Decode ai jargons with a late night chai
 Deepanshu Agarwal
Deepanshu AgarwalENCODER:
Suppose that we can have a one of a complex puzzle so we can breakdown it can a small pieces to that in can easily can we understand for a ai models that small pieces is called as a latent representations .
Encoders are used to reduce clutter, find important patterns, and spot weird or unusual things in data. In creative AI, these summaries act as a foundation for generating cool, creative stuff.
Decoder:
It can we reverse of a encoder . let us takes a one examples of it when we have a summary of some things so we can want to combined in a puzzle then it can be known as a decoder Decoders also add a touch of creativity to produce something new and unique based on what they learned.

Vocab size :
in a ai model we have their own dictionary often called its vocabulary . this voccabulary contains words or smaller than words which can knows as chunks(tokens) that the model can recognizes it can we easy to implement vocab size of open ai is a about 50000tokens
example code of vocab size:
# Simple vocabulary
vocabulary = {
"hello": "Hi there!",
"how": "I'm good!",
"bye": "Goodbye!"
}
# Function to generate a response
def chatbot_response(word):
if word in vocabulary:
return vocabulary[word] # Find the response in the vocabulary
else:
return "I don't understand that." # For unknown words
# User input
user_input = "hello" # Try "how", "bye", or any other word
# Generate response
response = chatbot_response(user_input)
print("Chatbot says:", response)
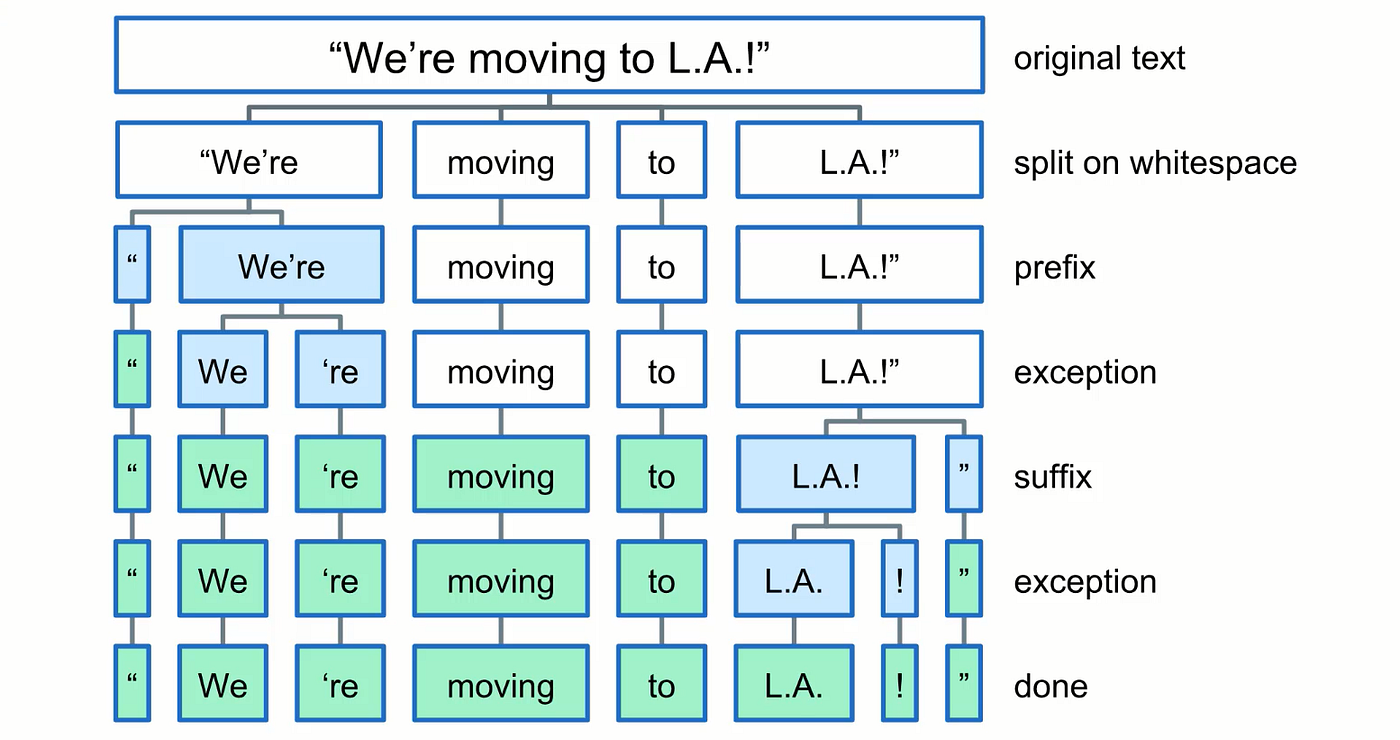
tokenizations
tokenization is a budling process of a gen ai and natural language process it is a refes to breaking down text into smaller pieces it is called tokens and this process is know as tokenization these tokens are a building blocks that models ,like which can use gen ai to understand a human body in a text.
