Resize Redo Logs em um ambiente com Standby
 Sergio Bender
Sergio Bender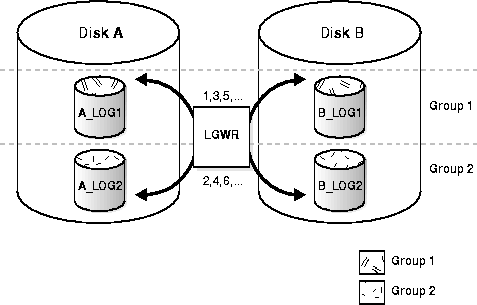
O que são os Redo Log Files?
Os Redo Log Files são estruturas físicas dentro do banco de dados que registram todas as alterações feitas nos dados. Quando uma transação é executada (por exemplo, uma inserção, atualização ou exclusão), essas mudanças são gravadas nos arquivos de redo log. Essa gravação ocorre primeiro no Buffer de Redo Log em memória e, posteriormente, nos arquivos físicos no disco.
Benefícios de Ajustar os Redo Log Files
Recuperação de Transações: Os Redo Log Files permitem que o banco de dados recupere transações incompletas ou interrompidas. Se ocorrer uma falha no sistema (como uma queda de energia), o banco de dados pode usar os registros de redo para refazer as alterações não confirmadas e manter a consistência dos dados.
Roll Forward: Os Redo Log Files também são usados no processo de Roll Forward durante a recuperação. Isso significa que eles aplicam as alterações registradas nos arquivos de redo log para trazer o banco de dados de volta a um estado consistente após uma falha.
Tamanho Adequado: Ajustar corretamente o tamanho dos Redo Log Files é crucial. Se forem muito pequenos, eles podem encher rapidamente e causar problemas de desempenho. Se forem muito grandes, podem desperdiçar espaço em disco. Portanto, monitorar os tempos de gravação e determinar um tamanho próximo ao ideal para os Redo Log Files é essencial1.
Alternância Eficiente: Os grupos de Redo Log Files alternam ciclicamente entre seus membros. Manter um tempo de alternância adequado (geralmente em torno de 15 minutos) garante que o sistema funcione de maneira eficiente e evita gargalos1.
Em resumo, os Redo Log Files são os guardiões das transações e da integridade dos dados. Ajustá-los corretamente é fundamental para um banco de dados saudável e resiliente.
\>> Servidor Primario <<
1 - Verificar o status do banco de dados
select status,instance_name,database_role from v$database,v$instance;
2- Verificar os redolog file
select group#,sum(bytes/1024/1024)"Size in MB" from v$log group by group#;
3- Verificar os standby Redologs
select group#,sum(bytes/1024/1024)"Size in MB" from v$standby_log group by group#;
4- Verifique se o parâmetro standby_file_management está configurado como AUTO ou MANUAL no banco de dados standby. Se não estiver definido como MANUAL, configure-o.
show parameter standby_file_management
alter system set standby_file_management=manual;
5- Passos para excluir e adicionar novos arquivos de redologs.
A Oracle recomenda que os arquivos de redo log sejam criados em discos separados. Isso ajuda a distribuir a carga de E/S (entrada/saída) e melhora o desempenho geral do banco de dados. Ao separar os arquivos de redo log, você evita possíveis gargalos e garante que a gravação de logs não afete outras operações de E/S no mesmo disco.
No exemplo específico do banco 17P, há uma limitação na camada de E/S para discos pequenos na plataforma Azure. Devido a essa restrição, estou colocando os arquivos de redo log no mesmo disco que os arquivos de archive e backup.
Essa abordagem é uma solução prática para contornar a limitação de tamanho dos discos e garantir que o banco de dados funcione de maneira eficiente.
select group#, bytes/1024/1024 as MB, members, status from v$log ;
ALTER DATABASE DROP LOGFILE GROUP 1;
ALTER DATABASE DROP LOGFILE GROUP 2;
ALTER DATABASE DROP LOGFILE GROUP 3;
ALTER DATABASE DROP LOGFILE GROUP 4;
ALTER DATABASE DROP LOGFILE GROUP 5;
select group#, bytes/1024/1024 as MB, members, status from v$log ;
alter system switch logfile;
alter system checkpoint;
alter database add logfile group 1 ('/oraarch/eusouodba/redo1/redo1a.redo', '/backup/eusouodba/redo2/redo1b.redo') size 2G;
alter database add logfile group 2 ('/oraarch/eusouodba/redo1/redo2a.redo', '/backup/eusouodba/redo2/redo2b.redo') size 2G;
alter database add logfile group 3 ('/oraarch/eusouodba/redo1/redo3a.redo', '/backup/eusouodba/redo2/redo3b.redo') size 2G;
alter database add logfile group 4 ('/oraarch/eusouodba/redo1/redo4a.redo', '/backup/eusouodba/redo2/redo4b.redo') size 2G;
alter database add logfile group 5 ('/oraarch/eusouodba/redo1/redo5a.redo', '/backup/eusouodba/redo2/redo5b.redo') size 2G;
6- Passos para excluir e adicionar novos arquivos de Standby logfiles.
