Mixtral of Experts 논문 리뷰
 Jonas Kim
Jonas Kim
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델의 발전은 최근 인공지능 분야에서 가장 중요한 연구 주제 중 하나로 자리 잡았다. 그러나 기존 모델들은 계산 비용과 메모리 요구사항이 급격히 증가하면서 실제 응용에 있어 심각한 제약을 가지고 있었다. 특히 모델의 크기가 커질수록 모든 매개변수를 동시에 활성화하는 것은 비현실적이며 비효율적이었다. 이러한 문제를 해결하기 위해 연구자들은 모델의 계산 효율성을 높이면서도 성능을 유지할 수 있는 새로운 아키텍처에 대한 필요성을 절감하게 되었다.
희소 전문가 혼합(Sparse Mixture of Experts) 모델은 이러한 도전 과제에 대한 유망한 해결책으로 떠오르고 있었다. 이 접근 방식은 모든 매개변수를 동시에 사용하는 대신, 각 입력에 대해 선택된 일부 전문가만을 활성화함으로써 계산 효율성을 크게 향상시킬 수 있다. 그러나 기존의 희소 전문가 혼합 모델들은 여전히 성능과 효율성 사이의 균형을 완전히 달성하지 못하고 있었으며, 실제 응용 환경에서 충분한 경쟁력을 보여주지 못했다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
Mixtral 8x7B는 희소 전문가 혼합 아키텍처를 혁신적으로 개선하여 이러한 한계를 극복하고자 했다. 핵심 혁신은 각 층에서 8개의 전문가 중 2개를 동적으로 선택하는 라우팅 메커니즘에 있다. 이 접근 방식은 모델의 총 매개변수 수(47B)와 실제 추론 시 활성화되는 매개변수 수(13B) 사이의 최적의 균형을 달성할 수 있게 해준다. 특히 각 토큰은 처리될 때마다 서로 다른 전문가 조합을 활용할 수 있어 모델의 유연성을 크게 향상시켰다.
또한 Mixtral은 32k 토큰의 긴 컨텍스트 길이를 지원하며, 트랜스포머 아키텍처의 최신 개선 사항들을 통합했다. 라우터 네트워크는 각 입력 토큰에 대해 가장 적합한 2개의 전문가를 선택하고, 선택된 전문가들의 출력을 가중합하여 최종 결과를 생성한다. 이러한 설계는 모델이 다양한 도메인과 작업에 대해 더 효과적으로 적응할 수 있게 해주며, 계산 효율성을 크게 개선했다.
제안된 방법은 어떻게 구현되었습니까?
Mixtral의 구현은 희소 전문가 혼합 층(Sparse Mixture of Experts Layer)을 중심으로 이루어졌다. 각 층에서 입력 토큰 \(x\)가 주어지면, 라우터 네트워크는 로짓 \(h(x) = W_r \cdot x\)를 계산하고 소프트맥스 함수를 통해 8개의 전문가 중 상위 2개를 선택한다. 선택된 전문가들은 입력 토큰을 처리하고, 최종 출력은 선택된 전문가들의 출력의 가중합으로 계산된다.
모델의 학습 과정은 지도 학습 미세 조정(Supervised Fine-tuning)과 직접 선호도 최적화(Direct Preference Optimization)를 포함한다. 이를 통해 Mixtral 8x7B Instruct 모델은 인간의 지시를 더 잘 따르도록 훈련되었다. 실험에서는 다양한 벤치마크(MMLU, HellaSwag, ARC Challenge 등)를 통해 모델의 성능을 평가했으며, 대부분의 지표에서 Llama 2 70B와 GPT-3.5를 능가하거나 동등한 성능을 보여주었다.
이 연구의 결과가 가지는 의미는 무엇입니까?
Mixtral 8x7B의 연구 결과는 대규모 언어 모델 개발에 있어 중요한 이정표를 제시했다. 희소 전문가 혼합 아키텍처를 통해 계산 효율성과 모델 성능 사이의 새로운 균형점을 찾아냈으며, 이는 향후 AI 모델 설계에 중요한 영감을 제공할 것으로 기대된다. 특히 각 토큰에 대해 13B의 활성 매개변수만 사용하면서도 70B 파라미터 모델과 동등하거나 더 나은 성능을 달성했다는 점은 매우 의미 있는 성과이다.
Apache 2.0 라이선스로 모델을 완전히 오픈소스화한 점도 중요한 의미를 가진다. 이를 통해 연구 커뮤니티와 산업계에 고성능 언어 모델을 자유롭게 활용하고 개선할 수 있는 기회를 제공했다. 향후 연구 방향으로는 더 많은 전문가 활용, 라우팅 메커니즘 개선, 도메인 특화 전문가 훈련 등이 제시되었으며, 이는 AI 기술의 지속적인 발전 가능성을 보여준다.
Mixtral of Experts: 전문가 혼합 모델의 새로운 지평
소개
Mixtral 8x7B는 희소 전문가 혼합(Sparse Mixture of Experts, SMoE) 언어 모델로, 기존의 Mistral 7B와 동일한 아키텍처를 기반으로 하되 각 층이 8개의 피드포워드 블록(전문가)으로 구성된 혁신적인 모델입니다. 이 모델의 핵심 메커니즘은 각 토큰이 처리될 때마다 라우터 네트워크가 8개의 전문가 중 2개를 동적으로 선택하여 현재 상태를 처리하고 그 출력을 결합하는 방식으로 작동합니다. 각 토큰은 단 2개의 전문가만 활용하지만, 선택되는 전문가는 각 타임스텝마다 달라질 수 있어 유연성을 제공합니다. 이러한 구조 덕분에 각 토큰은 총 47B 매개변수에 접근할 수 있지만, 실제 추론 과정에서는 단 13B의 활성 매개변수만 사용하게 됩니다.
Mixtral은 32k 토큰의 컨텍스트 크기로 학습되었으며, 다양한 벤치마크에서 Llama 2 70B와 GPT-3.5를 능가하거나 대등한 성능을 보여줍니다. 특히 수학, 코드 생성, 다국어 벤치마크에서 Llama 2 70B를 크게 앞서는 성능을 보여주고 있습니다. 이는 희소 전문가 혼합 아키텍처가 효율적인 매개변수 활용을 통해 더 큰 모델의 성능을 달성할 수 있음을 보여주는 중요한 사례입니다.
연구팀은 또한 지시사항을 따르도록 미세 조정된 모델인 Mixtral 8x7B – Instruct를 함께 공개했습니다. 이 모델은 지도 학습 미세 조정(supervised fine-tuning)과 직접 선호도 최적화(Direct Preference Optimization)를 통해 학습되었으며, GPT-3.5 Turbo, Claude-2.1, Gemini Pro, Llama 2 70B – chat 모델을 인간 평가 벤치마크에서 능가하는 성능을 보여줍니다. 특히 BBQ와 BOLD와 같은 벤치마크에서 편향이 감소하고 더 균형 잡힌 감정 프로필을 보여주는 것으로 나타났습니다.
Mixtral의 희소 전문가 혼합 아키텍처는 매개변수 수를 늘리면서도 계산 비용과 지연 시간을 효과적으로 제어할 수 있게 해줍니다. 이는 각 토큰이 전체 매개변수 집합 중 일부만 사용하기 때문에 가능합니다. 이러한 접근 방식은 작은 배치 크기에서는 더 빠른 추론 속도를, 큰 배치 크기에서는 더 높은 처리량을 제공합니다.
