Decoding AI Jargons with Chai
 Ansh Mittal
Ansh MittalTable of contents
- 1. Transformers
- 2.Encoder
- 3.Decoder
- 4.Tokenization
- 5.Vector Embedding
- 6.Positional Encoding
- Real-Life Example
- 7.Self Attention
- 8.Multi-Head Attention:
- 🔥 Real-Life Analogy :
- 💡 Example Sentence:
- 9.Feed Forward Neural Network
- Real-Life Example:
- 10.Loss Calculation
- 💡 Simple Analogy:
- 11.Backpropagation
- 📘 Real-Life Example
- 12.Softmax
- 🍽️ Real-Life Example
- 13.Knowledge cutoff
- 🧾 Why It Exists?
- 14.Semantic meaning
- 15.Vocab Size
- 16.Temparature

☕ #ChaiCode: Sipping on AI Jargon with a Dash of Fun! ☕
Ever tried reading AI papers? Feels like decoding Rahu-Ketu charts 🔮—let’s turn ‘Yeh kya hai?’ into ‘Arre, asaan hai!’"
here is the full blog about the understand of AI Jargons word with simple and relatable example. This is the only place for understanding all AI Jargons words.
List of Terminology which we will understand
Transformers
Encoder
Decoder
Tokenization
Vector Embedding
Positional Encoding
Self Attention
Multi- Head Attention
Feed Forward Neural Network
Loss Calculation
Back Propagation
Softmax
Knowledge Cutoff
Semantic Meaning
Vocab Size
Temperature
1. Transformers
Transformer is a smart system or Architecture in AI that understands sequential data like text or audio, and predicts the next element by finding relationships between inputs using the self-attention mechanism.
Transformer Architecture introduced by the Google in 2017 in his research paper of “Attention All you need”
Research Paper -
This Architecture used by many AI Model for example:- GPTs, Claude, Github Coplilot, BERL etc.
Here is the image of transformer
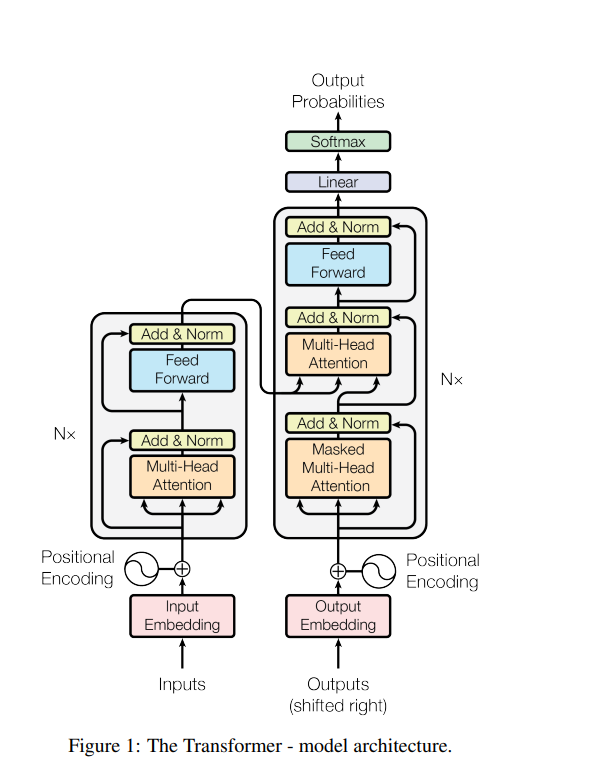
Transformers have a many steps to predict next word or data.
Tokenization
Vector Embedding
Positional Encoding
Self Attention
Multi-Head Attention
Feed Forward Neural Network
Loss Calculation
Backpropagation
Output Generation
2.Encoder
An encoder is used to process user input like text or audio by first breaking it into tokens (small meaningful units), and then converting those tokens into token IDs — which are numerical representations understood by the model.
In Transformer models like BERT or T5, the encoder helps the model understand the full context of the input before any prediction or generation step happens.
