Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
 Mike Young
Mike Young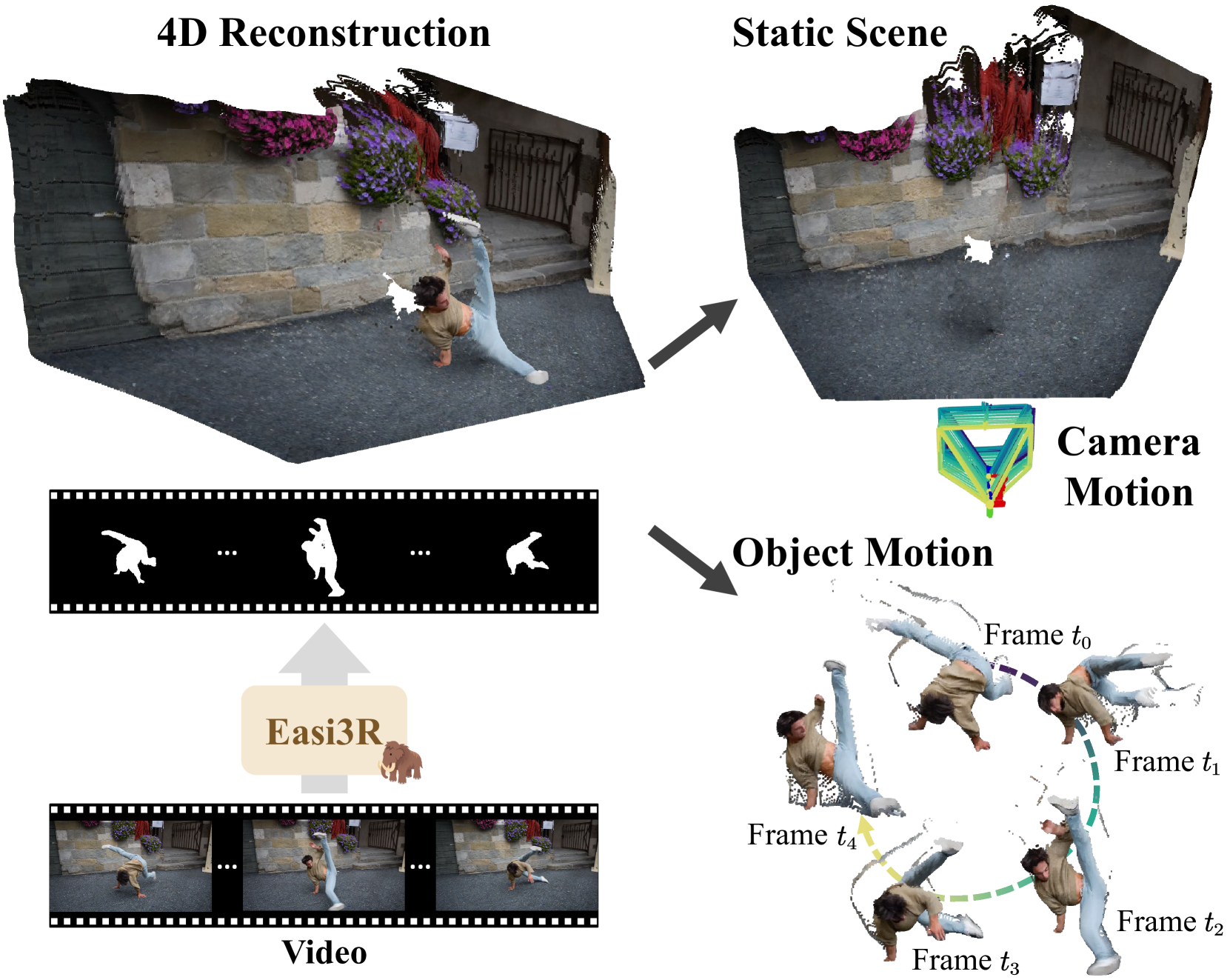
This is a Plain English Papers summary of a research paper called Easi3R: Estimating Disentangled Motion from DUSt3R Without Training. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Easi3R extracts 3D motion from videos without any training
- Builds on DUSt3R to disentangle camera movement from object motion
- Uses geometric constraints and point matching across frames
- Achieves competitive results without needing labeled data
- Works with complex real-world scenes including multiple moving objects
Plain English Explanation
Easi3R is a clever approach that figures out what's moving in videos without needing to train on massive datasets. It builds on another system called DUSt3R that already creates 3D scenes from 2D images.