이해를 돕기 위해 Mixtral의 희소 전문가 혼합 아키텍처를 수학적으로 설명하면 다음과 같습니다. 각 층에서 입력 토큰 \(x\)가 주어졌을 때, 라우터 네트워크는 로짓 \(h(x) = W_r \cdot x\)를 계산합니다. 여기서 \(W_r\)은 학습 가능한 라우터 가중치입니다. 이 로짓은 소프트맥스 함수를 통해 정규화되어 각 전문가 \(i\)에 대한 게이트 값을 얻습니다.
\[ p_i(x) = \frac{e^{h(x)\_i}}{\sum_{j=1}^{N}e^{h(x)_j}} \]
여기서 가장 높은 게이트 값을 가진 상위 \(k=2\)개의 전문가가 선택되며, 이를 집합 \(\mathcal{T}\)로 표시합니다. 층의 출력은 선택된 전문가들의 계산 결과의 가중 합으로 계산됩니다.
\[ y = \sum_{i \in \mathcal{T}} p_i(x) E_i(x) \]
여기서 \(E_i(x)\)는 \(i\)번째 전문가 네트워크의 출력입니다.
Mixtral 8x7B와 Mixtral 8x7B – Instruct 모델은 모두 Apache 2.0 라이선스로 공개되어 학술 및 상업적 용도로 자유롭게 사용할 수 있습니다. 이는 다양한 응용 분야에서 이 모델을 활용할 수 있는 가능성을 열어줍니다. 또한 연구팀은 커뮤니티가 완전히 오픈 소스 스택으로 Mixtral을 실행할 수 있도록 vLLM 프로젝트에 Megablocks CUDA 커널을 통합하는 변경사항을 제출했습니다. Skypilot을 통해 클라우드의 어떤 인스턴스에서도 vLLM 엔드포인트를 배포할 수 있게 되었습니다.
이러한 Mixtral의 혁신적인 아키텍처와 뛰어난 성능은 대규모 언어 모델 분야에서 중요한 발전을 보여주며, 특히 계산 효율성과 모델 성능 사이의 균형을 맞추는 새로운 접근 방식을 제시합니다. 희소 전문가 혼합 모델은 향후 대규모 언어 모델 개발에 있어 중요한 방향성을 제시할 것으로 기대됩니다.
아키텍처 세부 사항
Mixtral은 트랜스포머 아키텍처를 기반으로 하며, Vaswani와 연구진이 제안한 원래의 트랜스포머 모델에 Jiang과 연구진의 개선사항을 적용하고 있습니다. 그러나 Mixtral은 두 가지 주요한 차이점을 가지고 있습니다. 첫째, 32k 토큰의 완전 밀집 컨텍스트 길이를 지원하며, 둘째, 피드포워드 블록이 전문가 혼합(Mixture-of-Expert) 층으로 대체되었습니다. 모델 아키텍처의 주요 매개변수는 아래 표에 요약되어 있습니다.
| 매개변수 | 값 |
| dim | 4096 |
| n_layers | 32 |
| head_dim | 128 |
| hidden_dim | 14336 |
| n_heads | 32 |
| n_kv_heads | 8 |
| context_len | 32768 |
| vocab_size | 32000 |
| num_experts | 8 |
| top_k_experts | 2 |
희소 전문가 혼합(Sparse Mixture of Experts)

전문가 혼합 층(Mixture of Experts, MoE)에 대해 간략히 살펴보겠습니다. 더 자세한 내용은 Fedus와 연구진의 논문을 참조하시기 바랍니다.
주어진 입력 \(x\)에 대한 MoE 모듈의 출력은 전문가 네트워크의 출력의 가중합으로 결정되며, 여기서 가중치는 게이팅 네트워크의 출력에 의해 주어집니다. 즉, \(n\)개의 전문가 네트워크 \(\{E_0, E_i, ..., E_{n-1}\}\)가 주어졌을 때, 전문가 층의 출력은 다음과 같이 계산됩니다.
\[ \sum_{i=0}^{n-1} G(x)_i \cdot E_i(x) \]
여기서 \(G(x)_i\)는 \(i\)번째 전문가에 대한 게이팅 네트워크의 \(n\)차원 출력을 나타내며, \(E_i(x)\)는 \(i\)번째 전문가 네트워크의 출력입니다.
게이팅 벡터가 희소하다면, 게이트가 0인 전문가의 출력을 계산하는 것을 피할 수 있습니다. \(G(x)\)를 구현하는 여러 대안적인 방법이 있지만(Shazeer와 연구진, Lepikhin과 연구진, Fedus와 연구진), 간단하면서도 성능이 좋은 방법은 선형 층의 상위 K 로짓에 대해 소프트맥스를 취하는 것입니다. 다음과 같이 정의합니다.
\[ G(x) := \text{Softmax}(\text{TopK}(x \cdot W_g)) \]
여기서 \((\text{TopK}(\ell))_i := \ell_i\)는 로짓 \(\ell \in \mathbb{R}^n\)의 상위 K 좌표 중 하나인 경우이고, 그렇지 않으면 \((\text{TopK}(\ell))_i := -\infty\)입니다.
K 값(토큰당 사용되는 전문가의 수)은 각 토큰을 처리하는 데 사용되는 계산량을 조절하는 하이퍼파라미터입니다. K를 고정한 상태에서 \(n\)을 증가시키면, 모델의 매개변수 수를 증가시키면서도 계산 비용을 효과적으로 일정하게 유지할 수 있습니다. 이는 모델의 총 매개변수 수(일반적으로 희소 매개변수 수라고 함)와 개별 토큰을 처리하는 데 사용되는 매개변수 수(활성 매개변수 수라고 함) 사이의 구분을 동기화합니다. 전자는 \(n\)과 함께 증가하고, 후자는 \(n\)까지 \(K\)와 함께 증가합니다.
MoE 층은 단일 GPU에서 고성능 특수 커널을 사용하여 효율적으로 실행할 수 있습니다. 예를 들어, Gale과 연구진이 개발한 Megablocks는 MoE 층의 피드포워드 네트워크(FFN) 연산을 큰 희소 행렬 곱셈으로 캐스팅하여 실행 속도를 크게 향상시키고, 서로 다른 전문가에 할당된 토큰 수가 다양한 경우를 자연스럽게 처리합니다.
또한 MoE 층은 표준 모델 병렬화 기법과 전문가 병렬화(Expert Parallelism, EP)라고 불리는 특별한 종류의 분할 전략을 통해 여러 GPU에 분산될 수 있습니다. MoE 층 실행 중에 특정 전문가에 의해 처리되어야 하는 토큰은 해당 GPU로 라우팅되어 처리되고, 전문가의 출력은 원래 토큰 위치로 반환됩니다. EP는 부하 균형 문제를 도입하는데, 개별 GPU에 과부하가 걸리거나 계산 병목 현상이 발생하는 것을 방지하기 위해 작업 부하를 GPU 전체에 균등하게 분배하는 것이 중요합니다.
트랜스포머 모델에서 MoE 층은 토큰별로 독립적으로 적용되며, 트랜스포머 블록의 피드포워드(FFN) 서브블록을 대체합니다. Mixtral에서는 전문가 함수 \(E_i(x)\)로 동일한 SwiGLU 아키텍처를 사용하고 \(K = 2\)로 설정합니다. 이는 각 토큰이 서로 다른 가중치 세트를 가진 두 개의 SwiGLU 서브블록으로 라우팅된다는 것을 의미합니다.
이를 모두 종합하면, 입력 토큰 \(x\)에 대한 출력 \(y\)는 다음과 같이 계산됩니다.
\[ y = \sum_{i=0}^{n-1} \text{Softmax}(\text{Top2}(x \cdot W_g))_i \cdot \text{SwiGLU}_i(x) \]
이 공식은 GShard 아키텍처(Lepikhin과 연구진)와 유사하지만, GShard는 모든 FFN 서브블록을 MoE 층으로 대체하는 대신 두 블록마다 하나씩 대체하고, 각 토큰에 할당된 두 번째 전문가에 대해 더 정교한 게이팅 전략을 사용한다는 차이점이 있습니다.
이해를 돕기 위해 Mixtral의 MoE 층 작동 방식을 단계별로 설명하겠습니다.
