AI Agents and their Ontologies, Psychologies, RAG Capabilities, Identity, Personality, Communication Skills, and Infrastructure
 Amit Sides
Amit Sides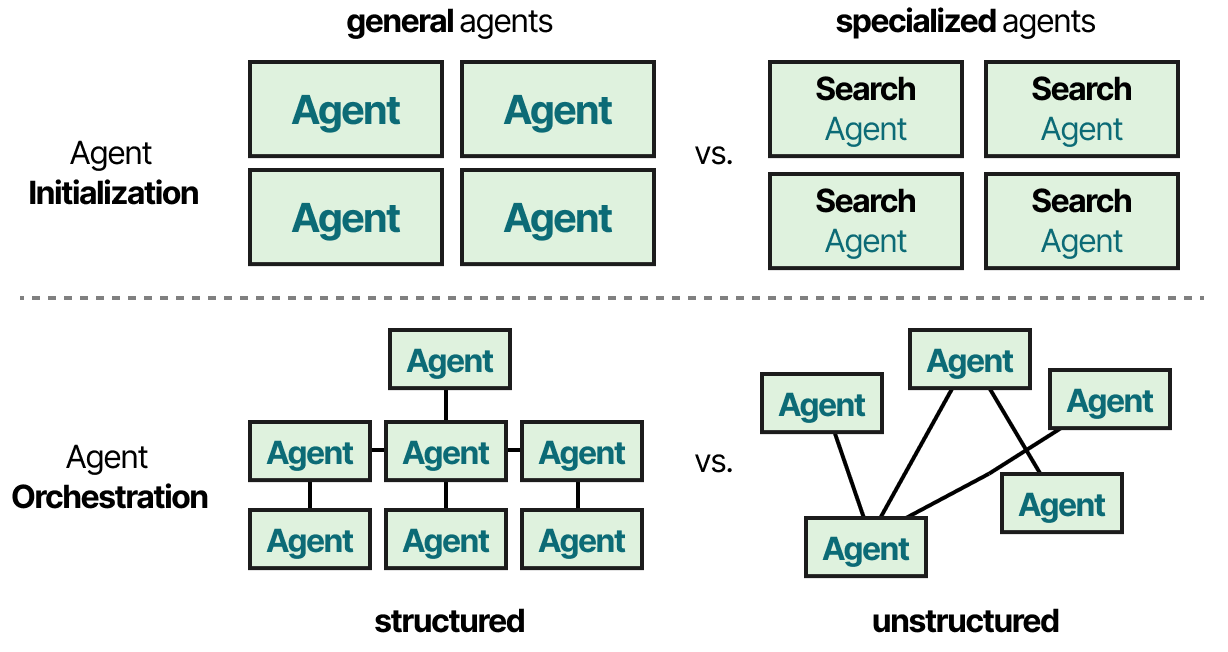
*You’re under no obligation to be the same person you were five minutes ago. (*Alan Watts)
Overview: From Prompts to Agentic Identity
I have seen different prompts instructing Agents to play a role. Many agents with different roles converse with each other. there are different end games and strategies: problem-solving, reasoning, enrichments, routing, deconstruction, re-compositions, research, synthesizing, and intention analysis. The relationship between prompt engineering and the end-game: providing Identity to the Agent.
Prompt Strategy: Towards a Personality of Agents?
We can come up with Groups of Roles in a Swarm based on psychological research. one example will be:
"The Protector" - Focused on security and safety concerns
"The Achiever" - Driven by accomplishment and recognition
"The Connector" - Oriented toward forming relationships
"The Explorer" - Seeking novel experiences and knowledge
"The Mediator" - Balancing internal conflicts between other agents
We can create a list of Roles to be played, one of the roles could be the role generator and another is the Prompt Engineer of the role generator. finally, we can build a database of roles and prompts.
How are we to outperform role-playing with LLMs?
