Understanding the Basics of AI: Supervised, Unsupervised, Semi-Supervised & Reinforcement Learning
 Kashaf Naveed
Kashaf NaveedTable of contents

Understanding the Basics of AI: Supervised, Unsupervised, Semi-Supervised & Reinforcement Learning
Introduction
Artificial Intelligence (AI) is changing the world by allowing machines to learn from data and make smart decisions.
Categories:
Narrow AI (specific tasks)
General AI (human-level intelligence, theoretical)
Super AI (surpasses human intelligence, hypothetical)
Types of AI:
1- Machine learning(ML
2-Deep Learning(DL)
Machine Learning
At the heart of AI is Machine Learning (ML) ML a technique that enables computers to improve their performance without being directly programmed.
In this blog, we’ll explore the four major types of machine learning in simple language, along with real-world examples and commonly used algorithms:
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
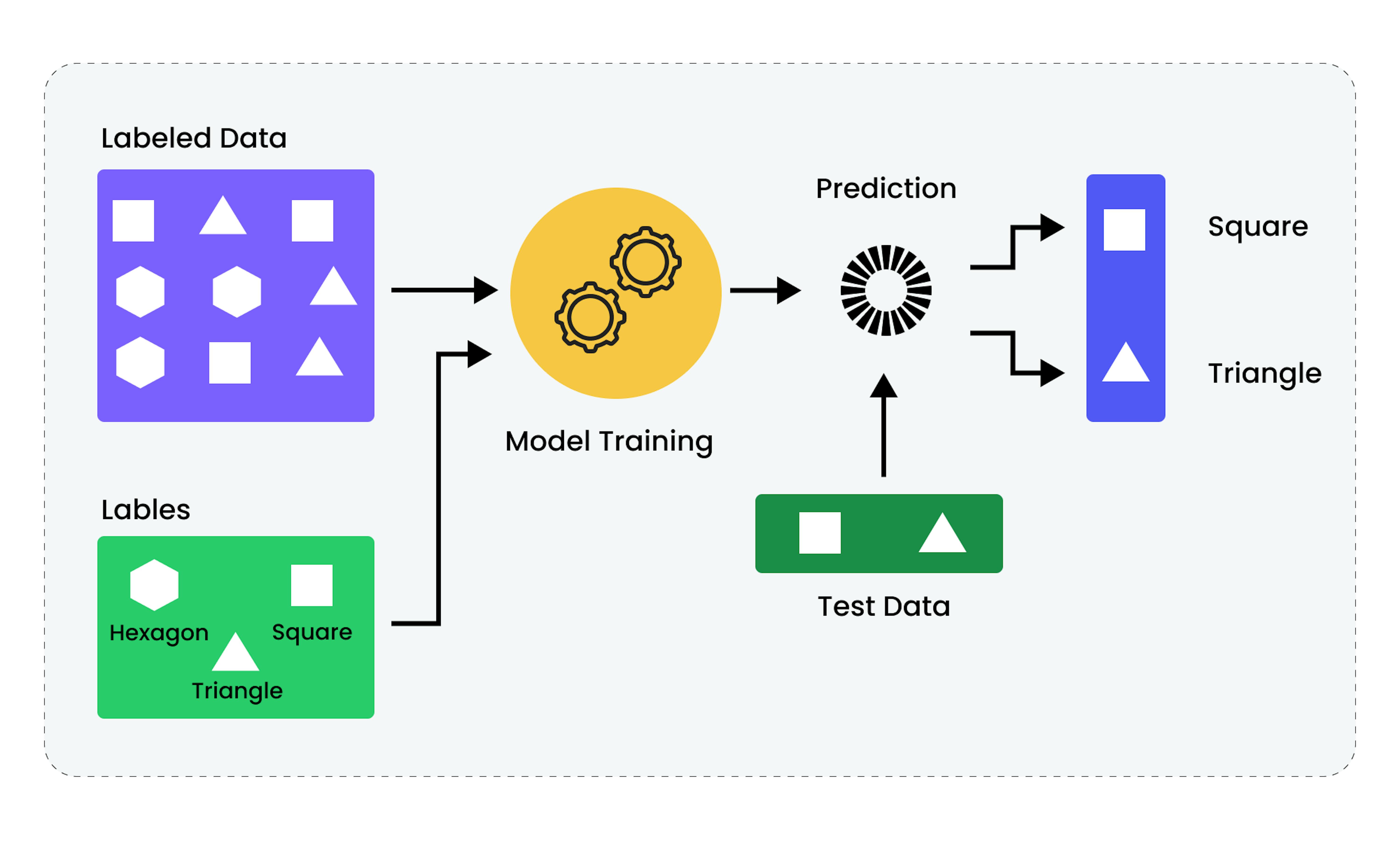
1. Supervised Learning
What is it?
Supervised Learning involves labeled training data with known input and output pairs used to create models for predicting output from new inputs.
How it works:
Input → Model → Predicted Output (compared with Actual Output)
Real-World Examples:
- Spam email detection
- Credit score prediction
- Medical diagnosis (e.g., identifying diseases in scans)
Common Algorithms:
- Linear Regression (predicts values like house or wheat prices)
- Logistic Regression (used for classification problems)
- Decision Trees
- Random Forests
- Support Vector Machines (SVM)
- k-Nearest Neighbors (k-NN)
- Naive Bayes

