Large Language Models are Unreliable for Cyber Threat Intelligence
 Mike Young
Mike Young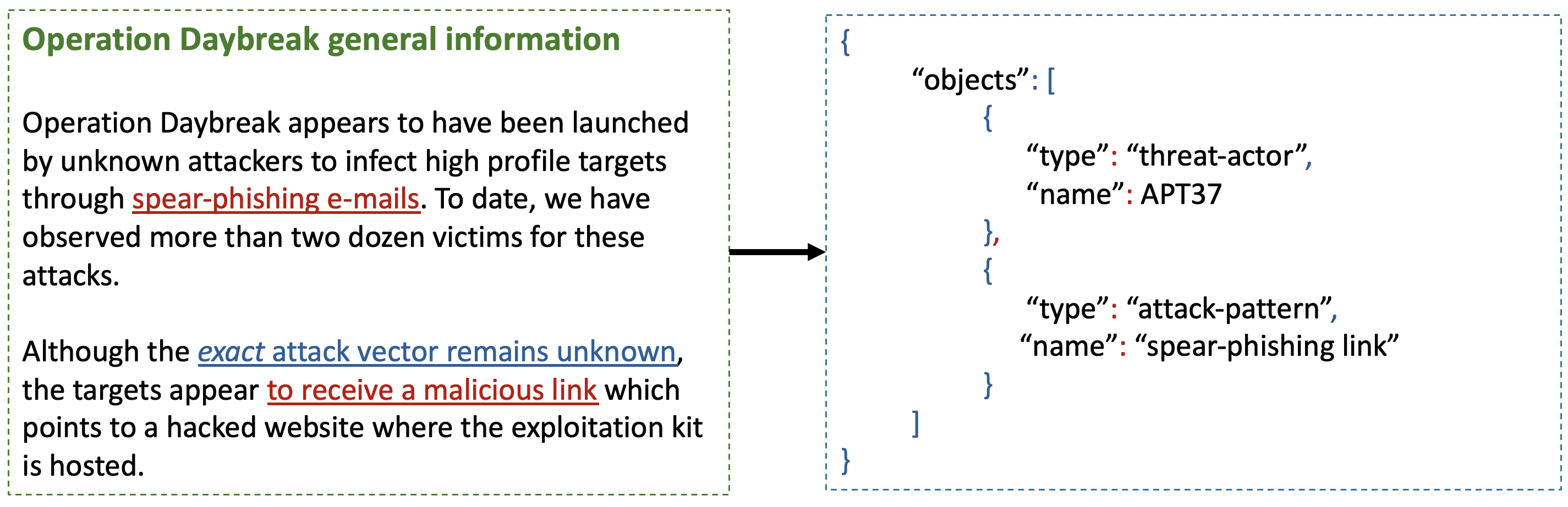
This is a Plain English Papers summary of a research paper called Large Language Models are Unreliable for Cyber Threat Intelligence. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- LLMs are unreliable for Cyber Threat Intelligence (CTI)
- Researchers identified major concerns with hallucinations, vulnerabilities, and biases
- Current LLMs make dangerous mistakes when analyzing cyber threats
- Practitioners should avoid using LLMs for high-stakes CTI decisions
- Study tested GPT-4, Claude, Gemini, and other leading models
Plain English Explanation
Large Language Models have a serious problem when it comes to cyber threat intelligence. The paper shows these AI systems often make up fake information, miss important details, and give incorrect security advice when analyzing cyber threats.
Think of it like asking someone who sounds knowledgeable about computer security for advice, but they're actually making up half their answers. This is especially dangerous in cybersecurity where accuracy matters tremendously. When security teams rely on these tools to understand threats, they might miss actual attacks or waste time chasing false leads.
The researchers tested leading AI models from OpenAI, Anthropic, and Google on real cybersecurity reports. They found the models struggled with long documents, often fabricated details, and couldn't reliably identify important technical specifics like malware names or attack techniques. Sometimes the models would confidently make up completely fictional cyber threats.
Key Findings
The research revealed several critical problems with using LLMs for cyber threat intelligence:
- LLMs consistently hallucinate fictional details when summarizing threat reports
- Models perform worse with longer documents, often losing track of context
- LLMs struggle to correctly identify technical elements like hashes, IP addresses, and malware names
- When asked to extract specific information, models frequently fabricate answers rather than saying "I don't know"
- Even the most advanced models (GPT-4, Claude) make serious errors in security analysis
One striking example showed a model inventing a completely fictitious malware strain called "TrickLoader" when analyzing a report about a different threat. In another case, models fabricated non-existent code vulnerabilities when asked to summarize a security bulletin.
Technical Explanation
The researchers evaluated several leading LLMs including GPT-4, Claude 2, Gemini, and others in cybersecurity contexts. Their methodology involved feeding the models real threat intelligence reports from reputable security firms and comparing the models' outputs against ground truth.
The testing approach focused on practical, real-world CTI tasks:
- Summarizing threat reports
- Extracting specific technical indicators
- Answering questions about the reports' content
- Analyzing malware behaviors
The results showed systematic failures across all models tested. For example, when extracting technical indicators like IP addresses or file hashes, models would often substitute fabricated values that appeared syntactically correct but were entirely fictional. The study found that "longer reports led to worse output" - as report length increased, hallucination rates rose dramatically.
The researchers also observed models struggling with temporal reasoning about computer security. When asked about the timeline of attacks, LLMs often confused dates or invented fictional chronologies not supported by the source material.
Critical Analysis
While the research makes a compelling case about LLM limitations in CTI, there are some important considerations about scope and methodology. The study doesn't extensively test potential mitigations like using retrieval-augmented generation (RAG) or fine-tuning models specifically for cybersecurity applications, which might improve performance.
The paper also doesn't fully address how humans currently use LLMs in real-world security operations. In practice, many professionals use these tools to augment rather than replace human analysis. A hybrid approach where humans verify LLM outputs might mitigate some risks.
Another limitation is the rapidly evolving nature of LLM capabilities. The research represents a snapshot in time, and newer models or techniques might address some of the identified weaknesses. The authors acknowledge this by noting that future work should explore how model improvements affect reliability in the CTI domain.
The study primarily focuses on English-language threat reports from a limited set of sources. Cybersecurity is a global field, and model performance may vary across languages and cultural contexts not captured in the current research.
Conclusion
This research delivers a clear warning: current LLMs are not reliable enough for critical cyber threat intelligence tasks. The tendency to hallucinate, fabricate technical details, and provide incorrect analysis makes these models potentially dangerous when used without human oversight in security contexts.
The findings suggest organizations should exercise extreme caution when incorporating LLMs into security workflows. At minimum, output from these models should be thoroughly verified by human analysts before being used for decision-making. For high-stakes security decisions, organizations may need to avoid LLM use entirely until reliability improves.
Looking forward, the paper highlights the need for specialized evaluation benchmarks in cybersecurity that can better assess model reliability. As AI continues advancing, creating more trustworthy systems for security applications remains an important challenge. Until then, the human element in cybersecurity analysis remains irreplaceable.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.
Subscribe to my newsletter
Read articles from Mike Young directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by