- 각 입력 토큰 \(x\)에 대해, 라우터 네트워크는 로짓 \(x \cdot W_g\)를 계산합니다.
- 이 로짓 중 가장 높은 값을 가진 상위 2개(\(K=2\))를 선택합니다.
- 선택된 로짓에 소프트맥스를 적용하여 두 전문가에 대한 가중치를 얻습니다.
- 선택된 두 전문가만 입력 토큰을 처리하고 출력을 생성합니다.
- 최종 출력은 두 전문가의 출력의 가중합으로 계산됩니다.
이러한 접근 방식의 주요 이점은 모델의 총 매개변수 수를 크게 증가시키면서도(Mixtral의 경우 47B) 각 토큰을 처리하는 데 사용되는 활성 매개변수 수는 상대적으로 적게 유지할 수 있다는 점입니다(Mixtral의 경우 13B). 이는 계산 효율성과 모델 용량 사이의 효과적인 균형을 제공합니다.
결과
Mixtral 모델을 Llama와 비교하기 위해 다양한 벤치마크에서 자체 평가 파이프라인을 통해 모든 벤치마크를 재실행했습니다. 성능은 다음과 같은 카테고리로 분류된 다양한 작업에서 측정되었습니다.
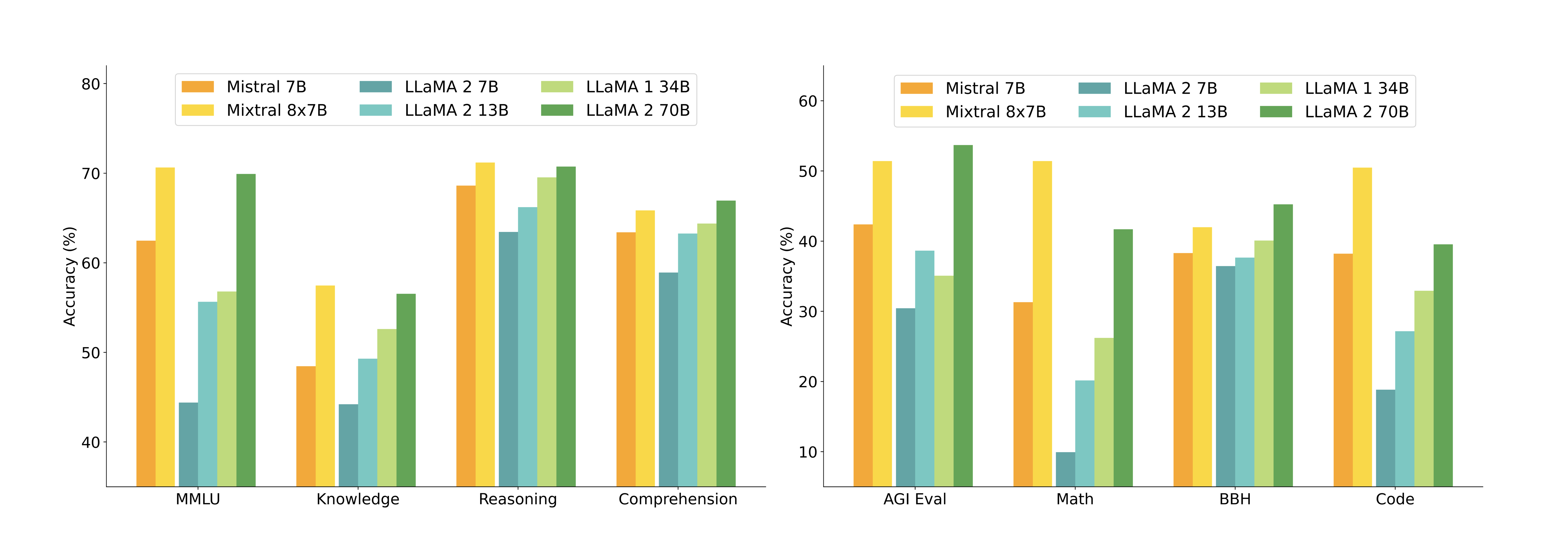
아래 표는 Mixtral과 Llama 모델 간의 상세한 성능 비교를 보여줍니다. Mixtral 8x7B는 추론 과정에서 5배 적은 활성 매개변수를 사용하면서도 거의 모든 인기 벤치마크에서 Llama 2 70B의 성능을 능가하거나 일치시킵니다.
| 모델 | 활성 매개변수 | MMLU | HellaS | WinoG | PIQA | Arc-e | Arc-c | NQ | TriQA | HumanE | MBPP | Math | GSM8K |
| LLaMA 2 7B | 7B | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 17.5% | 56.6% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | 13B | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 16.7% | 64.0% | 18.9% | 35.4% | 6.0% | 34.3% |
| LLaMA 1 33B | 33B | 56.8% | 83.7% | 76.2% | 82.2% | 79.6% | 54.4% | 24.1% | 68.5% | 25.0% | 40.9% | 8.4% | 44.1% |
| LLaMA 2 70B | 70B | 69.9% | 85.4% | 80.4% | 82.6% | 79.9% | 56.5% | 25.4% | 73.0% | 29.3% | 49.8% | 13.8% | 69.6% |
| Mistral 7B | 7B | 62.5% | 81.0% | 74.2% | 82.2% | 80.5% | 54.9% | 23.2% | 62.5% | 26.2% | 50.2% | 12.7% | 50.0% |
| Mixtral 8x7B | 13B | 70.6% | 84.4% | 77.2% | 83.6% | 83.1% | 59.7% | 30.6% | 71.5% | 40.2% | 60.7% | 28.4% | 74.4% |
평가에 사용된 벤치마크는 다음과 같은 카테고리로 분류됩니다.
- 상식 추론(0-shot): Hellaswag(Zellers와 연구진), Winogrande(Sakaguchi와 연구진), PIQA(Bisk와 연구진), SIQA(Sap와 연구진), OpenbookQA(Mihaylov와 연구진), ARC-Easy, ARC-Challenge(Clark와 연구진), CommonsenseQA(Talmor와 연구진)
- 세계 지식(5-shot): NaturalQuestions(Kwiatkowski와 연구진), TriviaQA(Joshi와 연구진)
- 독해 이해(0-shot): BoolQ(Clark와 연구진), QuAC(Choi와 연구진)
- 수학: GSM8K(Cobbe와 연구진)(8-shot, maj@8 사용), MATH(Hendrycks와 연구진)(4-shot, maj@4 사용)
- 코드: Humaneval(Chen와 연구진)(0-shot), MBPP(Austin와 연구진)(3-shot)
- 인기 종합 결과: MMLU(Hendrycks와 연구진)(5-shot), BBH(Suzgun와 연구진)(3-shot), AGI Eval(Zhong와 연구진)(3-5-shot, 영어 객관식 문제만)
아래 그림은 다양한 카테고리에서 Mixtral과 Llama 모델들의 성능을 비교합니다. Mixtral은 대부분의 지표에서 Llama 2 70B를 능가합니다. 특히 코드와 수학 벤치마크에서 우수한 성능을 보여줍니다.

크기와 효율성
Mixtral 모델의 성능을 Llama 2 계열과 비교하여 비용-성능 스펙트럼에서의 효율성을 분석했습니다. 희소 전문가 혼합 모델인 Mixtral은 각 토큰에 대해 13B 활성 매개변수만 사용합니다. 5배 적은 활성 매개변수로도 Mixtral은 대부분의 카테고리에서 Llama 2 70B를 능가할 수 있습니다.
이 분석은 추론 계산 비용에 직접적으로 비례하는 활성 매개변수 수에 초점을 맞추고 있지만, 메모리 비용과 하드웨어 활용도는 고려하지 않았습니다. Mixtral을 서빙하기 위한 메모리 비용은 희소 매개변수 수인 47B에 비례하며, 이는 여전히 Llama 2 70B보다 작습니다.