Simple Analogy:
It’s like a teacher helping a student by providing the answers during practice.
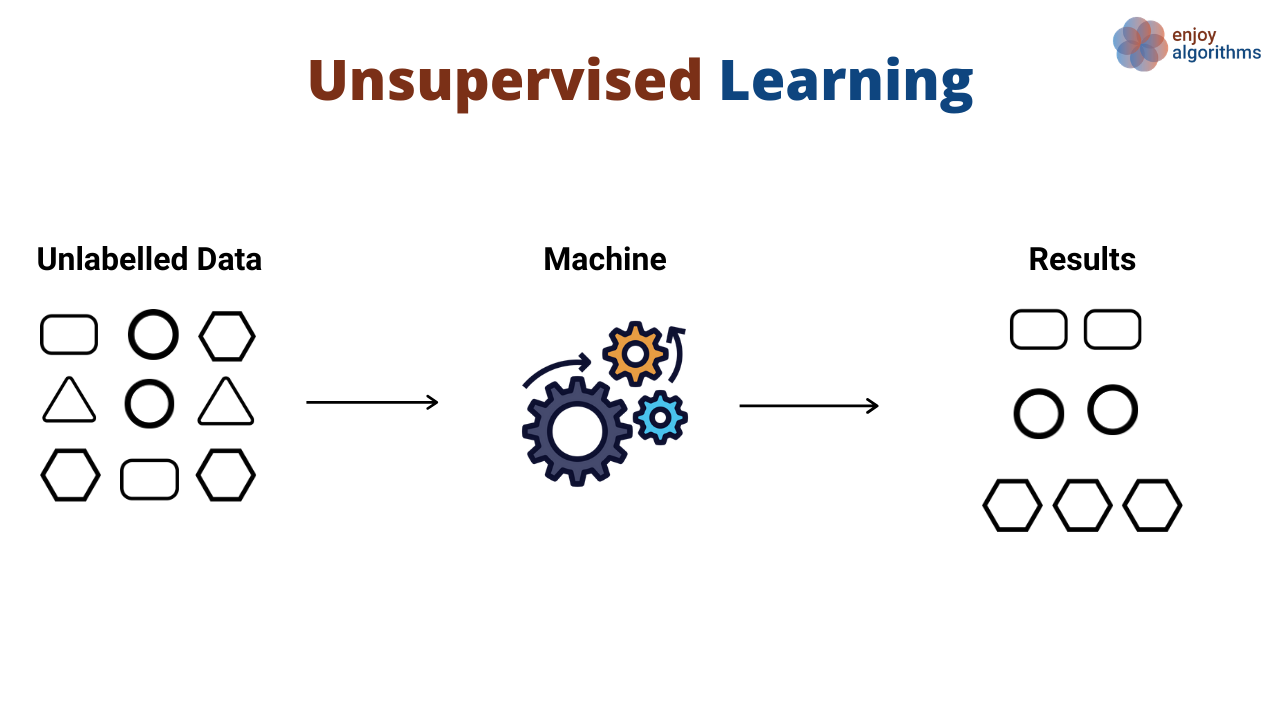
2. Unsupervised Learning
What is it?
Unsupervised uses unlabeled data to create clusters based on its observed data/patterns. It tries to find hidden patterns or groupings in the data and and gradually refining these clusters over time.
How it works:
Input → Model → Output (Grouped/Clustered Data)
Real-World Examples:
- Grouping customers for marketing
- Detecting unusual network activity
- Organizing similar documents or news articles
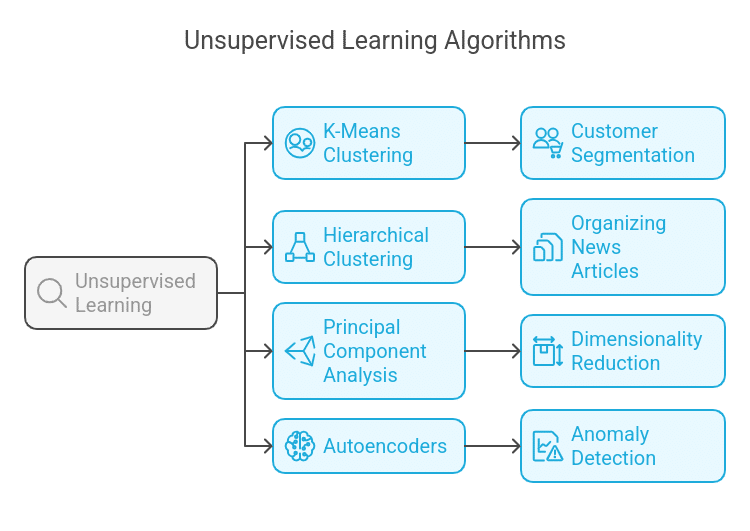
Common Algorithms:
1-K-Means Clustering
2- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
3- Hierarchical Clustering
4- Principal Component Analysis (PCA)
5- Autoencoders (for dimensionality reduction)
1. K-Means Clustering
Groups similar data points into ‘K’ clusters. The number of clusters (K) is decided based on domain knowledge ,elbow method (graphical method),silhouette analysis (cluster quality measure) ,gap statistics (comparison with expected) or cross validation.
Example: Grouping employees based on experience and performance gap.
2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Forms clusters based on data point density. Dense areas(closeness of features) form clusters, while sparse points(low density data points) are treated as noise.
Example: Analyzing traffic data on Google Maps.
3. Hierarchical Clustering
A clustering algorithm that that groups data points into a tree like clusters (called dandrogram).This is achieved by either iterative merging the closest pairs of clusters (agglomerative approach) or by iteratively splitting the largest clusters into smaller ones (divine approach).The hierarchy allows for exploring different levels of granularity in clustering.
- Agglomerative (Bottom-up): Starts with individual points and merges them until the desired result is achieved.
- Divisive (Top-down): Starts with one big cluster and splits it until the desired result is achieved.
4. Principal Component Analysis (PCA)
Reduces the number of features while keeping the main structure of the data. Makes complex data easier to understand.
Example:
A 100x100 pixel image has 10,000 features. PCA compresses it into fewer features without losing important info.
5. Autoencoders
A type of neural network that compresses data and then tries to reconstruct it. Great for dimensionality reduction.
Examples:
- Image compression
- Anomaly/Fraud detection
3. Semi-Supervised Learning
What is it?
Semi-supervised learning mixes both labeled and unlabeled data. It helps when labeling is expensive or time-consuming.
- Labeled data gives accurate, reliable results.
- Unlabeled data finds new patterns but might be less accurate.