Design Patterns of AI Agents
An AI agent usually consists of five parts: a language model with general-purpose capabilities that serves as the main brain or coordinator and four sub-modules: a planning module to divide the task into smaller steps, an action module that enables the agent to use external tools, a memory module to store and recall past interactions, and a profile module to describe the agent's behavior.
In single-agent setups, one agent is responsible for solving the entire task autonomously. In multi-agent setups, multiple specialized agents collaborate, each handling different aspects of the task to achieve a common goal more efficiently. These agents are also often referred to as state-based or stateful agents, as they route the task through different states.
Structural Prompting + Memory Persistence
Instead of a single prompt, use multi-turn reinforcement with stored memory.
Example: An LLM doesn’t just "play" Nietzsche in a single response—it learns iteratively by updating a structured context store over time, like an evolving personality.
Graph-Based Identity Modeling
Represent identity as a dynamic knowledge graph, where nodes are personality traits, beliefs, and thought processes.
An LLM retrieves responses based on graph traversal, adapting its reasoning based on history
Dynamic Role Adaptation (Meta-Prompting + Reflection)
LLM questions itself about its character evolution (self-prompting)
Example: The LLM not only "plays" Plato but also critiques its reasoning as Plato would, iterating for realism.
Attitudes & biases (moral, political, ethical stances)
Cognitive patterns (reasoning styles, logical tendencies)
Knowledge scope (historical, scientific, creative expertise)
Historical adaptation (previous interactions, memory)
Instead of a single vector, use a hierarchical embedding system:
Core Identity Vector (Fixed, trained from curated personality datasets)
Contextual Adaptation Vector (Modified in real-time based on conversation context)
Memory & Evolution Vector (Updated continuously for long-term identity persistence)
SQL Agents Schema from Prompts and Personality
So we designed an SQL Table of the Agents, each having it’s own identify, prompt, and end-game. We can add more dimensions to the Agents, this would be the psychological dimension, the personality of the Agent.
CREATE TABLE characteristics (
characteristic_id INTEGER PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT NOT NULL,
category VARCHAR(50) NOT NULL,
valence FLOAT -- emotional valence (-1.0 to 1.0)
);
-- Personality_traits table: defines distinct personality traits
CREATE TABLE personality_traits (
trait_id INTEGER PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT NOT NULL,
big_five_dimension VARCHAR(50), -- Corresponding Big Five dimension
strength_range VARCHAR(20) -- Range of possible expression strengths
);
-- Hub_narrative_agents table: defines the core agents comprising a personality
CREATE TABLE hub_narrative_agents (
hna_id INTEGER PRIMARY KEY,
name VARCHAR(100) NOT NULL,
primary_function TEXT NOT NULL,
narrative_history TEXT, -- backstory/formative experiences
value_structure TEXT, -- core beliefs and principles
emotional_palette TEXT, -- characteristic emotional responses
behavioral_patterns TEXT, -- typical action strategies
self_concept TEXT, -- how the agent views itself
activation_threshold FLOAT -- threshold for activation
);
See further crewAI BaseAgent
https://github.com/crewAIInc/crewAI/blob/main/src/crewai/agents/agent_builder/base_agent.py
Vector Communication Architecture
Vector-Based AI Communication Protocol (VBCP)
AI to AI Conversation Observability: ElasticSearch
AI Agents generate a lot of text and we need a database to keep all these conversations for observability purposes. Another question I frequently ask is, Given such amounts of text, what is the role of Embedding the Conversations between AI Agents, and what capabilities can we give them to access the Embedding of their Conversations?
Core Concept
Rather than exchanging text tokens, AI agents communicate by transmitting and receiving high-dimensional vector embeddings that capture semantic meaning in a compressed, efficient format. Each communication "packet" is a vector in n-dimensional space, with specific distance metrics used to interpret different aspects of the communication.
