Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
 Mike Young
Mike Young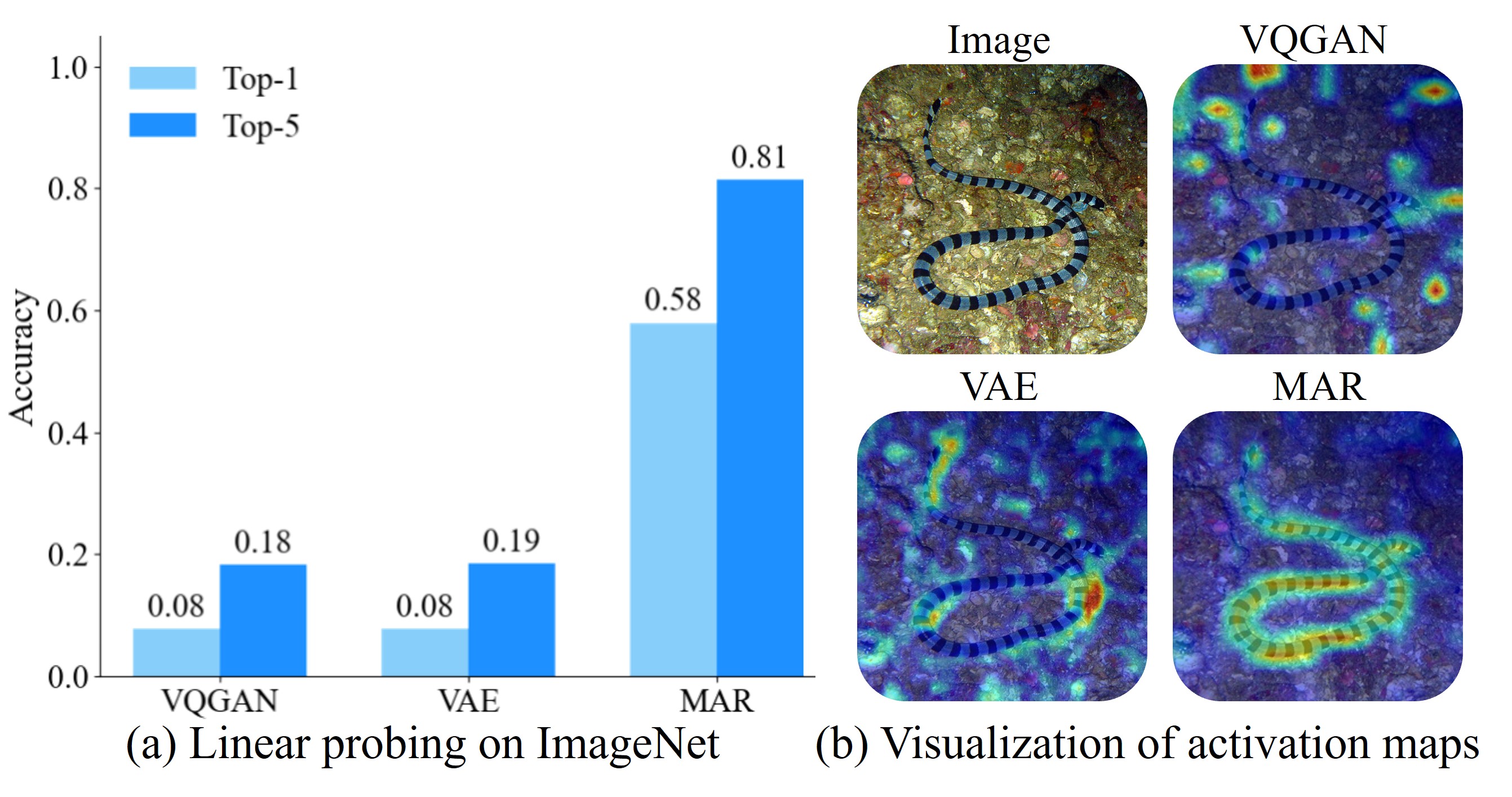
This is a Plain English Papers summary of a research paper called Harmonizing Visual Representations for Unified Multimodal Understanding and Generation. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Harmonizing visual representations is crucial for multimodal AI systems
- HarmonAI unifies multiple visual encoders into a single, effective model
- Combines strengths of various encoders (CLIP, Vit, etc.) through harmonization
- Delivers strong performance across understanding and generation tasks
- Outperforms models that use just one visual representation system
Plain English Explanation
Think of modern AI systems like superheroes with different visual powers. Some are great at understanding images broadly (like CLIP), while others excel at noticing fine details (like ViT). Currently, most AI systems choose just one of these visual systems, limiting their capabilities.
HarmonAI takes a different approach. Rather than picking one visual system, it creates a "superhero team" by bringing multiple visual encoders together. This is like having several experts with different specialties working together instead of relying on just one person's perspective.
