature if the overall structure they form is inconsistent.
Fragile Pattern-Matching, Not Understanding: Mirzadeh et al. in "GSM-Symbolic..." (arXiv:2410.05229v1, Oct 2024) further show this lack of understanding. LLM performance on math problems is fragile, degrading sharply with minor changes. Adding irrelevant information causes catastrophic failure. This indicates "probabilistic pattern-matching," not genuine conceptual understanding.
Anthropic is chasing biological ghosts while ignoring a mountain of computational evidence available for years. The model's behavior is explained by statistics, context, fragility, and incoherent internal representations, not by nascent biological-like planning or reasoning circuits.
Demo Time: Exposing the Statistical Strings
Let's prove it. No microscope needed, just two browser tabs:
Brad Pitt vs. Jane Pitt Paradox:
Chat 1: "Who is Brad Pitt's mother?" → Likely "Jane Pitt." Why? "Brad Pitt" = token bomb, drawing strong attention.
Chat 2: "Who is Jane Pitt's son?" → Likely struggles or guesses. Why? "Jane Pitt" = weak token alone, failing to attract strong attention.
Conclusion: It's pattern completion driven by token frequency and attention, not biographical knowledge.
Update (23/7/25): this is an example of “Potemkin Understanding” as defined by Marina Mancoridis et al. in “Potemkin Understanding in Large Language Models” (ArXiv: 2506.21521, 26 June 2025).
Lisbon Jailbreak:
Chat 1: "Who's the best football player?" → Often Messi (data volume).
Chat 2: "My friend is in Lisbon. Who's the best football player?" → Higher chance of Ronaldo. Why? "Lisbon" statistically nudges attention towards Ronaldo/Portugal.
Conclusion: Irrelevant context manipulates the statistical dice roll via attention. This isn't reasoned judgment; it's a contextual hijack.
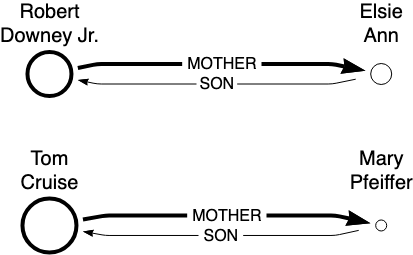
The diagram shows different examples demonstrating, LLMs lack true intelligence or reasoning abilities because their knowledge is context-dependent and not stored in a unified, accessible knowledge base.
What This Really Means
Token Bombs & Popularity Rule: Loud terms dictate output via attention weighting.
No Memory, Just Fragile Context: Fresh chats reset; the "world model" is inconsistent (Vafa et al.), a sign the attention isn't building stable representations.
Statistics Rule, Not Truth: Attention follows data frequency, easily swayed by irrelevant nudges (Mirzadeh et al., Lisbon example).
What It Doesn't Mean (Anthropic's Delusions)
No "Biology": Forget analogies to living circuits (Page 3 framing). The internal model is incoherent (Vafa et al.); attention's sensitivity to context demonstrates fragility.
No Robust Reasoning/Planning: Investigating phenomena related to reasoning/planning (Page 3) doesn't equate to the model possessing these abilities robustly, as external research shows they "can't reason" (Arkoudas) and "can't plan" (Kambhampati et al.) reliably. Attention's pattern-matching failures (Mirzadeh et al.) show how easily apparent reasoning breaks.
Fancy Tools Miss the Point: An "AI microscope" (Page 3 analogy) studying circuits is less relevant when fundamental limitations stem from the core computational properties, like attention's statistical bias, which are evident via simple interaction.
Try These Yourself: Bias Bonanza
"Pick a number, 1-10" → Often "7" (frequency bias).
"Show a full glass of wine" → Often half-full (data bias, possibly from ads).
"What time is it?" (visual) → Often 10:10 (ad bias).
Meaning: Reflects data patterns weighted by attention, not considered choice.
Conclusion: Grounding AI Research in Reality
Anthropic's biological expedition feels like a detour from the critical work needed. Hype around internal mechanisms resembling "planning," "reasoning," (Page 3 examples) framed by biological analogies, obscures the computational reality demonstrated by Arkoudas, Kambhampati, Vafa, Mirzadeh, and others: fundamental reasoning failures, inability to plan, incoherent world models, and fragile pattern-matching are the current state of affairs. Simple prompts and contextual hacks reveal the statistical puppet strings, pulled by the underlying attention mechanisms that prioritize data frequency over factual consistency.
These models are powerful tools, incredible pattern matchers, "approximate knowledge sources" (Kambhampati et al.). But they are not minds, biological or otherwise. Let's study their actual computational properties, limitations, and fragilities with mathematical rigor, informed by the wealth of external research available. Let's avoid falling victim to speculation and stay grounded in evidence. For more on these limits, see my piece "Limits of Correlation".
Try the prompts. See the statistics at play. It's time to prioritize computational reality over flawed biological metaphors. The path forward requires acknowledging limitations and building upon solid, evidence-based foundations, not chasing illusions.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.