장치 활용도 측면에서는 SMoE(희소 전문가 혼합) 층이 라우팅 메커니즘과 한 장치에서 둘 이상의 전문가를 실행할 때 증가하는 메모리 로드로 인해 추가적인 오버헤드를 도입한다는 점에 주목할 필요가 있습니다. 이러한 모델은 좋은 수준의 산술 집약도에 도달할 수 있는 배치 작업에 더 적합합니다.
Llama 2 70B 및 GPT-3.5와의 비교
아래 표에서는 Mixtral 8x7B를 Llama 2 70B 및 GPT-3.5와 비교한 성능을 보고합니다. Mixtral이 두 모델과 비슷하거나 더 나은 성능을 보이는 것을 관찰할 수 있습니다. MMLU에서 Mixtral은 상당히 작은 용량(70B에 비해 47B 토큰)에도 불구하고 더 나은 성능을 얻었습니다. MT Bench의 경우, 가장 최신 GPT-3.5-Turbo 모델인 gpt-3.5-turbo-1106의 성능을 보고합니다.
| LLaMA 2 70B | GPT-3.5 | Mixtral 8x7B | |
| MMLU(57개 주제의 객관식 문제) | 69.9% | 70.0% | 70.6% |
| HellaSwag(10-shot) | 87.1% | 85.5% | 86.7% |
| ARC Challenge(25-shot) | 85.1% | 85.2% | 85.8% |
| WinoGrande(5-shot) | 83.2% | 81.6% | 81.2% |
| MBPP(pass@1) | 49.8% | 52.2% | 60.7% |
| GSM-8K(5-shot) | 53.6% | 57.1% | 58.4% |
| MT Bench(지시 모델용) | 6.86 | 8.32 | 8.30 |
평가 차이점
일부 벤치마크에서는 Llama 2 논문에서 보고된 평가 프로토콜과 차이가 있습니다. 1) MBPP에서는 수작업으로 검증된 하위 집합을 사용합니다. 2) TriviaQA에서는 위키피디아 컨텍스트를 제공하지 않습니다.
이러한 평가 방법의 차이에도 불구하고, Mixtral은 대부분의 벤치마크에서 Llama 2 70B와 GPT-3.5를 능가하거나 대등한 성능을 보여주고 있습니다. 특히 코드 생성(MBPP)과 수학 문제 해결(GSM-8K)에서 두드러진 성능 향상을 보여줍니다.
이해를 돕기 위해 덧붙이자면, Mixtral의 희소 전문가 혼합 아키텍처가 제공하는 주요 이점은 활성 매개변수 수를 크게 줄이면서도 모델의 전체 용량과 성능을 유지할 수 있다는 점입니다. 이는 각 토큰이 처리될 때 전체 모델의 일부만 활성화되기 때문에 가능합니다. 이러한 접근 방식은 특히 계산 자원이 제한된 환경에서 대규모 언어 모델을 효율적으로 배포하고 실행하는 데 큰 이점을 제공합니다.
다국어 벤치마크
Mixtral 모델은 사전 학습 과정에서 Mistral 7B에 비해 다국어 데이터의 비율을 크게 증가시켰습니다. 이러한 추가 용량 덕분에 Mixtral은 영어에서의 높은 정확도를 유지하면서도 다국어 벤치마크에서 우수한 성능을 보여줍니다. 특히 아래 표에서 볼 수 있듯이, Mixtral은 프랑스어, 독일어, 스페인어, 이탈리아어에서 Llama 2 70B를 크게 능가하는 성능을 보여줍니다.
| 모델 | 활성 매개변수 | 프랑스어 | 독일어 | 스페인어 | 이탈리아어 | ||||||||
| Arc-c | Hellas | MMLU | Arc-c | Hellas | MMLU | Arc-c | Hellas | MMLU | Arc-c | Hellas | MMLU | ||
| LLaMA 1 33B | 33B | 39.3% | 68.1% | 49.9% | 41.1% | 63.3% | 48.7% | 45.7% | 69.8% | 52.3% | 42.9% | 65.4% | 49.0% |
| LLaMA 2 70B | 70B | 49.9% | 72.5% | 64.3% | 47.3% | 68.7% | 64.2% | 50.5% | 74.5% | 66.0% | 49.4% | 70.9% | 65.1% |
| Mixtral 8x7B | 13B | 58.2% | 77.4% | 70.9% | 54.3% | 73.0% | 71.5% | 55.4% | 77.6% | 72.5% | 52.8% | 75.1% | 70.9% |
이러한 결과는 Mixtral의 다국어 성능이 매우 우수함을 보여주는 중요한 지표입니다. 특히 주목할 만한 점은 Mixtral이 활성 매개변수 수가 13B로, Llama 2 70B의 약 1/5 수준임에도 불구하고 모든 다국어 벤치마크에서 더 높은 성능을 달성했다는 것입니다. 이는 희소 전문가 혼합(Sparse Mixture of Experts) 아키텍처의 효율성과 다국어 데이터의 증가된 비율이 결합되어 나타난 결과로 볼 수 있습니다.
구체적으로 살펴보면, ARC Challenge 벤치마크에서 Mixtral은 프랑스어에서 58.2%, 독일어에서 54.3%, 스페인어에서 55.4%, 이탈리아어에서 52.8%의 정확도를 보여주며, 이는 Llama 2 70B보다 각각 8.3%, 7.0%, 4.9%, 3.4% 포인트 높은 수치입니다. Hellaswag 벤치마크에서도 Mixtral은 프랑스어에서 77.4%, 독일어에서 73.0%, 스페인어에서 77.6%, 이탈리아어에서 75.1%의 정확도를 달성하여 Llama 2 70B보다 우수한 성능을 보여줍니다.
특히 MMLU(Massive Multitask Language Understanding) 벤치마크에서 Mixtral의 성능 향상이 두드러집니다. Mixtral은 프랑스어에서 70.9%, 독일어에서 71.5%, 스페인어에서 72.5%, 이탈리아어에서 70.9%의 정확도를 기록하여, Llama 2 70B보다 각각 6.6%, 7.3%, 6.5%, 5.8% 포인트 높은 성능을 보여줍니다. MMLU는 57개의 다양한 주제에 걸친 객관식 문제로 구성된 종합적인 벤치마크로, 모델의 전반적인 언어 이해 능력을 평가하는 중요한 지표입니다.
이해를 돕기 위해 덧붙이자면, Hendrycks와 연구진이 개발한 MMLU 벤치마크는 인문학, 사회과학, STEM, 기타 분야를 포함하는 57개 주제에 걸친 다양한 객관식 문제로 구성되어 있습니다. 이 벤치마크는 모델의 광범위한 지식과 추론 능력을 평가하는 데 널리 사용됩니다. ARC Challenge는 Clark와 연구진이 개발한 과학적 추론 능력을 평가하는 벤치마크이며, Hellaswag는 Zellers와 연구진이 개발한 상식적 추론 능력을 평가하는 벤치마크입니다.
Mixtral의 다국어 성능 향상은 사전 학습 과정에서 다국어 데이터의 비율을 크게 증가시킨 결과로 볼 수 있습니다. 이는 모델이 다양한 언어의 문법, 어휘, 문화적 맥락을 더 잘 이해하고 처리할 수 있게 해줍니다. 또한 희소 전문가 혼합 아키텍처는 각 언어나 작업에 특화된 전문가들이 효과적으로 활성화되어 처리할 수 있게 함으로써, 다국어 처리 능력을 더욱 향상시킨 것으로 보입니다.
이러한 결과는 대규모 언어 모델의 다국어 성능을 향상시키는 데 있어 단순히 모델 크기를 키우는 것보다 아키텍처의 효율성과 학습 데이터의 다양성이 더 중요할 수 있음을 시사합니다. Mixtral의 접근 방식은 계산 효율성을 유지하면서도 다국어 처리 능력을 크게 향상시킬 수 있는 가능성을 보여줍니다.