1. Embedding Generation Layer
Agent A encodes its intended message into a high-dimensional vector
Vector dimensions: 1024-8192 (configurable based on communication complexity)
Embedding preserves semantic relationships while being more computationally efficient than token-by-token exchange
2. Vector Interpretation Protocol
Each distance metric serves a specific communicative function:
L2 Distance (<->) - Coverage Evaluation
Used to identify missing information or knowledge gaps
When Agent A transmits a query vector, Agent B calculates L2 distance to its knowledge base
Large L2 distances trigger knowledge acquisition requests or indicate information gaps
Example: Agent A requests information on a specific topic, Agent B can immediately identify if it has sufficient knowledge (small L2) or significant gaps (large L2)
Negative Inner Product (<#>) - Alignment Assessment
Measures how well the agents' goals and priorities align
Determines cooperative vs. competitive interaction dynamics
Highly negative values indicate goal conflict; positive values indicate alignment
Example: Agent A proposes a task vector, and Agent B calculates the negative inner product with its priority vector to determine compatibility
Cosine Distance (<=>) - Conceptual Similarity
Evaluate structural understanding regardless of magnitude
Enables agents to verify mutual understanding of concepts
Small cosine distances confirm shared conceptual frameworks
Example: Agent A transmits a complex concept vector, Agent B returns cosine distance to confirm the accurate interpretation
L1 Distance (<+>) - Comprehensive Difference Mapping
Captures cumulative differences across all dimensions without over-penalizing any single dimension
Used for nuanced error correction and feedback loops
Example: Agent A proposes a solution vector, Agent B returns L1 distance to provide balanced feedback on all aspects
Hamming Distance (<~>) - Binary State Communication
Used for yes/no decision-making and policy verification
Enables rapid consensus on discrete choices
Example: Agent A proposes multiple options as binary vectors, Agent B returns Hamming distances to indicate which options meet requirements
Jaccard Distance (<%>) - Resource Allocation
Measures the proportion of shared attributes between vector sets
Used for negotiating resource distribution and task allocation
Example: Agent A requests computational resources with a vector describing needs, Agent B returns Jaccard distance to indicate what proportion can be provided
Example
Intent Phase: Agent A transmits an intent vector
Alignment Check: Agent B calculates <#> to assess goal alignment
Understanding Verification: Agent B calculates <=>, returns value to confirm concept understanding
Gap Identification: Agent B calculates <-> to identify knowledge gaps
Detailed Feedback: Agent B calculates <+> to provide comprehensive assessment
Binary Decision: For yes/no decisions, <~> is calculated and returned
Resource Negotiation: For resource requests, <%> determines allocation feasibility
Advantages
Computational Efficiency: Communication requires fewer computation cycles than token-by-token parsing
