Evaluating AI Products with LLM-as-Judge
 Jonas Kim
Jonas Kim
Importance of Evaluation Systems in AI Products
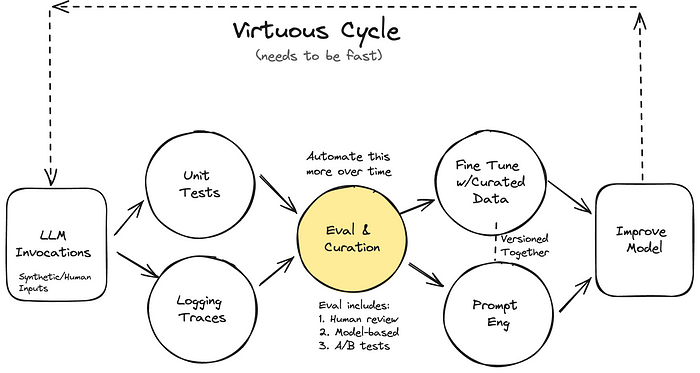
Virtuous cycle of AI product improvement
To ensure the success of AI products, especially those based on Large Language Models (LLMs), a systematic and robust evaluation system is essential. The reasons are as follows:
1. Continuous Performance Improvement: Evaluation systems enable continuous monitoring and improvement of AI product performance. Various levels of evaluation frameworks help identify and address product weaknesses.
2. Quick Iteration: Evaluation systems allow for rapid quality assessment, debugging, and behavior modification of the system, thereby shortening the development cycle.
3. Overcoming Demo Levels: Systematic evaluation systems can measure and improve performance in production environments.
4. High-Quality Data Generation: Data generated during the evaluation process can be used for fine-tuning models, aiding in solving complex problems.
5. Efficient Debugging: Evaluation systems help quickly identify and correct errors, enhancing product stability and reliability.
6. Improving User Experience: A/B testing and similar methods ensure that AI products drive desired user behavior or outcomes.
7. Objective Performance Measurement: Systematic evaluation systems provide objective performance measurements, serving as a critical basis for product improvement and investment decisions.
Evaluation systems are a key element for the success of AI products. Therefore, investing ample time and resources in building evaluation systems during AI product development is crucial.
Automating AI Product Evaluation with LLMs: Methods and Limitations
Despite the importance of evaluation tasks, they require significant manpower and time when performed manually. Additionally, inconsistencies can arise due to varying standards among evaluators. This has led to attempts to automate much of the evaluation work using LLMs.

The 2023 paper “G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment” proposes the G-EVAL evaluation framework. The process of G-EVAL is as follows:
1. Defining Evaluation Tasks and Setting Criteria
Define evaluation tasks and set criteria. For example, in the case of text summarization, the following criteria might be used:
Coherence: Overall quality of the collection of sentences
Fluency: Grammatical accuracy and naturalness
Relevance: Relevance to the original text
2. Applying Chain of Thought (CoT) Method
Generate specialized instructions for performing evaluation tasks using LLMs. The CoT method is introduced to guide LLMs to detail their reasoning process. For instance, a CoT prompt for evaluating the coherence of a text summary might be structured as follows:
1. Carefully read the news article and identify the main themes and key points.
2. Compare the summary with the news article. Check if the summary covers the main themes and key points of the news article and presents them in a clear and logical order.
3. Assign a score from 1 to 5 based on the evaluation criteria.
3. Performing the Evaluation Task Input the CoT prompt, the input text (e.g., news article), and the target text to be evaluated (e.g., summary) into the LLM to perform the evaluation. The LLM outputs scores according to the evaluation criteria.
4. Probability-Based Score Adjustment Calculate final evaluation scores using the probabilities of each score generated by the LLM. Specifically, use the probabilities assigned by the LLM to each possible score as weights to calculate the final score. This process can be expressed with the following formula:
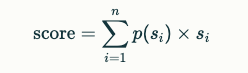
This method provides more granular and continuous scores, improving evaluation accuracy.
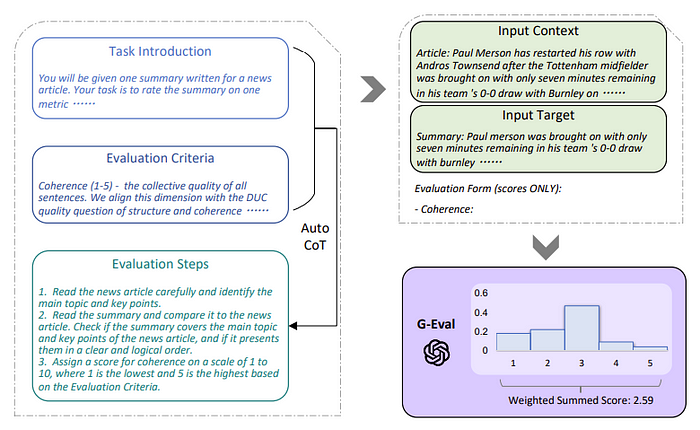
Entire G-EVAL framework
Research results show that evaluations using the G-EVAL framework closely resemble human evaluations, with a Spearman correlation coefficient of 0.514, significantly outperforming all existing evaluation methods. (In contrast, traditional metrics like BLEU and ROUGE often show low correlation with human evaluations.) These results suggest that LLMs can effectively replace human evaluators.