장거리 성능 평가
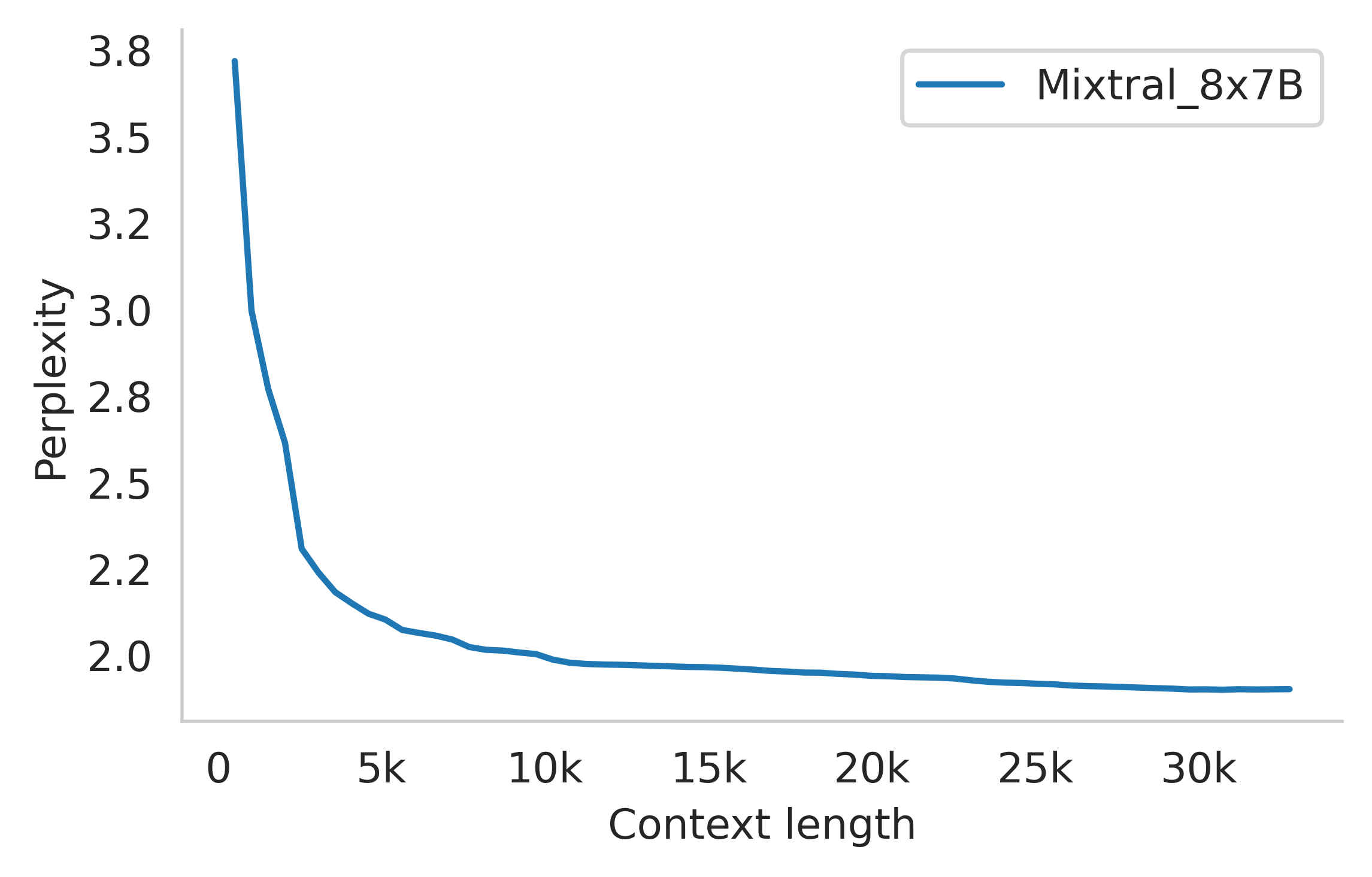
Mixtral 모델의 장거리 컨텍스트 처리 능력을 평가하기 위해, Beltagy와 연구진이 소개한 패스키 검색 작업(passkey retrieval task)을 활용했습니다. 이 작업은 긴 프롬프트 내에 무작위로 삽입된 패스키를 모델이 검색할 수 있는 능력을 측정하기 위해 설계된 합성 작업입니다. 아래 그림(왼쪽)의 결과는 Mixtral이 컨텍스트 길이나 패스키의 위치에 관계없이 100%의 검색 정확도를 달성함을 보여줍니다. 이는 모델이 긴 시퀀스에서도 중요한 정보를 효과적으로 추출할 수 있는 강력한 능력을 갖추고 있음을 의미합니다.
또한 아래 그림(오른쪽)은 Gao와 연구진이 개발한 proof-pile 데이터셋의 일부에 대한 Mixtral의 퍼플렉시티(perplexity)가 컨텍스트 크기가 증가함에 따라 단조롭게 감소함을 보여줍니다. 퍼플렉시티는 언어 모델의 성능을 평가하는 지표로, 값이 낮을수록 모델이 텍스트를 더 정확하게 예측한다는 것을 의미합니다. 이 결과는 Mixtral이 더 많은 컨텍스트를 활용할수록 더 정확한 예측을 할 수 있음을 보여주는 중요한 지표입니다.

편향성 벤치마크
미세 조정/선호도 모델링을 통해 수정해야 할 잠재적인 결함을 식별하기 위해, 기본 모델의 성능을 Bias Benchmark for QA(BBQ)와 Bias in Open-Ended Language Generation Dataset(BOLD)에서 측정했습니다. BBQ는 Parrish와 연구진이 개발한 데이터셋으로, 연령, 장애 상태, 성 정체성, 국적, 외모, 인종/민족, 종교, 사회경제적 지위, 성적 지향과 같은 9가지 사회적으로 관련된 범주에 대한 사회적 편향을 대상으로 하는 수작업으로 작성된 질문 세트로 구성되어 있습니다. BOLD는 Dhamala와 연구진이 개발한 편향성 벤치마킹을 위한 5개 도메인에 걸친 23,679개의 영어 텍스트 생성 프롬프트로 구성된 대규모 데이터셋입니다.
연구팀은 평가 프레임워크를 사용하여 Llama 2와 Mixtral을 BBQ 및 BOLD에서 벤치마킹하고 그 결과를 아래와 같이 보고했습니다. Llama 2와 비교했을 때, Mixtral은 BBQ 벤치마크에서 더 적은 편향성을 보였습니다(56.0% 대 51.5%). BOLD의 각 그룹에 대해, 더 높은 평균 감정 점수는 더 긍정적인 감정을 의미하고, 더 낮은 표준 편차는 그룹 내에서 더 적은 편향을 나타냅니다. 전반적으로, Mixtral은 Llama 2보다 더 긍정적인 감정을 표현하며, 각 그룹 내에서 비슷한 변동성을 보입니다.
| Llama 2 70B | Mixtral 8x7B | |
| BBQ 정확도 | 51.5% | 56.0% |
| BOLD 감정 점수 (평균 \( \pm \) 표준편차) | ||
| 성별 | 0.293 \( \pm \) 0.073 | 0.323 \( \pm \) 0.045 |
| 직업 | 0.218 \( \pm \) 0.073 | 0.243 \( \pm \) 0.087 |
| 종교적 이념 | 0.188 \( \pm \) 0.133 | 0.144 \( \pm \) 0.089 |
| 정치적 이념 | 0.149 \( \pm \) 0.140 | 0.186 \( \pm \) 0.146 |
| 인종 | 0.232 \( \pm \) 0.049 | 0.232 \( \pm \) 0.052 |
Llama 2 70B와 비교했을 때, Mixtral은 더 적은 편향성(BBQ에서 더 높은 정확도, BOLD에서 더 낮은 표준편차)을 보이고 더 긍정적인 감정(BOLD에서 더 높은 평균)을 표현합니다.