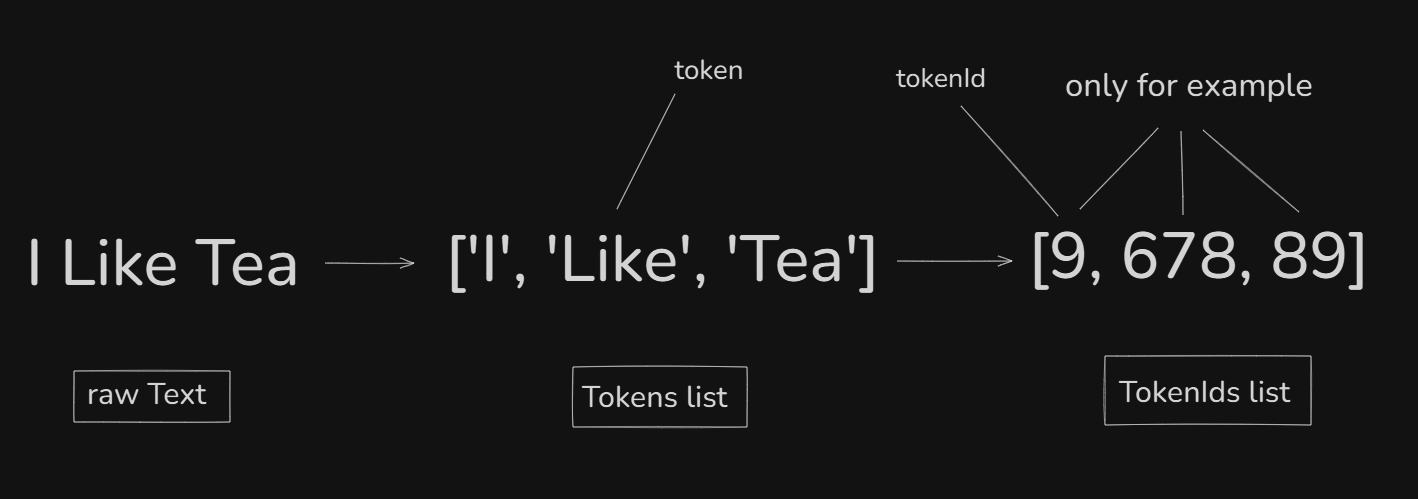
What is Token
A token can be a word, subword, character, or even part of a word — depending on the tokenization strategy used by the model. Different models use different tokenizers like Word-level, Byte Pair Encoding (BPE), WordPiece, or SentencePiece.
3.Decoder
A decoder takes the processed token IDs (from the encoder or previous output steps) and generates meaningful output — such as text, audio, or any other target format, depending on the model's purpose.
4.Tokenization
Tokenization is process in which raw text is converted into smaller units called tokens, and each token is then mapped to a token ID (numeric number) so that the language model can understand it.
Q:- Why is it Important ?
Language models can understand only numbers, not plain text.
Example :-
Raw text :- I Like Tea
Tokens:- [’I’, ‘like’, ‘tea’]
Token Ids:- [67, 948, 748] // example only
Q:- What happen if we change the word order?
if you change the order of the text, the tokens and token IDs stay the same, but their positions change, which affects the meaning.
Raw text :- Tea Like I
Tokens:- [‘tea’, ‘Like’, ‘I’]
Token Ids:- [748, 948, 67] // example only
Since language models understand order using positional endcoding, changing word positions changes the meaning.
5.Vector Embedding
Vector embedding is the process of converting text (or audio, image, etc.) into meaningful numeric vectors that capture the meaning and relationships between the data.
These vectors live in a high-dimensional space (sometimes visualized as 3D) and can be stored in a vector database for searching and comparison.
Vector embedding visulaization
Vector Embedding Visualization — How It Works
In a 3D vector space, every word or sentence becomes a point. The model understands meaning by measuring the distance or direction between these points.
It’s like saying:
“If cold tea is to summer, then ginger tea is to...?”
