Expanding RL with Verifiable Rewards Across Diverse Domains
 Mike Young
Mike Young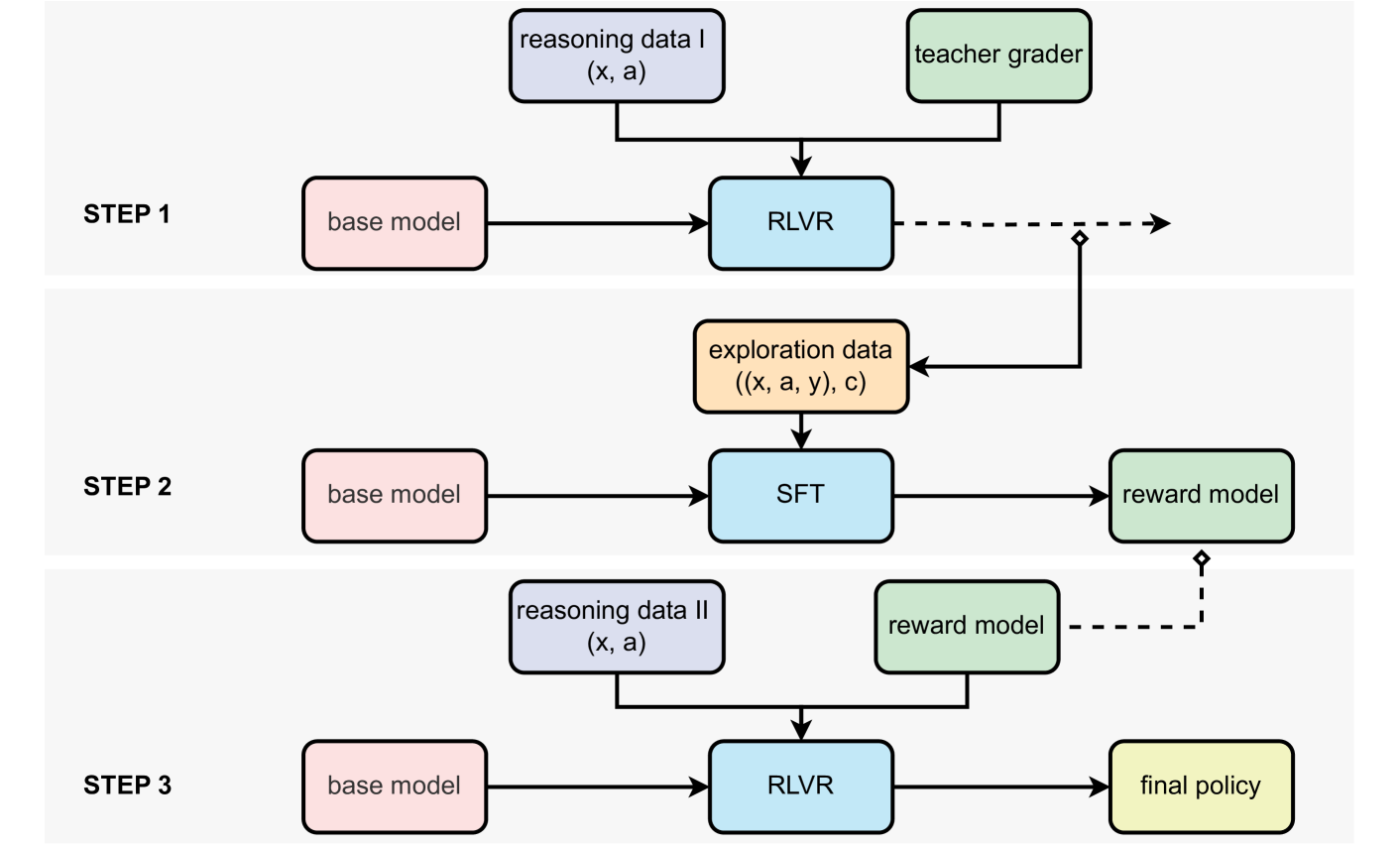
This is a Plain English Papers summary of a research paper called Expanding RL with Verifiable Rewards Across Diverse Domains. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces PAVE method for using verifiable rewards across multiple domains
- Improves reward learning in reinforcement learning systems
- Applies to medicine, mathematics, robotics, and text generation
- Achieves strong performance with small models (3B parameters)
- Demonstrates efficient domain adaptation with limited training examples
- Outperforms previous approaches in multiple benchmarks
Plain English Explanation
Reinforcement Learning (RL) is a way to train AI systems by giving them rewards for good actions. But it's hard to define what "good" means in many complex tasks. The research team created a new approach called PAVE that solves this problem by using clear, verifiable rewards across different domains.