The unified multimodal understanding approach has major advantages. Imagine trying to describe a complex scene - you'd want both the big picture and the details. HarmonAI can do this by harmonizing different visual "experts" to create a comprehensive understanding that's greater than what any single system could provide.
What makes HarmonAI special is how it integrates these different visual systems. Instead of just bolting them together, it carefully merges their outputs into a unified representation. This harmonization happens through specialized neural networks that learn how to blend these different visual languages effectively.
The result is an AI system that's more flexible and capable. It can tackle both understanding tasks (like answering questions about images) and generation tasks (like creating images from descriptions) with better performance than systems limited to a single visual representation.
Key Findings
The research demonstrates several important discoveries about harmonizing visual representations:
- HarmonAI outperforms single-encoder models across a wide range of tasks, showing that using multiple visual encoders provides significant benefits
- The system achieves strong performance in both understanding tasks (VQA, visual reasoning) and generation tasks (text-to-image)
- Cross-modal image synthesis benefits from the harmonized approach, with better quality outputs
- Different visual encoders contribute complementary strengths - CLIP provides robust high-level understanding while ViT captures more fine-grained visual details
- The approach scales effectively with additional encoders, suggesting future improvements as more specialized visual systems are integrated
The researchers conducted extensive experiments comparing HarmonAI against baseline models using only a single visual encoder. The results consistently showed that the harmonized approach delivered better performance, often by significant margins, across benchmarks for both understanding and generation capabilities.
Technical Explanation
HarmonAI tackles the fundamental challenge of integrating multiple visual representation systems through a novel architecture. The system begins with several pre-trained visual encoders (CLIP, ViT, and others) that process input images independently. Each encoder extracts different features - CLIP excels at semantic understanding, while others like ViT capture more detailed visual information.
The key innovation lies in the harmonization process. Rather than simply concatenating these different representations, HarmonAI uses a specialized harmonizer module with cross-attention mechanisms. This module learns to align and integrate the different visual representations into a unified embedding space that preserves the strengths of each encoder.
The vector quantized masked autoencoder approach helps maintain the distinct qualities of each visual representation while creating a coherent combined output. This harmonized representation then feeds into a large language model (LLM) backbone for both understanding and generation tasks.
For understanding tasks, the system processes the harmonized visual representation alongside text inputs through the LLM to produce responses. For generation tasks, the system reverses this flow, starting with text inputs and using the harmonized visual space to guide image creation.
The researchers evaluated HarmonAI on multiple benchmarks, including visual question answering (VQA), image captioning, and text-to-image generation. The architecture demonstrated consistent improvements over single-encoder baselines, validating the benefits of the harmonization approach.
Critical Analysis
While HarmonAI shows promising results, several limitations deserve consideration. First, the computational cost increases with each additional visual encoder, potentially limiting practical applications where efficiency is paramount. The researchers acknowledge this trade-off but don't fully address how to optimize for real-world deployment constraints.
The study also doesn't fully explore potential biases in the harmonization process. If certain encoders receive more weight in the harmonization, their inherent biases might be amplified rather than balanced out. Further work on ensuring fair representation across different visual systems seems necessary.
Another limitation is the reliance on pre-trained encoders. The unity by diversity representation learning approach depends on the quality of these individual encoders. If they contain fundamental limitations or biases, HarmonAI will inherit these issues. Future work might explore training the encoders alongside the harmonizer for more integrated optimization.
The paper also lacks extensive ablation studies to understand exactly how each encoder contributes to specific tasks. More granular analysis would help identify which visual systems are most valuable for particular applications, potentially allowing for more efficient specialized implementations.
Finally, the research focuses primarily on benchmarks rather than real-world applications. How well HarmonAI's approach transfers to complex, messy real-world data remains an open question that deserves further investigation.
Conclusion
HarmonAI represents a significant step forward in multimodal AI by demonstrating that harmonizing multiple visual representations creates more capable systems. Rather than viewing different visual encoders as competing approaches, this research shows the value of integrating their complementary strengths.
The Janus decoupling visual encoding strategy opens up new possibilities for more flexible AI systems that don't need to choose between different visual understanding approaches. This could lead to more adaptable systems that can handle a wider range of tasks and domains without specialization.
Looking ahead, this harmonization approach could extend beyond visual encoders to include other modalities like audio, touch, or even specialized domain encoders. The fundamental insight - that different representational systems can be harmonized rather than selected between - has broad implications for how we design AI systems.
As AI increasingly needs to operate in the complex, multimodal human world, approaches like HarmonAI that bridge different perceptual systems will likely become increasingly important. The ability to see the world through multiple "lenses" simultaneously appears to be a key step toward more human-like artificial intelligence.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.
Subscribe to my newsletter
Read articles from Mike Young directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by