What should be considered when using LLMs as evaluators? The 2023 paper “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” proposes two methods for fair comparison of various chatbots: the multi-turn benchmark MT-Bench and the crowdsourcing battle platform Chatbot Arena. This study also identifies several limitations when using LLMs as evaluators and suggests solutions to these issues. The key points are as follows:
1. Position Bias
Problem: LLMs tend to prefer answers in specific positions when choosing the best among multiple candidates. For example, many LLMs favor the first presented response.
Solution: Change the order of responses and average the results. Providing a few-shot examples can also help improve consistency.
2. Verbosity Bias
- Problem: LLMs tend to rate longer responses higher in quality. This means concise and clear responses might be underrated.
3. Self-enhancement Bias
- Problem: Some LLMs might evaluate their generated responses more positively. However, experiments show that not all models exhibit this bias.
4. Limited Reasoning Ability
Problem: LLMs might not consistently provide accurate evaluations for questions requiring complex reasoning, such as mathematics.
Solution: Use the CoT method to guide LLMs through step-by-step reasoning processes. However, even in these cases, LLMs can still make mistakes. The researchers employed a reference guide method by generating responses independently before attaching them to the evaluation instructions. This approach significantly improved failure rates.
So far, we have explored the theoretical LLM evaluation framework, limitations, and solutions presented in the papers. Next, let’s look at open-source solutions and implemented evaluation metrics that can be used in practice.
Evaluation Metrics and Open-Source Solutions
Retrieval Augmented Generation (RAG) is one of the popular use cases of AI products, but it is challenging to evaluate. RAG-based chatbot answers are created through two stages: retrieval and generation. Accordingly, evaluation metrics can be defined at each stage or comprehensively. These metrics help users assess the appropriateness of retrieval, the quality of answer generation, and the overall performance of the RAG system.
To understand RAG system evaluation metrics, it helps first to look at the metrics used in general retrieval domains, as these can be easily applied in the RAG context. The main metrics are:
Relevance
Definition: The degree to which each search result matches the user’s intent or query.
Measurement Method: Usually rated on a scale of 0–1, 0–5, or 0–10, and measured through expert or user feedback.
Precision
Definition: The proportion of relevant items among the retrieved results.
Formula: (Number of relevant search results) / (Total number of search results)
Recall
Definition: The proportion of actual relevant items that are retrieved.
Formula: (Number of retrieved relevant items) / (Total number of relevant items)
RAGAS
RAGAS is an open-source framework that supports automated evaluation of RAG pipelines. This framework provides various evaluation metrics, many of which assume pre-existing ground truth answers for questions and compare these to LLM-generated answers to measure performance. Let’s examine the key metrics one by one.
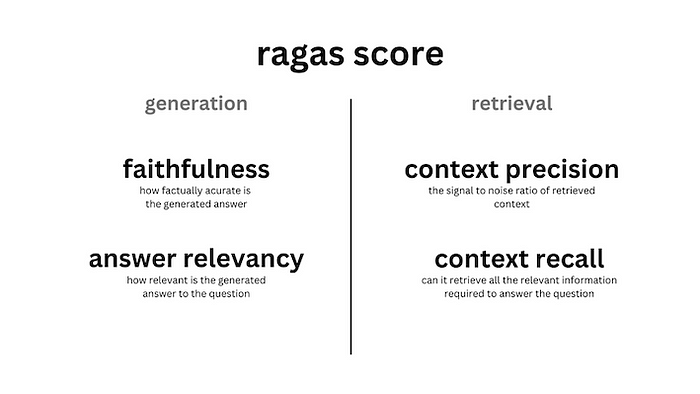
Key evaluation metrics in RAGAS
**Context Precision
**Context precision evaluates how well the relevant items (chunks) within the search results rank higher. This metric is calculated based on a given question, answer, and search results, with values ranging from 0 to 1. Higher scores indicate that relevant information is more present at the top of the search results.
Context precision is calculated through the following steps:
1. Evaluate Relevance by Chunk: Determine the relevance of each chunk in the search results for a given question.
2. Calculate Precision@k: Precision@k represents the precision of the top k chunks. When the total number of chunks is K, calculate Precision@k for each k from 1 to K.
3. Average Precision Calculation: Compute the weighted average of all Precision@k values to get the final context precision score. This average provides a stable metric that considers various rankings.
The calculation process can be expressed with the following formula:

**Context Recall
**Context recall measures the extent to which the search results match the given answer. This metric is calculated based on the answer and search results, with values ranging from 0 to 1. Higher scores indicate more information from the answer is present in the search results.