select group#,status from v$standby_log;
alter database drop standby logfile group 6;
alter database drop standby logfile group 7;
alter database drop standby logfile group 8;
alter database drop standby logfile group 9;
alter database drop standby logfile group 10;
alter database drop standby logfile group 11;
alter database add standby logfile group 16 ('/oraarch/eusouodba/redo1/stblog16.redo') size 2G;
alter database add standby logfile group 17 ('/oraarch/eusouodba/redo1/stblog17.redo') size 2G;
alter database add standby logfile group 18 ('/oraarch/eusouodba/redo1/stblog18.redo') size 2G;
alter database add standby logfile group 19 ('/oraarch/eusouodba/redo1/stblog19.redo') size 2G;
alter database add standby logfile group 20 ('/oraarch/eusouodba/redo1/stblog20.redo') size 2G;
alter database add standby logfile group 21 ('/oraarch/eusouodba/redo1/stblog21.redo') size 2G;
\>> Servidor Standby<<
7- Cancelar o processo de recuperação gerenciada em um banco de dados standby Oracle
alter database recover managed standby database cancel;
8- Verificar os arquivos de redologs do servidor de standby
select group#,status from v$log;
9- Passos para excluir e adicionar novos arquivos de redologs.
alter system set standby_file_management=manual;
alter database drop logfile group 1;
alter database drop logfile group 2;
alter database drop logfile group 3;
alter database drop logfile group 4;
alter database drop logfile group 5;
-- Se o status estiver como clearing or using lets clear it manually before dropping the group.
alter database clear logfile group 2;
select group#,sum(bytes/1024/1024)"size in MB" from v$log group by group#;
select group#, bytes/1024/1024 as MB, members, status from v$log ;
alter system switch logfile;
alter system checkpoint;
alter database add logfile group 1 ('/oraarch/eusouodba/redo1/redo1a.redo', '/backup/eusouodba/redo2/redo1b.redo') size 2G;
alter database add logfile group 2 ('/oraarch/eusouodba/redo1/redo2a.redo', '/backup/eusouodba/redo2/redo2b.redo') size 2G;
alter database add logfile group 3 ('/oraarch/eusouodba/redo1/redo3a.redo', '/backup/eusouodba/redo2/redo3b.redo') size 2G;
alter database add logfile group 4 ('/oraarch/eusouodba/redo1/redo4a.redo', '/backup/eusouodba/redo2/redo4b.redo') size 2G;
alter database add logfile group 5 ('/oraarch/eusouodba/redo1/redo5a.redo', '/backup/eusouodba/redo2/redo5b.redo') size 2G;
10- Passos para excluir e adicionar novos arquivos de Standby log no banco de standby.
select group#,sum(bytes/1024/1024)"size in MB" from v$standby_log group by group#;
select group#,status from v$standby_log;
alter database drop standby logfile group 16;
alter database drop standby logfile group 17;
alter database drop standby logfile group 18;
alter database drop standby logfile group 19;
alter database drop standby logfile group 20;
alter database drop standby logfile group 21;
alter database add standby logfile group 16 ('/oraarch/eusouodba/redo1/stblog6.redo') size 2G;
alter database add standby logfile group 17 ('/oraarch/eusouodba/redo1/stblog7.redo') size 2G;
alter database add standby logfile group 18 ('/oraarch/eusouodba/redo1/stblog8.redo') size 2G;
alter database add standby logfile group 19 ('/oraarch/eusouodba/redo1/stblog9.redo') size 2G;
alter database add standby logfile group 20 ('/oraarch/eusouodba/redo1/stblog10.redo') size 2G;
alter database add standby logfile group 21 ('/oraarch/eusouodba/redo1/stblog11.redo') size 2G
;
Depois que todos os Redo Logs forem redimensionados no banco de dados primário e no banco de dados de espera
11- Ativar o parametro gerenciamento automático dos arquivos de redo log standby.
alter system set standby_file_management=auto;
12- Iniciar o processo de recuperação gerenciada do banco de dados standby.
alter database recover managed standby database disconnect from session using current logfile;
13- Verificar se o processo MPR esta ativo e aplicando archive no standby.
select process,status,sequence# from v$managed_standby;
14 - Verificar o gap dos archives.
--Primary:
select max(sequence#) from v$archived_log;
Standby:
select max(sequence#) from v$archived_log where applied='YES';
15- ajustar para 15min o tempo de recuperação em caso de falha
-- Gerar archive a cada 15min
show parameter FAST_START_MTTR_TARGET
alter system set FAST_START_MTTR_TARGET=900 scope=both
O parâmetro FAST_START_MTTR_TARGET (Mean Time To Recover) é uma configuração que controla a recuperação rápida de instâncias Oracle em caso de falha. Ele especifica o tempo alvo necessário para a recuperação de uma instância Oracle após uma falha de instância ou de mídia.
Para garantir a eficiência e a gestão adequada dos recursos do banco de dados, é considerada uma boa prática excluir regularmente os arquivos antigos de redo log. Ao contrário de alguns sistemas, o Oracle não executa essa tarefa automaticamente, deixando a responsabilidade para os administradores de banco de dados.
Uma vez identificados os arquivos que podem ser excluídos com segurança, é recomendável realizar uma cópia de segurança completa do banco de dados. Isso proporciona uma camada adicional de segurança caso ocorra algum problema durante o processo de exclusão.
Para facilitar execute esse comando e salve antes de iniciar o processo!
select * from v$logfile
Subscribe to my newsletter
Read articles from Sergio Bender directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by