Think of watching a video taken from a moving car. There's motion happening in two ways: the camera itself is moving as the car drives, and other objects (like pedestrians or other vehicles) are moving independently. Easi3R can tell these apart, which is really useful for understanding what's actually happening in a scene.
The magic of this approach is that it doesn't need to be trained on labeled examples. Instead, it uses geometry and mathematics to solve the problem. It's like solving a puzzle by finding the rules that must be true, rather than memorizing solutions to similar puzzles.
What makes Easi3R special is that it works by tracking individual points across frames, figuring out which points are part of the static environment and which belong to moving objects. It's similar to how your own visual system can distinguish between your movement and things moving around you.
Key Findings
- Easi3R successfully separates camera motion from object motion without requiring training data
- The system works on complex real-world scenes with multiple moving objects
- It builds on DUSt3R, maintaining its ability to process pairs of frames but adding motion analysis
- Performance is competitive with other methods despite not requiring training
- The approach works with as few as two frames but improves with more frames (sequences)
- It can handle scenes with multiple independently moving objects
- The algorithm shows robustness to various challenging conditions like occlusions and changing lighting
Technical Explanation
Easi3R builds upon DUSt3R, which is a pre-trained model that predicts 3D scene structure from image pairs. While DUSt3R works well for static scenes, it struggles with dynamic scenes because it can't distinguish between camera motion and object motion. Easi3R addresses this limitation through a carefully designed post-processing algorithm.
The technical approach involves several key steps. First, the algorithm extracts point correspondences across frames using DUSt3R. Then it uses RANSAC (Random Sample Consensus) to identify the dominant motion, which typically represents the camera movement relative to the static environment. Points that don't conform to this motion model are likely part of independently moving objects.
For handling multiple frames, Easi3R employs a temporal consistency check, tracking points across the sequence and refining motion estimates. This helps to improve reliability and handle challenging cases. The system uses epipolar geometry constraints to distinguish static points from dynamic ones.
A significant technical contribution is the method's ability to handle multiple moving objects without explicit instance segmentation. It achieves this by clustering points based on their motion patterns, effectively identifying different objects moving independently.
The geometric approach makes Easi3R particularly interesting compared to learning-based methods like DRIV3R that require large amounts of training data. This makes it more easily deployable in new domains where training data might be scarce.
Critical Analysis
While Easi3R shows impressive capabilities, it has several limitations. The approach relies heavily on the quality of DUSt3R's point correspondences. When these are inaccurate—which can happen in low-texture regions or with significant occlusion—Easi3R's performance degrades.
The method also struggles with very small moving objects or those with minimal motion, as they're harder to distinguish from noise in the point correspondences. Additionally, the approach assumes mostly rigid motion, which may not hold for articulated objects like humans or animals.
Another limitation is that Easi3R doesn't produce a complete scene reconstruction with segmented moving objects. It identifies motion but doesn't generate the kind of comprehensive 4D reconstruction that some competing methods offer.
The paper doesn't thoroughly address computational efficiency. The geometric operations, especially with many points across multiple frames, could become computationally expensive. This might limit real-time applications without further optimization.
A more fundamental question is whether purely geometric approaches like Easi3R can handle all the complexities of real-world scenes. While avoiding training is elegant, it might miss opportunities to leverage learned priors about how objects typically move in the world.
Conclusion
Easi3R represents an important step forward in 3D vision by showing that sophisticated motion analysis can be achieved without specialized training. By building on pre-trained models and applying geometric constraints, it achieves what normally requires complex training pipelines.
This approach could be particularly valuable in contexts where training data is limited or where deploying systems to new environments needs to happen quickly. The ability to work with just a few frames makes it practical for many real-world applications.
Looking forward, Easi3R could serve as a foundation for more advanced systems that combine its training-free approach with selective learning components. It also points toward the continuing value of geometric understanding in computer vision, even in an era dominated by deep learning.
The work bridges traditional geometric computer vision with modern neural approaches, suggesting that the future of robust 3D vision may lie in hybrid approaches that leverage the strengths of both paradigms. This could lead to systems that are both data-efficient and capable of handling the full complexity of dynamic real-world scenes.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.
Subscribe to my newsletter
Read articles from Mike Young directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by