이해를 돕기 위해 덧붙이자면, BBQ 벤치마크에서의 정확도는 모델이 편향되지 않은 응답을 제공하는 능력을 측정합니다. 더 높은 정확도는 모델이 사회적 편향에 덜 영향을 받는다는 것을 의미합니다. Mixtral의 56.0% 정확도는 Llama 2 70B의 51.5%보다 4.5% 포인트 높은 수치로, 이는 상당한 개선을 나타냅니다.
BOLD 데이터셋에서는 각 사회적 그룹(성별, 직업, 종교적 이념, 정치적 이념, 인종)에 대한 감정 점수를 측정합니다. 감정 점수의 평균이 높을수록 해당 그룹에 대해 더 긍정적인 감정을 표현한다는 것을 의미하며, 표준편차가 낮을수록 그룹 내에서 감정 표현의 일관성이 높다는 것을 의미합니다.
Mixtral은 성별(0.323 대 0.293), 직업(0.243 대 0.218), 정치적 이념(0.186 대 0.149) 범주에서 Llama 2보다 더 높은 평균 감정 점수를 보여주며, 이는 이러한 그룹에 대해 더 긍정적인 감정을 표현한다는 것을 의미합니다. 종교적 이념 범주에서는 Mixtral이 약간 낮은 평균 점수(0.144 대 0.188)를 보이지만, 표준편차는 더 낮습니다(0.089 대 0.133). 인종 범주에서는 두 모델이 동일한 평균 점수(0.232)를 보이며, 표준편차도 비슷합니다.
특히 주목할 만한 점은 성별 범주에서 Mixtral이 더 낮은 표준편차(0.045 대 0.073)를 보인다는 것입니다. 이는 Mixtral이 성별에 관련된 텍스트를 생성할 때 더 일관된 감정 표현을 한다는 것을 의미합니다. 이러한 결과는 Mixtral이 전반적으로 더 균형 잡힌 감정 프로필을 가지고 있으며, 특히 성별과 관련된 편향이 감소했음을 시사합니다.
이러한 편향성 벤치마크 결과는 Mixtral의 희소 전문가 혼합(Sparse Mixture of Experts) 아키텍처가 단순히 성능 향상뿐만 아니라 더 균형 잡힌 출력을 생성하는 데도 도움이 될 수 있음을 보여줍니다. 이는 다양한 전문가 네트워크가 서로 다른 유형의 입력에 대해 특화되어 있어, 특정 사회적 그룹에 대한 편향된 표현을 줄이는 데 기여할 수 있기 때문입니다.
Fedus와 연구진이 설명한 바와 같이, 희소 전문가 혼합 모델은 입력에 따라 다른 전문가 네트워크를 활성화함으로써 다양한 유형의 콘텐츠를 처리하는 데 더 유연한 접근 방식을 제공합니다. 이러한 특성이 Mixtral이 사회적 편향과 관련된 벤치마크에서 더 나은 성능을 보이는 데 기여했을 가능성이 있습니다.
이러한 결과는 향후 미세 조정 및 선호도 모델링을 통해 추가적으로 개선될 수 있는 영역을 식별하는 데 중요한 정보를 제공합니다. 특히 종교적 이념과 정치적 이념 범주에서는 여전히 상대적으로 높은 표준편차를 보이고 있어, 이러한 영역에서 더 균형 잡힌 출력을 생성하기 위한 추가적인 개선이 필요할 수 있습니다.
지시 미세 조정
Mixtral 모델은 지도 학습 미세 조정(Supervised Fine-tuning, SFT)과 직접 선호도 최적화(Direct Preference Optimization, DPO)를 통해 지시사항을 따르도록 훈련되었습니다. 이 과정에서 먼저 지시 데이터셋을 사용한 지도 학습 미세 조정을 진행한 후, 쌍으로 이루어진 피드백 데이터셋에 대해 DPO를 적용했습니다.
DPO는 Rafailov와 연구진이 제안한 방법으로, 기존의 강화학습 기반 인간 피드백(RLHF) 방식과 달리 보상 모델을 명시적으로 학습하지 않고도 선호도 데이터로부터 직접 정책을 최적화할 수 있는 기법입니다. 이 방법은 변수 변환을 통해 보상 함수를 최적 정책의 관점에서 표현하여, 간단한 이진 교차 엔트로피 손실을 사용해 정책을 직접 최적화합니다. 이는 기존 RLHF 방법에서 사용되는 액터-크리틱 알고리즘의 불안정성 문제를 피할 수 있게 해줍니다.
이러한 훈련 과정을 통해 개발된 Mixtral-Instruct는 MT-Bench에서 8.30점을 기록했습니다. MT-Bench는 Zheng과 연구진이 개발한 벤치마크로, 대화형 AI 모델의 성능을 평가하기 위한 다양한 카테고리의 다중 턴 질문으로 구성되어 있습니다. 이 점수는 2023년 12월 기준으로 공개 가중치 모델 중 가장 높은 성적입니다.

위 그림은 LMSys 리더보드의 스크린샷으로, 2023년 12월 22일 기준 Mixtral 8x7B Instruct v0.1의 성능을 보여줍니다. 이 모델은 Arena Elo 평점 1121을 기록하여 Claude-2.1(1117), 모든 버전의 GPT-3.5-Turbo(최고 점수 1117), Gemini Pro(1111), 그리고 Llama-2-70b-chat(1077)을 모두 능가했습니다. 이는 Mixtral이 현재 공개된 가중치 모델 중에서 상당한 차이로 가장 우수한 성능을 보여준다는 것을 의미합니다.
이해를 돕기 위해 덧붙이자면, LMSys의 Chatbot Arena는 사용자들이 익명으로 두 개의 AI 챗봇을 비교 평가하는 플랫폼입니다. 이 평가 방식은 사용자들이 두 모델의 응답을 직접 비교하여 어느 것이 더 나은지 판단하게 함으로써, 모델 간의 상대적 성능을 측정합니다. Elo 평점 시스템은 체스 선수들의 실력을 평가하는 데 사용되는 방식과 유사하게, 모델 간의 승패 기록을 바탕으로 상대적 성능을 수치화합니다. 높은 Elo 점수는 다른 모델들과의 비교에서 더 자주 선호된다는 것을 의미합니다.
Mixtral-Instruct가 이처럼 높은 성능을 달성할 수 있었던 이유 중 하나는 희소 전문가 혼합(Sparse Mixture of Experts) 아키텍처의 효율성입니다. 이 아키텍처는 각 토큰이 처리될 때 전체 매개변수 중 일부만 활성화되도록 하여, 계산 효율성을 유지하면서도 모델의 전체 용량을 크게 증가시킬 수 있습니다. 또한 DPO를 통한 미세 조정 과정은 모델이 인간의 선호도에 더 잘 부합하는 응답을 생성하도록 도와줍니다.
MT-Bench에서의 높은 점수와 LMSys 평가에서의 우수한 성능은 Mixtral-Instruct가 단순히 기술적 벤치마크뿐만 아니라 실제 사용자와의 상호작용에서도 뛰어난 능력을 갖추고 있음을 보여줍니다. 특히 GPT-3.5-Turbo와 같은 상용 모델들을 능가했다는 점은 주목할 만합니다.
이러한 결과는 희소 전문가 혼합 아키텍처와 효과적인 미세 조정 방법론을 결합함으로써, 계산 효율성과 모델 성능 사이의 균형을 맞추는 새로운 접근 방식의 가능성을 보여줍니다. Mixtral-Instruct의 성공은 향후 대규모 언어 모델 개발에 있어 중요한 방향성을 제시할 것으로 기대됩니다.