The model finds the relationship (distance) between cold tea and summer, then applies that same offset to ginger tea to predict a related word.
📊 Example in 3D Space:
Let’s imagine vectors like this:
"cold tea"→ 📍(1.2, 2.1, 0.9)"summer"→ 📍(2.2, 3.1, 1.5)
➡️ Relationship (offset):summer - cold tea = (1.0, 1.0, 0.6)
Now apply the same to:
"ginger tea"→ 📍(1.1, 1.9, 1.0)
➡️ Add the offset:ginger tea + (1.0, 1.0, 0.6) ≈ 📍(2.1, 2.9, 1.6)
Now the model searches:
“Which word is closest to (2.1, 2.9, 1.6)?”
And finds:
👉 "winter"
Boom. The prediction is made.
🧮 This is Called: Vector Arithmetic
Just like this famous one:
nginxCopyEditking - man + woman ≈ queen
We now have:
nginxCopyEditsummer - cold tea + ginger tea ≈ winter
🔚 Final One-Liner:
The model captures relationships between words as vectors, then uses those relationships to predict new words based on directional meaning in space.
6.Positional Encoding
Transformers are powerful — but there's a limitation
They don’t know the order of words automatically.
So to solve this, we use Positional Encoding — a method to give each word a sense of position in a sentence.
What Exactly Is Positional Encoding?
Every word is converted into a vector (like:
[0.5, 0.2, 0.9, ...])But all words are treated equally — no idea which came first or last.
So, we add another vector called the position vector, which depends on:
The position number of the word (1st word, 2nd word…)
A special sinusoidal pattern (not random)
This combined vector (word + position) helps the model understand order.
Real-Life Example
Let’s say your mom tells you:
Drink tea in the morning, then have breakfast, then study.
Now imagine the order messed up:
"Study, drink tea, then breakfast" — makes no sense!."
You’d be totally confused — tea after study? 🙃
Now Imagine:
Each instruction is a word embedding.
Without position:
- The model only sees the words, not what comes first.
With positional encoding:
The model knows:
"tea"came at position 1"breakfast"at position 2"study"at position 3
So it respects the order, like you would if your mom gave you a to-do list!
🛕 Another Example (Temple Visit):
Correct order:
"First wash your feet, then enter the temple, then start prayer."
If this order changes:
"Start prayer, enter temple, then wash feet" — disrespectful 😬
So positional encoding helps the model respect sequences, just like you follow temple rituals step-by-step 🛕
🔚 Final One-Liner:
Positional encoding is like adding "step numbers" to each word, so the AI follows the correct order, just like we follow steps in a daily routine or festival ritual.
7.Self Attention
In self-attention, every word is allowed to look at every other word and decide how important they are to its own meaning — like a smart conversation between tokens.
Real-Life Example of Self-Attention
Imagine you're hearing this sentence:
"Raju gave his brother a gift because he was happy."
Now the question is — who was happy? Raju or his brother? 🤔
To understand "he", your brain pays attention to other words like "Raju", "brother", and the overall context.
This is exactly what self-attention does:
Every word looks at the other words and figures out which ones are important to understand the meaning.
8.Multi-Head Attention:
It’s like giving the model multiple brains (or multiple sets of eyes 👀), so it can look at the same sentence from different angles or contexts — like “what”, “when”, “who”, “where”, etc.
Why Not Just One Attention?
Because one attention head might focus only on:
“What is happening?”
Another might focus on:
“Who is doing it?”
So instead of limiting to one view, we let the model have multiple views at once.
🔥 Real-Life Analogy :
Imagine your teacher is checking your essay.
She reads it 4 times:
First time: Focus on grammar
Second time: Focus on facts
Third time: Focus on tone
Fourth time: Focus on flow
Same essay — but checked from different perspectives.
That's what Multi-Head Attention does:
It runs self-attention multiple times in parallel, each with different “focus”, then combines everything.
💡 Example Sentence:
"Virat Kohli scored a century in the final match yesterday."