Tokenization allows AI models to analyze and learn patterns in text, enabling them to predict or generate coherent language. It's an essential step because it translates human language into a format that AI models can interpret and work with.
knowledge cutoff
it is known as a a last update data which can we present in a ai models after that ai models cant we know anythings knowledge cutoff is a two much costly process it can not be done easily it can takes lots of time and gpu.
Softmax :
The SoftMax function is a mathematical tool that converts raw scores into probabilities, making them easier to interpret in classification problems. It ensures the probabilities for all classes add up to 1, helping AI models make decisions.
import numpy as np
def softmax(logits):
exp_logits = np.exp(logits)
probabilities = exp_logits / np.sum(exp_logits)
return probabilities
# Example usage:
logits = [2.0, 1.0, 0.1] # raw scoree examples
probabilities = softmax(logits)
print("Input scores:", logits)
print("SoftMax probabilities:", probabilities)
Temperature in gen ai
it can only provide a flexibility to our ai models is that how much type of data is rigid and accurate it to according to a given content is it can we can a temperature in a gen ai in a range that if the temperature is lower that our data is too much close to given prompt if a temperature is high then our data is accurate to a given context but not as close that as compared to fast
Sematic Embeddings
now let us take a example which is based of a semantic embeddings we can have a two sentence like that i love apple or apple phone is to costly in a sentence there is a apple in a two types of sentence in a first we can have a apple means is fruit and another sentence apple is a brand of phone with a help of that semantic embeddings ai models can differentiate between both of it with a help of complex mathematical algorithms .
from sentence_transformers import SentenceTransformer, util
# Load a pre-trained semantic model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Two example sentences
sentence1 = "I need a place to save my money."
sentence2 = "Where is the nearest bank?"
# Generate embeddings for both sentences
embedding1 = model.encode(sentence1, convert_to_tensor=True)
embedding2 = model.encode(sentence2, convert_to_tensor=True)
# Compute the similarity score
similarity = util.pytorch_cos_sim(embedding1, embedding2)
print(f"Semantic similarity score: {similarity.item()}")
Positional encoding
Imagine you’re reading a story and the sequence of events is all jumbled—confusing, right? Similarly, when computers process language, they need to know the position of words in a sentence to make sense of it. Positional encoding helps solve this by tagging each word in a sentence with information about its position. Unlike humans who naturally understand order by reading left to right, computers treat text as a bag of unrelated words unless explicitly told how the words are sequenced. Positional encoding provides a "road map" for computers, ensuring they understand the order of words and how they relate to one another.
Why Does Order Matter? Let’s look at two sentences:
The same words are used, but the order changes the meaning entirely. Positional encoding ensures that NLP models recognize this difference and produce accurate results for tasks like translation, summarization, or answering questions. Without positional encoding, a model might mix up word orders, leading to incorrect or nonsensical outputs.
vector embedding
what is vector?
vector is a 2 d array of a numbers
Think of words as dots on a giant map. Each dot represents a word, and the distance between the dots shows how similar those words are in meaning. For example:
Now, vector embeddings are just the coordinates of those dots. Instead of saying, "dog is here and puppy is nearby," the embedding gives numbers like:
These numbers capture the meaning of each word and its relationships to other words. Why is this useful? Computers don’t understand words like we do—they understand numbers. By turning words into these meaningful numbers
Subscribe to my newsletter
Read articles from Deepanshu Agarwal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by