라우팅 분석
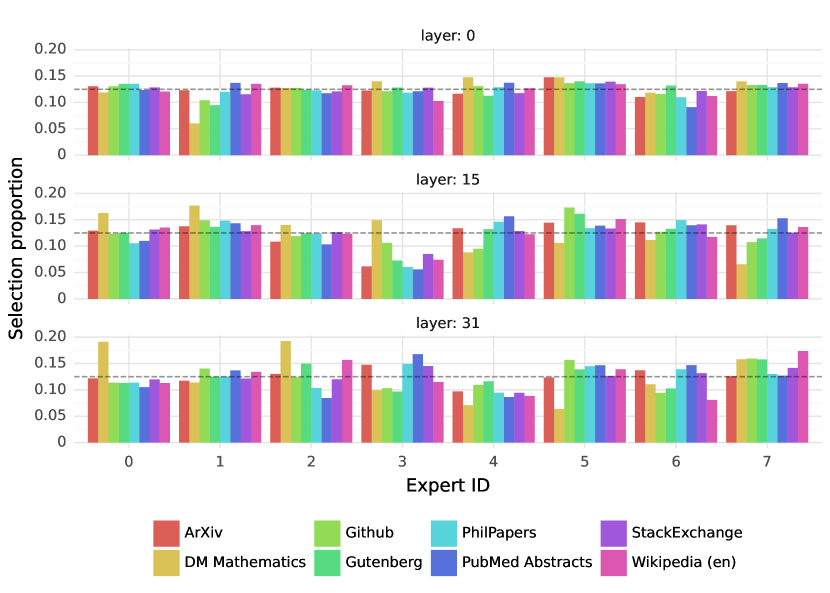
이 섹션에서는 라우터에 의한 전문가 선택에 대한 간단한 분석을 수행합니다. 특히 학습 과정에서 일부 전문가들이 특정 도메인(예: 수학, 생물학, 철학 등)에 특화되었는지 여부를 조사하고자 합니다. 이를 위해 The Pile 검증 데이터셋의 다양한 하위 집합에서 선택된 전문가의 분포를 측정했습니다. 결과는 아래 그림에 제시되어 있으며, 모델의 첫 번째 층(0층), 중간 층(15층), 마지막 층(31층)에 대한 분석을 보여줍니다.
놀랍게도, 주제에 기반한 전문가 할당에서 명확한 패턴은 관찰되지 않았습니다. 예를 들어, 모든 층에서 LaTeX로 작성된 ArXiv 논문, 생물학(PubMed Abstracts), 철학(PhilPapers) 문서에 대한 전문가 할당 분포는 매우 유사했습니다. 오직 DM Mathematics에서만 약간 다른 전문가 분포가 관찰되었습니다. 이러한 차이는 데이터셋의 합성적 특성과 자연어 스펙트럼의 제한된 범위 때문일 가능성이 높으며, 특히 입력 및 출력 임베딩과 매우 상관관계가 높은 첫 번째 층과 마지막 층에서 두드러집니다. 이는 라우터가 일종의 구조화된 구문적 행동을 보여준다는 것을 시사합니다.
아래 그림은 다양한 도메인(Python 코드, 수학, 영어)의 텍스트 예시를 보여주며, 각 토큰은 선택된 전문가에 해당하는 배경색으로 강조되어 있습니다. 이 그림은 Python의 'self'와 영어의 'Question'과 같은 단어들이 여러 토큰으로 구성되어 있음에도 불구하고 종종 동일한 전문가를 통해 라우팅된다는 것을 보여줍니다. 마찬가지로 코드에서 들여쓰기 토큰은 항상 동일한 전문가에 할당되는데, 특히 은닉 상태가 모델의 입력 및 출력과 더 상관관계가 높은 첫 번째 및 마지막 층에서 그러합니다.
또한 아래 그림에서 연속된 토큰들이 종종 동일한 전문가에 할당되는 것을 관찰할 수 있습니다. 실제로 The Pile 데이터셋에서 일정 수준의 위치적 지역성(positional locality)이 관찰됩니다.

| 첫 번째 선택 | 첫 번째 또는 두 번째 선택 | |||||
| 층 0 | 층 15 | 층 31 | 층 0 | 층 15 | 층 31 | |
| ArXiv | 14.0% | 27.9% | 22.7% | 46.5% | 62.3% | 52.9% |
| DM Mathematics | 14.1% | 28.4% | 19.7% | 44.9% | 67.0% | 44.5% |
| Github | 14.9% | 28.1% | 19.7% | 49.9% | 66.9% | 49.2% |
| Gutenberg | 13.9% | 26.1% | 26.3% | 49.5% | 63.1% | 52.2% |
| PhilPapers | 13.6% | 25.3% | 22.1% | 46.9% | 61.9% | 51.3% |
| PubMed Abstracts | 14.2% | 24.6% | 22.0% | 48.6% | 61.6% | 51.8% |
| StackExchange | 13.6% | 27.2% | 23.6% | 48.2% | 64.6% | 53.6% |
| Wikipedia (en) | 14.4% | 23.6% | 25.3% | 49.8% | 62.1% | 51.8% |
위 표는 도메인과 층별로 연속된 토큰이 동일한 전문가 할당을 받는 비율을 보여줍니다. 토큰 \(i\)와 그 다음 토큰 \(i+1\)에 동일한 전문가가 할당되는 비율을 평가합니다. 첫 번째로 선택된 전문가가 동일한 경우와 연속된 토큰에서 첫 번째 또는 두 번째 선택으로 동일한 전문가가 관찰되는 경우를 보고합니다. 참고로, 무작위 할당의 경우 예상되는 반복 비율은 "첫 번째 선택"의 경우 \(\frac{1}{8}=12.5\%\)이고, "첫 번째와 두 번째 선택"의 경우 \(1-\frac{6}{8}\frac{5}{7}\approx 46\%\)입니다. 첫 번째 층에서의 반복은 무작위에 가깝지만, 층 15와 31에서는 상당히 높습니다. 높은 반복 횟수는 이러한 층에서 전문가 선택이 높은 시간적 지역성을 보여준다는 것을 나타냅니다.
연속적인 할당의 비율은 상위 층에서 무작위보다 상당히 높습니다. 이는 빠른 학습 및 추론을 위한 모델 최적화 방법에 영향을 미칩니다. 예를 들어, 높은 지역성을 가진 경우 전문가 병렬화(Expert Parallelism)를 수행할 때 특정 전문가의 과도한 구독(over-subscription)을 유발할 가능성이 높습니다. 반대로, 이러한 지역성은 Eliseev와 Mazur의 연구에서처럼 캐싱에 활용될 수 있습니다.
이해를 돕기 위해 덧붙이자면, 이 분석은 Mixtral 모델의 라우팅 메커니즘이 어떻게 작동하는지에 대한 중요한 통찰력을 제공합니다. Fedus와 연구진이 설명한 바와 같이, 희소 전문가 혼합(Sparse Mixture of Experts) 모델에서 라우팅 패턴을 이해하는 것은 모델의 효율성과 성능을 최적화하는 데 중요합니다.
특히 주목할 만한 점은 전문가 선택이 주제 기반이 아니라 구문 구조와 더 관련이 있다는 발견입니다. 이는 전문가들이 특정 주제 영역(예: 수학, 생물학)보다는 언어의 구조적 패턴(예: 코드의 들여쓰기, 특정 단어 형태)에 특화되었을 가능성을 시사합니다. 이러한 패턴은 모델이 언어의 구문적 특성을 효과적으로 포착하고 처리하는 방식을 보여줍니다.
또한 연속된 토큰이 동일한 전문가에 할당되는 높은 비율은 시간적 지역성(temporal locality)이라는 중요한 특성을 나타냅니다. 이는 Gale과 연구진이 개발한 MegaBlocks와 같은 시스템에서 활용될 수 있는 특성으로, 블록 희소 연산을 통해 MoE 계산을 효율적으로 수행할 수 있게 합니다.
