Decoding AI jargons with chai #chaicode
 Mrityunjay Kumar
Mrityunjay Kumar
#chaicode #GenAi #cohort
What is covered?
What is AI?
AI = Data + Algorithm
What is GPT (Generative Pretrained Transformer)?
Predicts the next token from a set of data that is already available to it. It is a transformer.
Problem: Real-world data ke uppar kaam nhi krta hai, kyuki knowledge cutoff hota hai.
Knowledge Cutoff
Does not know anything beyond pre-trained data date.
How does the transformer model work?
It is beautifully stated in Attention is all you need, a white paper by Google.

A transformer can be broken into several phases: a. Input Embedding b. Positional Encoding c. Self-attention Mechanism d. Multi-head attention e. Feed Forward f. Output Embedding
Encoder
It is used for taking input.
Let’s dive deep into each phase:
💡Input Embedding:
It is the text that we input into any transformer, say chatGpt
As the input is taken, the input query is converted into tokens.
Tokenization
This process splits the words and assigns them a mathematical number taken from the vocabulary.
Note: Every model has their tokenization system.
Vocabulary
It is a kind of dictionary for each model, where each token (word or subword) is assigned a unique mathematical number.
No. of unique tokens = vocabulary size

we can also tokenize and check the vocabulary using code:
import tiktoken
encoder = tiktoken.encoding_for_model('gpt-4o')
print("Vocab Size", encoder.n_vocab)
text = "The cat sat on the mat"
tokens = encoder.encode(text)
print(text,tokens)
Output:

Vector Embedding:
It gives semantic meaning to the words. This takes place in a 3D plane.
visualisation

3D space visualisation:

What is semantic meaning?
Meaning of a word in a particular context.
For example, Bank - the side of a river or Bank - it is a financial institution.
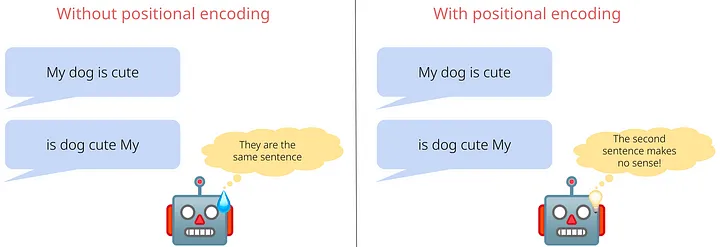
💡Positional Encoding
This tells us the position of the tokens.
For example, the cat sat on the mat & the mat sat on the cat
Tokens will be the same for both the sentences, and vector embedding will also be the same.
💡 Self-Attention Mechanism
tokens talk to themselves and update.
Tokens talk to each other to adjust their embeddings.

Here, tokens can talk to each other and let the token Bank adjust its meaning as per the requirement.
Issue: It always has one head.
💡Multi-head attention
Focusing on the different aspects of tokens
💡Feed Forward
is a neural network that provides the output.
Note: The interaction cycle between multi-head and Feed Forward is repeated so many no. of times to get rich contextual result.
Decoder:
It provides us our soul, i.e Output.
Some more buzzing words
Inference:
Inference is the process by which a trained model makes predictions or generates outputs based on new, unseen data.
Temperature:
creativity allowed in the response. The higher the temperature, the higher the creativity.
Synthesized Data:
The data that are generated by models like ChatGPT.
Note: Models that are trained on synthesized data are less intelligent.
SoftMax:
It is the game changer- The decision maker.
It is a mathematical function that turns raw scores into probabilities.
Let's say the model sees:
"The weather is very"
| Token | Score | After Softmax |
| cold | 4.2 | 0.65 (65%) |
| hot | 3.1 | 0.20 (20%) |
| rainy | 2.0 | 0.10 (10%) |
| sweet | 1.2 | 0.05 (5%) |
Here, cold wins as it has the highest probability.
Credits
I would like to thank Hitesh Choudhary sir, Piyush Garg sir, for the amazing cohort and lastly, if anyone of you reading this & wants to join me in learning the same, use my code KMRITYUN21567 to get 10% off on all the courses on the chaicode.com
Thank you so much ❣️.
Subscribe to my newsletter
Read articles from Mrityunjay Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by