Kanister Framework: Simplifying Data Protection in Kubernetes Environments
 Jayakumar Sakthivel
Jayakumar Sakthivel
Introduction
In the complex world of container orchestration, data protection and management remain critical challenges for DevOps and platform engineering teams. The Kanister Framework emerges as a powerful solution, specifically designed to address data management complexities in Kubernetes environments.
Understanding Kanister Framework
What is Kanister?
Kanister is an open-source framework that provides a comprehensive approach to managing stateful application data in Kubernetes. It enables application-consistent data protection, backup, and recovery across various storage systems and cloud platforms.
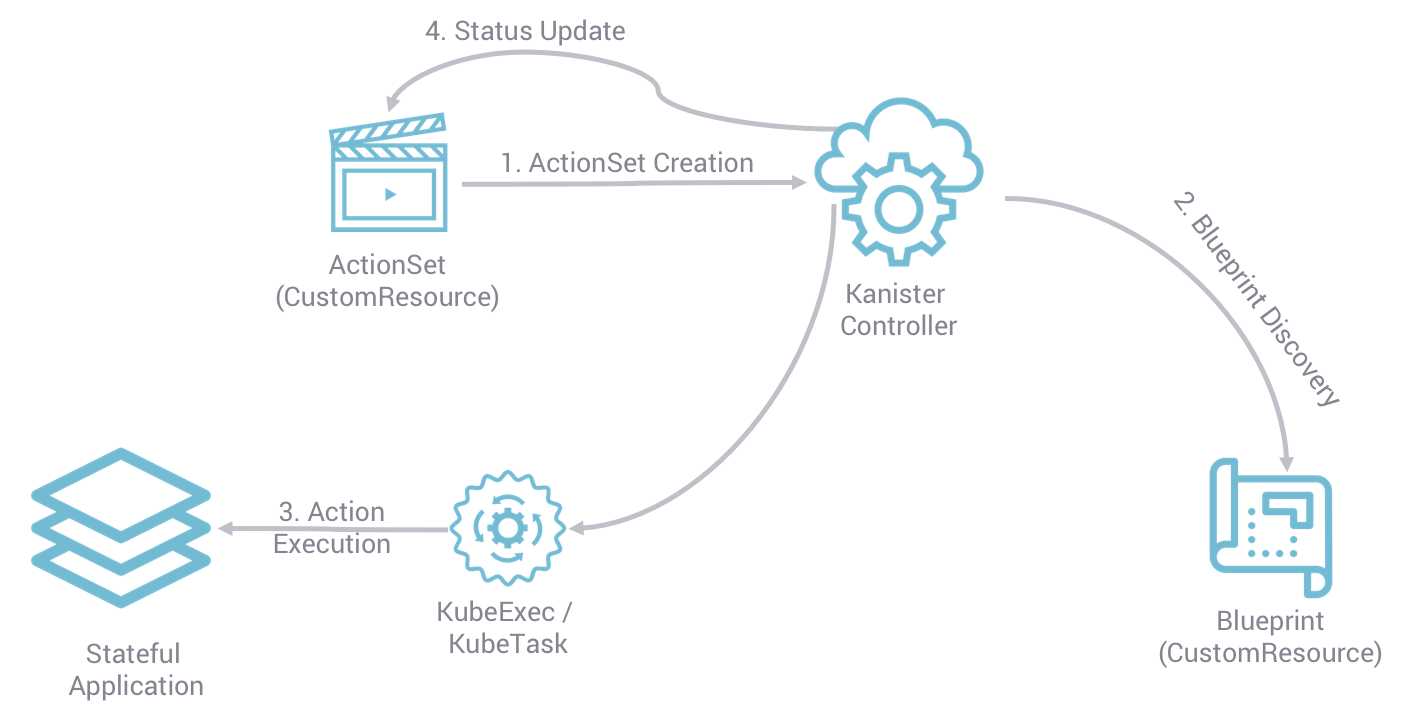
Key Features and Benefits
Application-Aware Backup and Restore
Understands application-specific data protection requirements
Supports complex stateful applications with intricate data dependencies
Ensures consistent snapshots and backups across distributed systems
Multi-Cloud and Multi-Storage Support
Works seamlessly with diverse storage backends
Compatible with cloud-native storage solutions
Supports various cloud providers and on-premises infrastructure
Kubernetes-Native Approach
Implemented as Custom Resource Definitions (CRDs)
Native integration with Kubernetes ecosystem
Utilizes Kubernetes' declarative configuration model
Real-World Problem Solving
Challenges Addressed by Kanister
Data Consistency: Ensuring application data integrity during backup and restore processes
Complex Stateful Applications: Managing backup for databases, message queues, and distributed systems
Disaster Recovery: Providing reliable recovery mechanisms for mission-critical applications
Vendor Lock-in Prevention: Supporting multiple storage and cloud platforms
Practical Proof of Concept: MySQL Backup and Restore
Prerequisites
Kubernetes Cluster (Minimum version 1.16+)
kubectl command-line tool
Helm (version 3.x)
Persistent Storage Class configured in your Kubernetes cluster
Step 1: Install Kanister Operator
First, add the Kanister Helm repository and install the operator:
# Add Kanister Helm Repository
helm repo add kanister https://charts.kasten.io/
helm repo update
# Install Kanister Operator
kubectl create namespace kanister
helm install kanister-operator kanister/kanister-operator -n kanister
Step 2: Verify Kanister Operator Installation
# Check Kanister Operator Pods
kubectl get pods -n kanister
# Verify CRD Installation
kubectl get crds | grep kanister
Step 3: Prepare MySQL Deployment with Persistent Volume
Create a MySQL deployment with persistent storage:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-app
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pvc
Step 4: Create MySQL Secret
# Create MySQL Root Password Secret
kubectl create secret generic mysql-secret \
--from-literal=password=YourStrongPasswordHere
Step 5: Deploy MySQL and Create Sample Database
# Apply MySQL Deployment
kubectl apply -f mysql-deployment.yaml
# Wait for Pod to be Ready
kubectl get pods
# Connect to MySQL and Create Sample Database
kubectl exec -it $(kubectl get pods -l app=mysql -o jsonpath='{.items[0].metadata.name}') -- mysql -u root -p
Inside MySQL prompt:
CREATE DATABASE kanister_demo;
USE kanister_demo;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
INSERT INTO users (name, email) VALUES
('John Doe', 'john@example.com'),
('Jane Smith', 'jane@example.com');
Step 6: Create Kanister Blueprint for MySQL Backup
apiVersion: cr.kanister.io/v1alpha1
kind: Blueprint
metadata:
name: mysql-backup-blueprint
actions:
backup:
phases:
- func: KubeExec
name: takeConsistentBackup
args:
namespace: "{{ .Namespace }}"
pod: "{{ index .Object.metadata.labels \"app\" }}"
container: mysql
command:
- bash
- -o
- pipefail
- -c
- mysqldump -u root -p$MYSQL_ROOT_PASSWORD kanister_demo > /var/lib/mysql/backup.sql
- func: KubeTask
name: createSnapshot
args:
image: kanisterio/kanister-kubectl:0.85.0
namespace: "{{ .Namespace }}"
command:
- bash
- -o
- pipefail
- -c
- kubectl get pvc mysql-pvc -o yaml
restore:
phases:
- func: KubeExec
name: restoreDatabase
args:
namespace: "{{ .Namespace }}"
pod: "{{ index .Object.metadata.labels \"app\" }}"
container: mysql
command:
- bash
- -o
- pipefail
- -c
- mysql -u root -p$MYSQL_ROOT_PASSWORD kanister_demo < /var/lib/mysql/backup.sql
Step 7: Create Backup ActionSet
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
name: mysql-backup
spec:
actions:
- name: backup
blueprint: mysql-backup-blueprint
object:
kind: Deployment
name: mysql-app
namespace: default
Step 8: Trigger Backup
kubectl create -f mysql-backup-actionset.yaml
Step 9: Simulate Disaster Recovery
Delete existing database
Restore from Kanister backup
# Delete Database
kubectl exec -it mysql-pod -- mysql -u root -p
DROP DATABASE kanister_demo;
exit;
# Create Restore ActionSet
apiVersion: cr.kanister.io/v1alpha1
kind: ActionSet
metadata:
name: mysql-restore
spec:
actions:
- name: restore
blueprint: mysql-backup-blueprint
object:
kind: Deployment
name: mysql-app
namespace: default
Important Considerations
Always test backups in non-production environments first
Implement proper access controls and encryption
Regularly verify backup and restore procedures
Monitor backup job logs for any potential issues
Conclusion
This comprehensive guide demonstrates Kanister's powerful capabilities in managing stateful application data within Kubernetes environments. By providing application-consistent backup and restore mechanisms, Kanister simplifies complex data protection strategies.
Subscribe to my newsletter
Read articles from Jayakumar Sakthivel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jayakumar Sakthivel
Jayakumar Sakthivel
As a DevOps Engineer, I specialize in streamlining and automating software delivery processes utilizing advanced tools like Git, Terraform, Docker, and Kubernetes. I possess extensive experience managing cloud services from major providers like Amazon, Google, and Azure. I excel at architecting secure CI/CD pipelines, integrating top-of-the-line security tools like Snyk and Checkmarx to ensure the delivery of secure and reliable software products. In addition, I have a deep understanding of monitoring tools like Prometheus, Grafana, and ELK, which enable me to optimize performance and simplify cloud migration journeys. With my broad expertise and skills, I am well-equipped to help organizations achieve their software delivery and cloud management objectives.