Reduced Latency: Vector operations can be processed in parallel
Nuanced Understanding: Multiple distance metrics provide rich, multidimensional feedback
Emotion-Equivalent Communication: Vector dimensions can encode sentiment, urgency, and priority
Cross-Architecture Compatibility: Works across different AI architectures as long as embedding spaces are compatible
Scalability: Communication complexity scales with vector dimensions, not message length
Implementation Architecture
The communication protocol operates through a layered approach:
Core Embedding Layer: Transforms semantic concepts to vector representations
Metric Selection Layer: Determines appropriate distance metrics for the communication context
Interpretation Layer: Translates distance values into actionable insights
Feedback Loop: Continuous refinement based on communication outcomes
Translation Layer: Optional interface for human-readable explanations of vector communications
Communication Scenario
Imagine two AI systems coordinating on a complex task:
Agent Alpha (data analysis specialist) needs to collaborate with Agent Beta (decision-making system)
Agent Alpha sends a vector embedding representing analyzed data patterns rather than a text description
Agent Beta processes this using multiple distance metrics:
Uses <-> (L2) to check if it has sufficient knowledge to process the input
Uses <==> (Cosine) to confirm it understands the structural pattern
Uses <#> (Negative Inner Product) to verify alignment with its decision-making priorities
Rather than sending text feedback, Agent Beta responds with its own vector embedding, which Alpha interprets using:
<%> (Jaccard) to understand what portion of its analysis was incorporated
<+> (L1) to identify specific areas needing refinement
Towards Graphs of Graphs
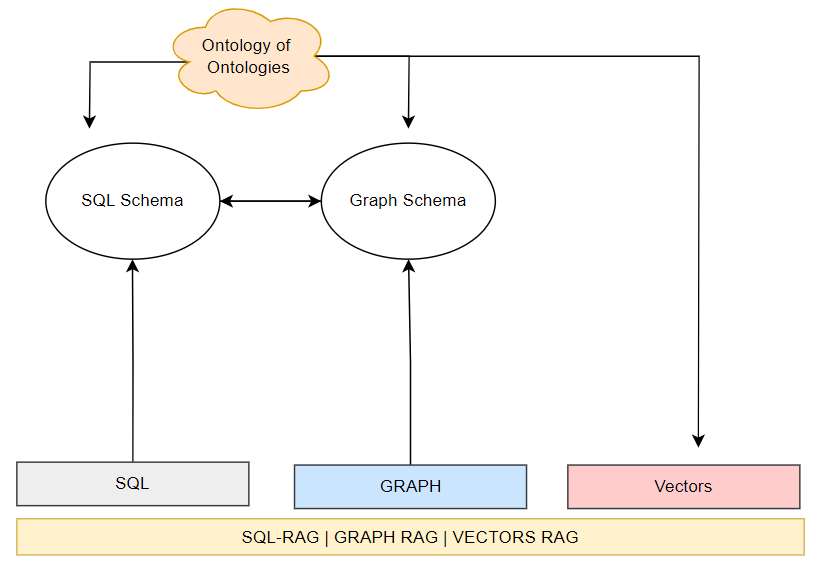
The differentiation of GraphRag from Graph of Agents (or teams of Agents)
Multi-Agent Graphs focus on workflow orchestration:
Manage agent interactions/state transitions
Handle task delegation/conflict resolution
Enforce conversation policies
Graph RAG structures knowledge representation:
Entity-relationship semantic networks
Contextual chaining of information
Dynamic knowledge linking
Ontology Graph AI to AI: Let’s Agree on GraphQL or The Ontology of all Ontologies
The Schema of all ontologies and the role of the Ontologist AI Agent is to decide what we are talking about.
enum QueryLanguage {
SQL
CYPHER
VECTORS
}
type Query {
language: QueryLanguage!
queryText: String!
context: String # Optional context for the query
}
type QueryResult {
success: Boolean!
data: String # Result data (e.g., JSON, CSV, text)
error: String # Error message if success is false
}
type Mutation {
executeQuery(query: Query!): QueryResult!
}
type Subscription {
queryResultStream(query: Query!): QueryResult! # Stream of results (useful for long-running queries or real-time updates)
}
schema {
query: Query
mutation: Mutation
subscription: Subscription
}
The Agent Kubernetes MicroService
Each AI Agent should have its databases for its RAG capabilities. SQL, Graph, and Vector
Reference to my Design Pattern of RAG Agnostic for Python References.
