Zero-Downtime ECS Service Restarts: A Fully AWS-Native Orchestration Solution
 Suman Thallapelly
Suman Thallapelly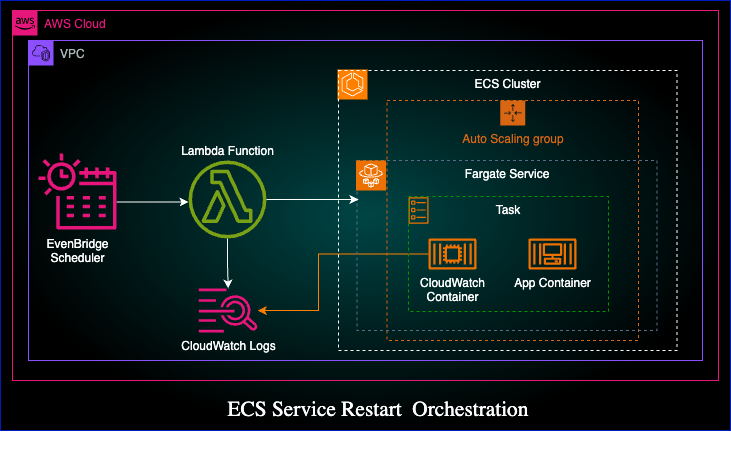
Introduction
In modern cloud-native architectures, Amazon ECS (Elastic Container Service) is a popular choice for running containerized applications at scale. While ECS provides high availability, scalability, and fault tolerance out of the box, there are operational scenarios where automating ECS service restarts becomes essential—without causing any downtime.
Whether you're dealing with memory bloat, stale connections, periodic resource refresh, or specific application lifecycle needs, you may need to restart services on a schedule or in response to operational triggers. I recently work on one such use case involves containerized sidecars—like log shippers—that need a controlled restart to function optimally.
📌 My Real-World Example: Restarting CloudWatch Agent Sidecar Containers
Consider a scenario where each ECS task runs:
A main application container, and
A CloudWatch Agent container as a sidecar, responsible for shipping logs to Amazon CloudWatch.
** The sidecar is chosen to avoid or minimize application code changes.
The requirement is to:
Rotate log files daily, so each new file is timestamped.
The CloudWatch Agent only generates a new log file on task start or container restart.
Hence, a daily restart of ECS tasks is necessary—but without affecting application availability.
This blog post walks you through an elegant, fully AWS-native, low-code solution to:
Automatically restart ECS services daily (e.g., at 12:01 AM EST),
Avoid application downtime through rolling deployments,
And minimize complexity and cost using tools like Amazon EventBridge, AWS Lambda, and ECS UpdateService API.
Let’s dive into the design and step-by-step implementation.
Options Explored
Option 1: CloudWatch Agent's Built-in Log Rotation :
Naturally the best solutions would be the Built-in Log Rotation as it requires No service restarts. But in this specific scenario (sidecars) log rotation can’t use dynamic file names with dates unless container is restarted. So this opting is and deliver the expected outcome.
Option 2: Manually Rotate Logs in Container :
This needs custom agent which complicate the setup and deviate the purpose of pre-build sidecar selection for simplicity and low operational overhead.
Pros: Fine-grained control.
Cons: High operational overhead and requires custom code
Option 3: Restart Specific Containers via SSM Exec :
This sounds great initially, considering the advantage that we can target just the CloudWatch agent and no interruption to actual application. But the major drawback is it’s More Complex Setup
Pros: More targeted solution with
Cons:
Requires ECS Exec setup, custom command logic, container introspection
✖ Not Natively Automated: Unlike ECS deployments, SSM does not have a built-in rolling update mechanism.
✖ Potential Execution Failures: If the CloudWatch Agent crashes unexpectedly, SSM may fail to restart it.
✖ Potential loss of data: prone to miss data generate while agent restarting.
Option 4: Restart Entire Service via ECS API :
The key advantage of this approach is, ECS performs a rolling restart, ensuring zero downtime while forcing CloudWatch Agent to create a new log file with a timestamp. This is simple, can be achieved with native tools: EventBridge Scheduler + Lambda and can be scaled to address complex scenarios if required.
Pros: Best for simplicity, reliability, and scalability.
Cons: A rolling restart causes the creation of new tasks, which momentarily increases resource utilization.
My Final Choice
I chose Option 4: Trigger an ECS service restart using UpdateService with forceNewDeployment: true, orchestrated by EventBridge Scheduler + Lambda.
Why?
Fully AWS-native and serverless: A fully AWS-managed solution with minimal manual intervention.
AWS Best Practice: ECS rolling restarts are the recommended approach for long-running tasks.
Zero-downtime by design: Thanks to autoscaling, it ensures that at least 1 container is always available.
Supports multiple services : Simpler setup, avoiding unnecessary IAM permissions, agent & service dependencies.