위 표의 데이터를 자세히 살펴보면, 층 15에서 시간적 지역성이 가장 높게 나타나는 것을 볼 수 있습니다. 예를 들어, DM Mathematics 데이터셋에서는 첫 번째 또는 두 번째 선택으로 동일한 전문가가 연속된 토큰에 할당되는 비율이 67.0%에 달합니다. 이는 무작위 할당에서 예상되는 46%보다 훨씬 높은 수치입니다. 이러한 패턴은 모델의 중간 층에서 특정 언어 패턴이나 구조에 대한 처리가 더 특화되어 있을 가능성을 시사합니다.
이러한 라우팅 분석 결과는 Mixtral과 같은 희소 전문가 혼합 모델의 설계 및 최적화에 중요한 시사점을 제공합니다. 특히 전문가 병렬화 구현 시 부하 균형(load balancing)을 고려해야 하며, 캐싱 전략을 통해 시간적 지역성을 활용하여 추론 효율성을 향상시킬 수 있습니다. 또한 이러한 발견은 향후 MoE 모델 설계에서 전문가의 역할과 특화에 대한 더 깊은 이해를 위한 기반을 제공합니다.
결론
본 논문에서는 오픈소스 모델 중 최초로 최첨단 성능을 달성한 전문가 혼합 네트워크인 Mixtral 8x7B를 소개했습니다. Mixtral 8x7B Instruct는 인간 평가 벤치마크에서 Claude-2.1, Gemini Pro, GPT-3.5 Turbo를 능가하는 성능을 보여주었습니다. 각 타임스텝에서 단 두 개의 전문가만 사용하기 때문에, Mixtral은 토큰당 13B의 활성 파라미터만 사용하면서도 토큰당 70B 파라미터를 사용하는 이전 최고 모델(Llama 2 70B)보다 우수한 성능을 달성했습니다. 연구팀은 학습된 모델과 미세 조정된 모델을 Apache 2.0 라이선스 하에 공개적으로 제공하고 있습니다. 이러한 모델 공개를 통해 다양한 산업과 분야에서 활용될 수 있는 새로운 기술과 응용 프로그램의 개발을 촉진하고자 합니다.
연구의 의의와 기여
Mixtral 8x7B의 개발은 대규모 언어 모델 분야에 중요한 기여를 했습니다. 희소 전문가 혼합(Sparse Mixture of Experts) 아키텍처를 통해 계산 효율성과 모델 성능 사이의 균형을 효과적으로 달성했다는 점이 가장 주목할 만한 성과입니다. 이 모델은 각 토큰이 처리될 때 전체 파라미터의 일부만 활성화함으로써, 계산 비용을 크게 줄이면서도 대형 모델의 성능을 유지할 수 있음을 보여주었습니다.
특히 Mixtral 8x7B는 수학, 코드 생성, 다국어 처리 등 다양한 영역에서 Llama 2 70B를 능가하는 성능을 보여주었습니다. 이는 희소 전문가 혼합 아키텍처가 단순히 계산 효율성을 높이는 것뿐만 아니라, 다양한 도메인에 특화된 능력을 개발하는 데도 효과적임을 시사합니다.
또한 Mixtral 8x7B Instruct 모델은 지도 학습 미세 조정(Supervised Fine-tuning)과 직접 선호도 최적화(Direct Preference Optimization)를 통해 인간의 지시를 더 잘 따르도록 훈련되었으며, 이를 통해 상용 모델인 Claude-2.1, Gemini Pro, GPT-3.5 Turbo를 능가하는 성능을 달성했습니다. 이는 오픈소스 모델이 상용 모델과 경쟁할 수 있는 수준에 도달했음을 보여주는 중요한 이정표입니다.
기술적 혁신
Mixtral의 핵심 기술적 혁신은 희소 전문가 혼합 아키텍처의 효과적인 구현에 있습니다. 이 아키텍처는 Shazeer와 연구진이 제안한 개념을 기반으로 하며, 각 입력 토큰이 처리될 때 라우터 네트워크가 8개의 전문가 중 2개를 동적으로 선택하여 처리하는 방식으로 작동합니다. 이러한 접근 방식은 모델의 총 파라미터 수(47B)와 활성 파라미터 수(13B) 사이의 균형을 효과적으로 맞추어, 계산 효율성과 모델 용량 사이의 최적점을 찾았습니다.
또한 Mixtral은 Vaswani와 연구진이 제안한 트랜스포머 아키텍처와 Jiang과 연구진이 개발한 Mistral 7B의 개선 사항을 통합하여, 32k 토큰의 컨텍스트 길이를 지원하는 강력한 모델을 구축했습니다. 이는 장문의 텍스트를 처리하고 이해하는 능력을 크게 향상시켰습니다.
라우팅 분석 결과에서는 전문가 선택이 주제 기반이 아니라 구문 구조와 더 관련이 있다는 흥미로운 발견이 있었습니다. 이는 전문가들이 특정 주제 영역보다는 언어의 구조적 패턴에 특화되었을 가능성을 시사합니다. 또한 연속된 토큰이 동일한 전문가에 할당되는 높은 비율은 시간적 지역성(temporal locality)이라는 중요한 특성을 나타내며, 이는 Eliseev와 Mazur의 연구에서 제안한 것처럼 캐싱을 통한 추론 최적화에 활용될 수 있습니다.
오픈소스 공개의 의미
Mixtral 8x7B와 Mixtral 8x7B Instruct 모델을 Apache 2.0 라이선스로 공개한 것은 AI 연구 커뮤니티와 산업계에 중요한 의미를 갖습니다. 이러한 공개는 다양한 응용 분야에서 고성능 언어 모델을 활용할 수 있는 기회를 제공하며, 추가적인 연구와 혁신을 촉진할 것으로 기대됩니다.
특히 연구팀은 커뮤니티가 완전히 오픈소스 스택으로 Mixtral을 실행할 수 있도록 vLLM 프로젝트에 Gale과 연구진이 개발한 Megablocks CUDA 커널을 통합하는 변경사항을 제출했습니다. 이는 Mixtral 모델의 접근성과 활용성을 더욱 높이는 중요한 기여입니다.
향후 연구 방향
Mixtral의 성공은 희소 전문가 혼합 모델이 대규모 언어 모델 개발의 중요한 방향성이 될 수 있음을 시사합니다. 향후 연구에서는 더 많은 전문가를 활용하거나, 전문가 선택 메커니즘을 개선하거나, 다양한 도메인에 특화된 전문가를 훈련시키는 등의 방향으로 발전할 가능성이 있습니다.
또한 Clark와 연구진이 제안한 라우팅 네트워크의 통합 스케일링 법칙과 같은 이론적 연구를 통해, 희소 전문가 혼합 모델의 성능과 효율성을 더욱 향상시킬 수 있는 방법을 탐색할 수 있을 것입니다.
Zhou와 연구진이 제안한 전문가 선택 라우팅(Expert Choice Routing)과 같은 대안적인 라우팅 메커니즘도 Mixtral 아키텍처에 통합하여 성능을 더욱 향상시킬 수 있는 가능성이 있습니다.
결론적으로, Mixtral 8x7B는 희소 전문가 혼합 아키텍처를 통해 계산 효율성과 모델 성능 사이의 최적점을 찾아낸 중요한 연구 성과입니다. 이 모델의 공개는 AI 연구 커뮤니티와 산업계에 고성능 언어 모델을 더 효율적으로 개발하고 활용할 수 있는 새로운 가능성을 열어주었습니다. 향후 이러한 접근 방식이 더욱 발전하여 더 효율적이고 강력한 AI 시스템의 개발로 이어질 것으로 기대됩니다.
References
Subscribe to my newsletter
Read articles from Jonas Kim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jonas Kim
Jonas Kim
Sr. Data Scientist at AWS