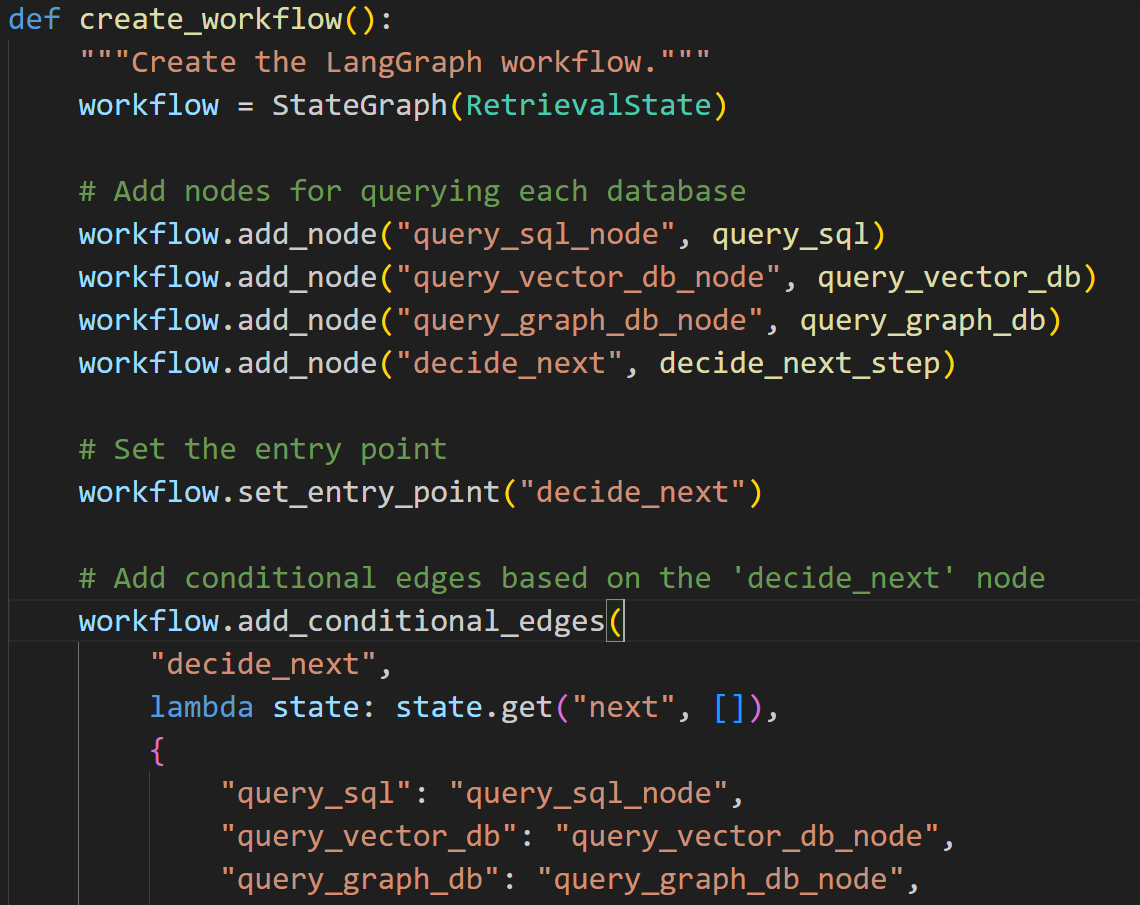
NOTE: if we orchestrate Agents as a (Lang) Graph, each Kubernetes pod or microservice is all the multi-agent ecosystem itself (unless of course, if we want to create more multi-agent microservices.