Think of it like training a dog. With a simple trick like "sit," you can immediately see if the dog did it right and give a treat. But for complex behaviors like "guard the house," it's harder to judge success. PAVE helps AI systems learn complex tasks by breaking them down into parts that can be clearly judged as right or wrong.
The researchers found that even relatively small AI models (3 billion parameters, when many systems today use hundreds of billions) can perform impressively when trained with this method. What's special about PAVE is how well it works across completely different fields - from medical diagnosis to solving math problems to controlling robots and writing text.
Most importantly, once the system learns one domain, it can quickly adapt to new areas with just a few examples. It's like how a person who learns to play tennis might pick up badminton more quickly than someone starting from scratch - PAVE helps AI systems transfer their learning in a similar way.
Key Findings
The research demonstrated several important breakthroughs:
Multi-domain capability: PAVE successfully worked across medical reasoning, mathematical problem-solving, robotic manipulation, and text generation tasks - showing broad applicability.
Strong performance with smaller models: Their 3B parameter model achieved competitive or superior performance compared to much larger models, highlighting the efficiency of their approach.
Medical reasoning success: PAVE achieved 67.3% diagnostic accuracy on MedQA and 71.5% on PubMedQA, outperforming previous specialized approaches like Med-RLVR.
Mathematical reasoning improvements: The system achieved 87.6% accuracy on GSM8K and 56.8% on MATH, showing strong mathematical problem-solving abilities.
Efficient domain adaptation: Models trained on one domain could quickly adapt to new domains with just a few examples, demonstrating the transferability of learned skills.
Robotic task mastery: In simulated robotic environments, PAVE achieved higher success rates than previous methods, showing its applicability to physical control tasks.
Technical Explanation
The PAVE framework builds on the concept of Reinforcement Learning with Verifiable Rewards (RLVR). The key innovation is extending this approach to work effectively across diverse domains while maintaining strong performance.
The researchers implemented a two-stage training process. First, they train a base model using supervised fine-tuning (SFT) across multiple domains. Then, they apply reinforcement learning with a carefully designed reward structure. This approach avoids the common problem of "reward hacking," where AI systems find ways to maximize rewards without actually improving at the intended task.
For medical reasoning, the system was trained on clinical cases where final diagnoses were known, allowing for clear verification of its reasoning. In mathematics, the system's solutions could be checked against known answers. For robotics, task completion could be objectively measured. In text generation, adherence to guidelines could be evaluated.
The architecture uses a transformer-based language model with 3B parameters as its foundation. What distinguishes PAVE is its reward mechanism, which provides clear feedback signals based on objective verification rather than subjective human preferences.
A particularly significant finding is how the system performs transfer learning. Models trained on one domain (like mathematics) could quickly adapt to new domains (like medicine) with minimal additional training. This suggests the system is learning generalizable problem-solving strategies rather than just memorizing domain-specific knowledge.
Critical Analysis
While the results are impressive, several limitations should be considered. First, the researchers acknowledge that their approach still requires clear verification signals, which may not be available for all tasks. For instance, creative writing or philosophical reasoning may lack objective "right answers" for verification.
The study focused primarily on domains where outputs can be objectively evaluated. This raises questions about how well PAVE would generalize to more subjective tasks where verification is less clear-cut. The paper doesn't fully address how the system would handle ambiguous cases or tasks with multiple valid solutions.
Additionally, while the 3B parameter model performed well, the researchers don't provide extensive comparisons against the very latest and largest models. This makes it difficult to assess exactly how the efficiency gains compare to the absolute state of the art.
The robotic tasks were performed in simulation rather than real-world environments, which typically present additional challenges. The paper doesn't address how physical world constraints might affect performance.
Another consideration is that verifiable rewards may not always align perfectly with human preferences or values. In some domains, especially creative ones, what's technically correct may not be what's most useful or appealing to humans. The integration of fuzzy rewards alongside verifiable ones could be an important direction for future work.
Conclusion
PAVE represents a significant advancement in reinforcement learning by demonstrating how verifiable rewards can be effectively leveraged across diverse domains. The ability to train relatively small models to perform complex tasks efficiently has important implications for making AI more accessible and practical.
The research suggests a promising direction for developing more versatile AI systems that can transfer learning between domains. Rather than training separate specialized models for each task, PAVE points toward more adaptable general-purpose systems that can quickly apply their knowledge to new areas.
Reinforcement learning with verifiable rewards offers a middle ground between purely supervised learning (which requires extensive labeled examples) and preference-based reinforcement learning (which relies on subjective human feedback). This approach may be particularly valuable for domains like medicine and safety-critical systems where objective correctness is essential.
As AI continues to be applied to increasingly complex real-world problems, approaches like PAVE that can efficiently learn across domains while maintaining verifiable performance will be crucial for developing trustworthy and capable systems.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.
Subscribe to my newsletter
Read articles from Mike Young directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by