How it works:
The model learns from the labeled data and uses the unlabeled data to refine its understanding.
Real-World Examples:
- Voice/speech recognition
- Web page classification
- Medical image analysis (where labels are costly to get)
Common Algorithms:
- Self-training
- Co-training
- Graph-based models
- Semi-supervised SVM
- Generative models
Simple Analogy:
Like a student who learns from a few teacher-guided examples and solves similar problems on their own.
4. Reinforcement Learning
What is it?
Reinforcement learning (RL) is about learning by interacting with an environment. The model (called an agent) uses rewards and penalties to develop policies for decision making.
How it works:
Agent → Takes Action → Gets Reward/Penalty → Learns → Repeats

Real-World Examples:
- Game AI (chess, AlphaGo)
- Robot movement/navigation
- Self-driving cars
- Dynamic pricing (e.g., in e-commerce)
"While studying RL, I found it similar to how humans learn—by doing something and learning from the consequences."
Key Terms:
- Agent: Learner
- Environment: The system the agent interacts with
- Action: What the agent decides to do
- Reward/Penalty: Feedback received
Common Algorithms:
- Q-Learning: Learns best decisions in different scenarios
- SARSA: Similar to Q-learning but updates its values on actions taken
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks
- Policy Gradient Methods: Directly optimize action strategies
- PPO (Proximal Policy Optimization): A stable and efficient policy gradient method that avoids large updates and improves training performance..
- Monte Carlo Methods: Learn by averaging rewards across multiple trials

Simple Analogy:
Like training a puppy—reward it when it behaves well, and it learns through feedback.
📊 Comparison Table
| Learning Type | Data Used | Common Algorithms | Real-Life Use Case |
| Supervised | Labeled | SVM, Decision Tree, k-NN, Regression | Spam detection, disease diagnosis |
| Unsupervised | Unlabeled | K-Means, DBSCAN, PCA, Autoencoders | Customer segmentation, fraud alert |
| Semi-Supervised | Both Labeled + Unlabeled | Self-training, Graph-based methods | Speech recognition, medical scans |
| Reinforcement | Environment + Feedback | Q-Learning, DQN, PPO | Game AI, robotics, self-driving |
✅ Pros & Cons Table
| Learning Type | Pros | Cons |
| Supervised | High accuracy with labeled data | Needs a lot of labeled data |
| Unsupervised | Finds hidden structures | Hard to measure how good it is |
| Semi-Supervised | Less costly than full labeling | Still requires some labeled data |
| Reinforcement | Learns from actions & feedback | Can be slow and needs lots of trials |
Conclusion
These four types of learning are the core of modern AI:
- Supervised Learning: Best when labeled data is available
- Unsupervised Learning: Useful for discovering hidden patterns
- Semi-Supervised Learning: Effective when labeled data is limited
- Reinforcement Learning: Ideal for learning through experience
Understanding their differences and use cases is essential for diving deeper into AI and applying the right method to the right problem.
Thanks for reading! If you enjoyed this, follow me for more beginner-friendly AI and ML content. 🚀
Subscribe to my newsletter
Read articles from Kashaf Naveed directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by