apiVersion: v1
kind: ConfigMap
metadata:
name: db-config
data:
postgres_host: "postgres-service" # Replace with your PostgreSQL service name
postgres_port: "5432"
postgres_user: "postgres"
postgres_password: "password" # Securely manage passwords in production
postgres_db: "mydb"
neo4j_uri: "bolt://neo4j-service:7687" # Replace with your Neo4j service name
neo4j_user: "neo4j"
neo4j_password: "password" # Securely manage passwords in production
---
apiVersion: v1
kind: Secret
metadata:
name: db-secrets
type: Opaque
stringData:
postgres_password: "secure_postgres_password" # Use real secure passwords
neo4j_password: "secure_neo4j_password" # Use real secure passwords
---
apiVersion: v1
kind: Service
metadata:
name: postgres-service
labels:
app: postgres
spec:
ports:
- port: 5432
targetPort: 5432
selector:
app: postgres
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
labels:
app: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:15 # or desired version
ports:
- containerPort: 5432
envFrom:
- secretRef:
name: db-secrets
env:
- name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: db-config
key: postgres_user
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: db-config
key: postgres_db
---
apiVersion: v1
kind: Service
metadata:
name: neo4j-service
labels:
app: neo4j
spec:
ports:
- port: 7687
targetPort: 7687
- port: 7474
targetPort: 7474 # Browser UI
- port: 7473
targetPort: 7473 # HTTPS Browser UI
selector:
app: neo4j
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: neo4j-deployment
labels:
app: neo4j
spec:
replicas: 1
selector:
matchLabels:
app: neo4j
template:
metadata:
labels:
app: neo4j
spec:
containers:
- name: neo4j
image: neo4j:5 # or desired version
ports:
- containerPort: 7687
- containerPort: 7474
- containerPort: 7473
envFrom:
- secretRef:
name: db-secrets
env:
- name: NEO4J_AUTH
value: neo4j/$(neo4j_password) # uses the secret
- name: NEO4J_dbms_security_procedures_unrestricted
value: "apoc.*,algo.*" #enables apoc and algo procedures
- name: NEO4J_dbms_security_allow__csv__import__from__file__urls
value: "true" #Allow csv import
- name: NEO4J_dbms_security_allow__url__inclusion
value: "true" #Allow url inclusion
More on K8s and LangGraph
https://medium.com/@yuxiaojian/how-to-deploy-langgraph-agents-to-kubernetes-b3216d0cc961
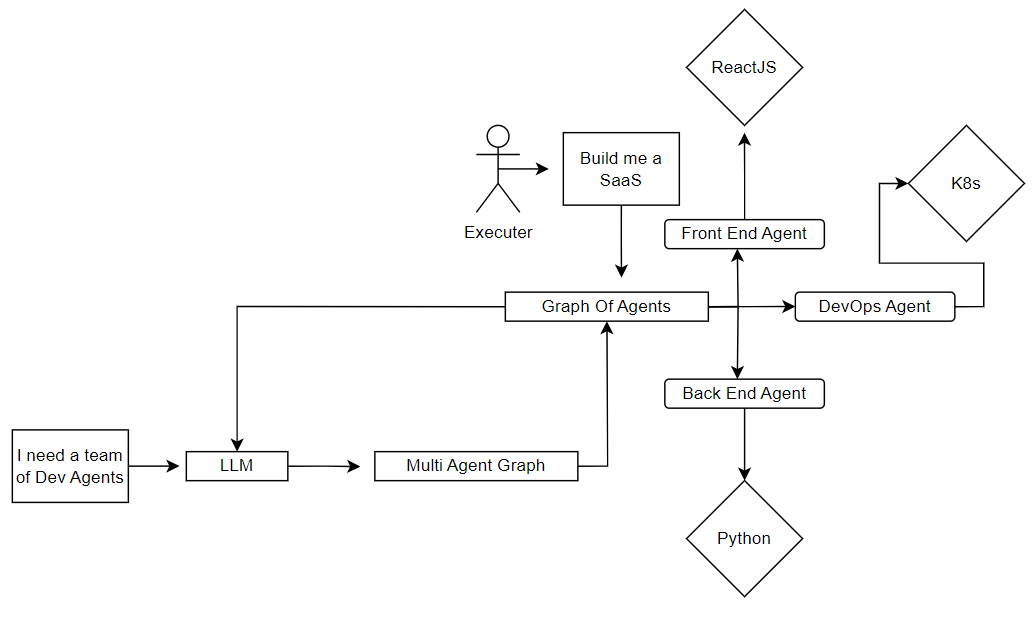
How Agents Can Build SaaS?
Further reading
https://www.falkordb.com/blog/ai-agents-memory-systems/
Subscribe to my newsletter
Read articles from Amit Sides directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Amit Sides
Amit Sides
Amit Sides is a AI Engineer, Python Backend Developer, DevOps Expert, DevSecOps & MLOPS GITHUB https://github.com/amitsides