Different heads may focus on:
Who? → "Virat Kohli"
What? → "scored a century"
When? → "yesterday"
Where? → "in the final match"
Each head captures a different semantic detail, then all are combined and passed forward.
🔚 Final One-Liner:
Multi-Head Attention lets the model look at the sentence in multiple ways at the same time, so it can understand deeper relationships — not just one shallow meaning.
9.Feed Forward Neural Network
A Feed Forward Neural Network (in Transformers) is like a mini decision-maker that takes the attention output and says:
“Okay, I’ve seen the full context… now let me process it and give something meaningful.”
🎯 In Other Words:
It takes the info from the attention layer ✅
Makes the info sharper, richer, or more useful ✅
Like a refining machine 🔧
Real-Life Example:
Imagine this:
You got advice from 4 friends (multi-head attention) on what to wear for a wedding.
Now you sit down and say:
“Okay, let me think about all this logically.”
You filter it in your brain → combine their advice → pick the final outfit.
That thinking & final decision step = Feed Forward Neural Network 🧠💭
🔚 Final One-Liner:
Feed Forward Neural Network is the layer that takes the attention result and refines it into a stronger, smarter output, before passing it on to the next transformer block.
10.Loss Calculation
Loss calculation is how the model measures how wrong its prediction was.
It’s like asking:
“How far is my answer from the correct answer?”
Bigger difference = the higher the loss 😬
Smaller difference = model is learning well 😎
que:- Model doesn’t know the correct output so how loss will be calculated ?
Answer:- Loss is only used during training to trained our model.
👉 During inference time (real-world use), the model doesn't know the right answer — it just guesses based on what it learned.
During training time,
the AI does know the correct output — because we give it the correct data!
It’s like:
We’re the teacher 👩🏫
Model is the student 👦
We give it questions + answers (input + correct output)
And then we see: “How wrong was your answer?”
This is called supervised learning.
💡 Simple Analogy:
Imagine you’re teaching a kid math:
You ask: 2 + 2 = ?
Kid says: 5 ❌
You say: No, correct answer is 4
Now the kid adjusts his brain 👶🧠
That “how wrong was he” = loss
And that’s how learning happens!
🧪 Example:
You ask the model:
“I like chai in the morning and coffee at _____?”
Model predicts:
"night"
But correct answer is:
"evening"
Now the model checks:
"Oops! I'm close… but not exact."
So it calculates the loss value — like a penalty score.
This number (loss) is used in the next step:
→ Backpropagation to fix the model’s weights 🧠
11.Backpropagation
Backpropagation is the process of telling the model - “Hey! You made a mistake — now go back and fix your brain (weights) so you do better next time!”
It happens after we calculate loss (how wrong the prediction was).
Backpropagation does 3 things:
Takes the loss (error)
Traces it backward through the entire neural network
Updates the weights (the learning part) using a method called gradient descent
It’s like saying:
“This neuron contributed 30% to the mistake… so adjust it a bit”
“This one was 70% wrong… adjust more!”
The goal = Make the loss smaller next time ✅
📘 Real-Life Example
🎓 You’re a Student Learning English:
You write a sentence:
“I goes to school.”
Teacher says: ❌ “No! It’s ‘I go to school.’”
Now you:
Realize you made a mistake → (loss)
Think backwards →
“Hmm… subject is ‘I’ → I shouldn’t use ‘goes’.”
“It should be ‘go’.”
You update your brain → Next time, you’ll write it correctly ✅
This thinking backwards and adjusting your mind = Backpropagation
🔚 Final One-Liner:
So , Backpropagation is how AI learns from its mistakes — it sends the error backward through the model and tweaks its internal settings (weights) so it performs better next time 🧠⚙️
12.Softmax
When a model is choosing the next word, it doesn’t just guess randomly.
Instead, it gives scores (called logits) to all the possible words.
But those scores are just raw numbers.
We need to convert them into something meaningful, like:
🟢 “How likely is each word to be the right one?”
That’s what Softmax does:
It converts raw scores into probabilities between 0 and 1,
and all the probabilities add up to 1 (100%).