Easy to monitor and extend : Add CloudWatch Alarms or SNS alerts for failures. Extend Lambda to support dry-run or Slack notifications
EventBridge Scheduler is better than EventBridge Rules because:
Supports one-time and recurring schedules
Supports timezones
Allows per-schedule flexibility without needing multiple rules
Provides execution logs for better monitoring
Easier to modify via API/Console
Visualize with new UI
High-Level Architecture
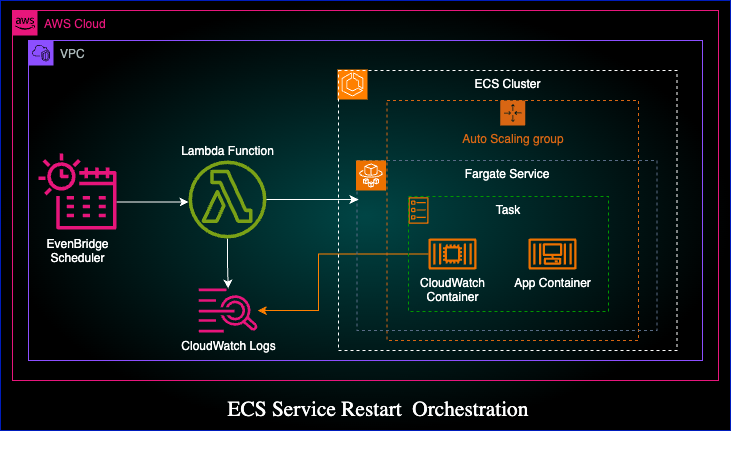
EventBridge Scheduler triggers Lambda daily at 12:01 AM EST
Lambda Function:
Accepts a list of ECS clusters/services as input
Invokes ECS update_service API with forceNewDeployment
Logs success/failure per service
ECS Deployment:
- Service configured with autoscaling, and rolling deployments at least minimum 1 desired task.
Implementation Steps
For full Terraform project check my Git repo here ecs-restart-automation-terraform
Step 1: Create IAM Role for Lambda
Go to IAM Console → Click Roles → Click Create role.
Select AWS Service → Choose Lambda → Click Next.
Attach the following permissions:
AmazonECS_FullAccessAWSLambdaBasicExecutionRole
Click Next → Name the role:
LambdaECSRestartRoleClick Create role
or Alternatively Attach the following permissions:
{
"Effect": "Allow",
"Action": [
"ecs:UpdateService",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
Step 2: Deploy Lambda Function
Go to AWS Lambda Console → Click Create function
Select Author from scratch
Name it:
ecs-rolling-restartRuntime: Python 3.13
Select Execution Role → Choose LambdaECSRestartRole created in step 1.
Click Create function
In the function editor, replace the default code with:
import boto3, json, logging
from botocore.exceptions import ClientError
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
services = event.get("services", [])
if not services:
logger.warning("No services provided.")
return {"statusCode": 400, "body": json.dumps({"error": "No services provided."})}
ecs = boto3.client("ecs")
results = []
for svc in services:
cluster = svc.get("cluster")
service = svc.get("service")
if not cluster or not service:
results.append({"status": "skipped", "reason": "Missing cluster/service"})
continue
try:
ecs.update_service(cluster=cluster, service=service, forceNewDeployment=True)
results.append({"cluster": cluster, "service": service, "status": "success"})
except Exception as e:
logger.error("exception on %s/%s: %s", cluster, service, e)
results.append({"service": service, "cluster": cluster, "status": "failed", "error": str(e)})
return {"statusCode": 200, "body": json.dumps(results)}
- Click Deploy
Step 3: Create EventBridge Scheduler
Navigate to EventBridge Scheduler
Click Create Schedule
Choose Recurring Schedule
Select Time zone
Set cron expression: cron(1 0 * * ? *) for 12:01 AM EST
Select Lambda Function as target and provide Lambda function create in Step 2
Create new default Execution Role or select if one exist.
Provide input Payload.
Input Example:
{
"services": [
{ "cluster": "prod-cluster", "service": "orders-service" },
{ "cluster": "prod-cluster", "service": "billing-service" }
]
}
Optional: Test with AWS CLI
aws lambda invoke \
--function-name ecs-daily-restart \
--payload file://input.json \
output.json
Where input.json contains:
{
"services": [
{"cluster": "prod-cluster", "service": "orders-service"}
]
}
Monitoring and Troubleshooting
Check CloudWatch Logs under: /aws/lambda/<your-function-name>
Add structured logging (logger.info, logger.error)
Validate ECS task restarts under ECS service -> Events tab
Final Thoughts
This pattern gives you:
Zero-downtime, daily ECS service rolling restarts
Daily log file rotation via CloudWatch Agent
Dynamic, multi-service support with a single Lambda
Fully serverless and scalable design
Next Steps
Add CloudWatch Alarms or SNS alerts for failures
Extend Lambda to support dry-run or Slack notifications
Use Parameter Store or DynamoDB to store service metadata
Visualize with EventBridge Scheduler (new UI)
Summary
By combining Amazon EventBridge Scheduler, AWS Lambda, and Amazon ECS, we built a reliable, serverless orchestration for ECS task restarts tailored to log rotation needs. This approach balances low-code simplicity with enterprise-grade flexibility.
Thank you for taking the time to read my post! 🙌 If you found it insightful, I’d truly appreciate a like and share to help others benefit as well. 🚀
Subscribe to my newsletter
Read articles from Suman Thallapelly directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Suman Thallapelly
Suman Thallapelly
Hey there! I’m a seasoned Solution Architect with a strong track record of designing and implementing enterprise-grade solutions. I’m passionate about leveraging technology to solve complex business challenges, guiding organizations through digital transformations, and optimizing cloud and enterprise architectures. My journey has been driven by a deep curiosity for emerging technologies and a commitment to continuous learning. On this space, I share insights on cloud computing, enterprise technologies, and modern software architecture. Whether it's deep dives into cloud-native solutions, best practices for scalable systems, or lessons from real-world implementations, my goal is to make complex topics approachable and actionable. I believe in fostering a culture of knowledge-sharing and collaboration to help professionals navigate the evolving tech landscape. Beyond work, I love exploring new frameworks, experimenting with side projects, and engaging with the tech community. Writing is my way of giving back—breaking down intricate concepts, sharing practical solutions, and sparking meaningful discussions. Let’s connect, exchange ideas, and keep pushing the boundaries of innovation together!