To calculate context recall:
1. Decompose the Answer: Break the given answer into individual sentences.
2. Evaluate Inclusion of Each Sentence: Check if each sentence of the answer is included in the search results.
3. Calculate Recall: Divide the number of included sentences by the total number of sentences to get the recall value.
The calculation process can be expressed with the following formula:
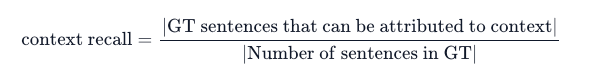
**Answer Correctness
**Answer correctness is a metric that evaluates the accuracy of a generated answer by comparing it to a ground truth answer. This metric is calculated based on the ground truth and the search results, and ranges from 0 to 1. A higher score indicates a greater match or similarity between the generated answer and the ground truth.
Answer correctness considers two important aspects:
1. Factual Accuracy: The accuracy of the factual information included in the answer.
2. Semantic Similarity: The semantic similarity between the generated answer and the ground truth.
These two aspects are combined using weighted averages to produce the final score. Users can round the result score to binary (0 or 1) using a “threshold” if necessary.
To calculate answer correctness, follow these steps:
1. Calculate Factual Accuracy
TP (True Positive): Facts present in both the ground truth and the generated answer.
FP (False Positive): Facts present only in the generated answer.
FN (False Negative): Facts present only in the ground truth.
Based on these, calculate the F1 score, which is the harmonic mean of precision and recall, to quantify factual accuracy.

2. Calculate Semantic Similarity: Compute the semantic similarity between the generated answer and the ground truth.
3. Calculate the Final Score: Compute the weighted average of factual accuracy and semantic similarity to derive the final score. Users can adjust the weights of each element as needed.
**Faithfulness
**Faithfulness measures the factual consistency between the generated answer and the search results. An answer is considered faithful if all claims in the answer can be inferred from the search results. This metric is calculated based on the ground truth and search results and ranges from 0 to 1. A higher score indicates fewer hallucinated elements in the answer.
To calculate faithfulness, follow these steps:
1. Break Down the Generated Answer: Divide the generated answer into individual claims.
2. Verify Each Claim: Check if each claim can be inferred from the search results.
3. Calculate the Score: Divide the number of verifiable claims by the total number of claims to compute the score.
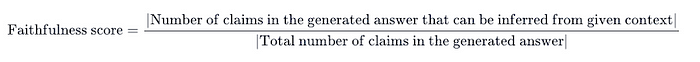
Langchain
Langchain is a renowned LLM application development framework that offers basic evaluation functionalities. This framework allows for automated evaluations by presenting evaluation criteria as instructions to the LLM. It comes with pre-prepared prompts for common criteria such as accuracy, conciseness, usefulness, and harmfulness, making it easy to use.
Langchain also supports customized evaluations based on user-defined criteria. For example, it can be set to evaluate how understandable a generated answer is to a five-year-old child. One of the key features of Langchain is that it not only provides evaluation scores but also records the reasoning process behind these scores. This enhances the transparency of evaluation results and helps users gain a deeper understanding of the evaluation process.
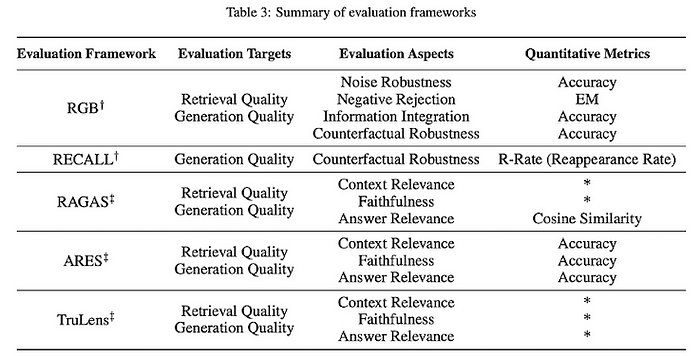
Other open-source solutions providing LLM evaluation functionalities include ARES and TruLens. Refer to the table below for a comparison and summary of each framework.
In this article, we have explored the importance of evaluation systems in AI products, methods and limitations of automating evaluations using LLMs, and various evaluation metrics and open-source solutions.
Evaluation of AI products based on LLMs will continue to evolve with technological advancements. Developers and researchers should actively utilize these evaluation tools and methodologies to create better AI products. At the same time, they should remain aware of biases and limitations in the evaluation process and strive to address them.
References
G-Eval: NLG Evaluation Using GPT-4 with Better Human Alignment (paper, code)
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (paper, code)
RAGAS: Automated Evaluation of Retrieval Augmented Generation
Deploy Foundation Models with Amazon SageMaker, Iterate and Monitor with TruEra
Evaluate LLMs and RAG a Practical Example Using Langchain and Hugging Face
Subscribe to my newsletter
Read articles from Jonas Kim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jonas Kim
Jonas Kim
Sr. Data Scientist at AWS