Then, the model picks the word with the highest probability.
🍽️ Real-Life Example
Situation:
You’re hungry at a wedding and see:
Paneer
Biryani
Gulab Jamun
You rate them in your head:
Paneer: 2
Biryani: 5
Gulab Jamun: 3
Now, apply Softmax (your brain does it!):
It converts those scores into probabilities:
Paneer → 10%
Biryani → 70%
Gulab Jamun → 20%
🎯 You pick Biryani, because your brain said it’s the most probable best choice.
Same way, the AI picks the most probable next word in a sentence!
🔚 Final One-Liner:
Softmax takes the model’s raw scores and converts them into clear probabilities, so it can confidently pick the most likely next word — just like your brain picking your favorite food from the menu 🍽️
13.Knowledge cutoff
Knowledge cut-off means the latest point in time up to which the AI (like me) was trained on real-world data.
Once that date is passed, the AI does not know anything newer than that point — unless connected to the internet (like with browsing tools).
🧾 Why It Exists?
Because:
Training an AI model takes a lot of time, energy, and data
You can't keep updating the model every second — so they lock it at a certain time and say:
👉 "Everything after this = unknown"
So, Knowledge cut-off is the AI’s last update date — it’s like a student who stopped studying after a specific chapter and doesn’t know what happened next 📚🚫
14.Semantic meaning
Semantic meaning is the real meaning or context behind a word or sentence — not just the words themselves, but what they actually mean.
🧠 In other words:
It's not about what the word is, but what it means in the sentence.
💡 Example 1:
“Apple” can mean:
🍎 a fruit
🖥️ a tech company
Semantic meaning depends on the sentence:
"I updated my Apple device" → means the company, not the fruit.
15.Vocab Size
Vocabulary size is like the dictionary of the AI model — the total number of unique tokens (words, subwords, characters, emojis, etc.) that the model understands.
Whenever you give input — like text or audio — the AI breaks it into tokens (small chunks), and then converts those tokens into numbers (called token IDs) using this vocab list.
🧠 You can think of it like:
Every token has its own roll number in the AI’s language class 📘
Different AI models are trained on different data — so:
Some may know 50,000 tokens
Some may handle 100,000 or more
So yes, every model has its own vocabulary size, depending on how it was trained and what it was trained on.
🔚 Final One-Liner:
“Vocabulary size is the size of the token list that the AI model uses to convert text or audio into token IDs (numeric form).
Each model has its own vocabulary, so the vocab size may vary depending on how the model is built and what data it learned from — just like different students know different number of words 📚🧠.”
16.Temparature
Temperature is a setting controls the creativity vs confidence of the AI. Lower = predictable, Higher = surprising.
Low temperature (e.g. 0.2) =
More confident, safe, and predictable output
AI picks the most likely words
Feels boring but accurate
High temperature (e.g. 0.9 or 1.2) =
More creative, diverse, and random
AI takes risks and explores less common words
Feels fun but possibly weird or wrong
Imagine you’re ordering food on Swiggy:
Low temperature (0.2) →
You always pick Paneer Butter Masala — safe & trusted!
High temperature (1.0) →
You suddenly go for Thai Green Curry or Sushi — risky, but could be exciting! 🍣
Same with AI:
Low temp → “I like drinking hot tea.”
High temp → “I like drinking hot juice / soup / lava?!” 😂
🚀 Wrapping up – These AI jargon terms might sound heavy at first, but with the right chai and curiosity, they start making sense sip by sip. Keep learning, keep experimenting!
#ChaiCode ☕🤖 | Where tech meets tapri talks
Subscribe to my newsletter
Read articles from Ansh Mittal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ansh Mittal
Ansh Mittal
I have a MERN Development knowledge and Strong JavaScript expertise and frontend development expertise for creating user-friendly websites along with impressive functionalities. I can deliver maintainable and scalable code with Best Practices of coding, SEO and Web accessibility. I can create website with AI Integration or Rag Systems.