My DSA Grind – Day 5 Solutions
 Saivaishnav Ambati
Saivaishnav Ambati
📑 Table of Contents
- Introduction
Problems List
Longest Common Prefix
Delete Node in a Linked List
Remove Nth Node from the End of List
Reverse Linked List
Merge Two Sorted Lists
- Conclusion
✨ Introduction
Welcome to Day 5 of my 90 Days DSA Challenge!
Today, I focused on mastering some important string and linked list problems which are commonly asked in interviews. These problems tested my understanding of pointer manipulation, string traversal, and edge case handling.
1️⃣ Longest Common Prefix

✅ Approach & Logic
🔹 Method 1: Pairwise Comparison (Prefix Shrinking)
Start with the prefix length as the first string's length.
Compare each pair of strings in the array.
For each pair, check how long the prefix matches.
Update the minimum prefix length after each comparison.
Finally, return the substring from
0tominLen.
🔧 Why this works:
We shrink the valid prefix length with each pairwise mismatch, so we end up with the exact max match length.

🔹 Method 2: Vertical Scanning (Character-by-Character)
First, find the minimum string length among all strings.
Then loop index by index (i.e., vertically), comparing each character at the same position across all strings.
The moment a mismatch is found, return the substring up to that index.
If no mismatch is found, return the substring from 0 to
minLen.
🔧 Why this works:
Since all strings must match character-by-character from the beginning, this method directly checks the common prefix across all strings simultaneously.

📊 Dry Run / Key Observations
🧪 Input: ["flower", "flow", "flight"]
Method 1:
Initial
minLen = 6(length of"flower")Compare
"flower"and"flow"→ common"flow"→j=4Update
minLen = 4Compare
"flow"and"flight"→ compare up to index 4 → common"fl"→j=2Final
minLen = 2→ Return"fl"
Method 2:
minLen = 4(shortest string is"flow")i = 0 →
'f'matches for all → continuei = 1 →
'l'matches for all → continuei = 2 →
"flight"has'i', but others have'o'→ mismatchReturn
"fl"
🎨 Physical Representation
Let’s visualize Method 2:
pgsqlCopyEditInput: ["flower", "flow", "flight"]
Index: 0 1 2 3 4 5
-----------------------------
flower f l o w e r
flow f l o w
flight f l i g h t
Step 1: Compare column 0 → all 'f' ✅
Step 2: Compare column 1 → all 'l' ✅
Step 3: Compare column 2 → 'o' ≠ 'i' ❌ → return "fl"
🔍 Edge Cases Handled
✅ Array of size 1 → return that string
✅ No common prefix → return
""✅ All strings are the same → return the string
✅ Empty strings inside array → return
""✅ Different length strings → handled via
minLen
💡 What I Learned
I learned two efficient ways to solve the Longest Common Prefix problem:
Shrinking the prefix by pairwise comparison
Vertical scanning across all strings character-by-character.
This problem showed me the importance of both horizontal and vertical traversal strategies in string problems.
2️⃣ Delete Node in a Linked List

Example 1:
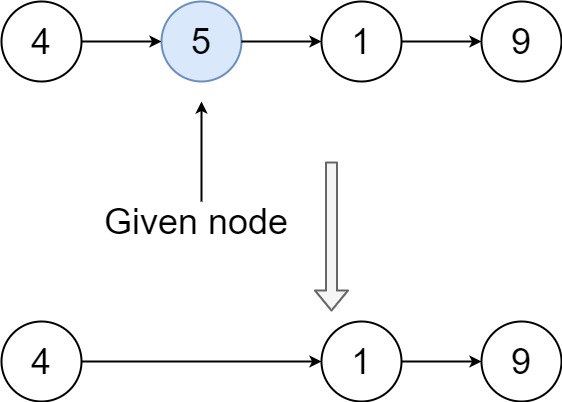
Input: head = [4,5,1,9], node = 5
Output: [4,1,9]
Explanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.
Example 2:
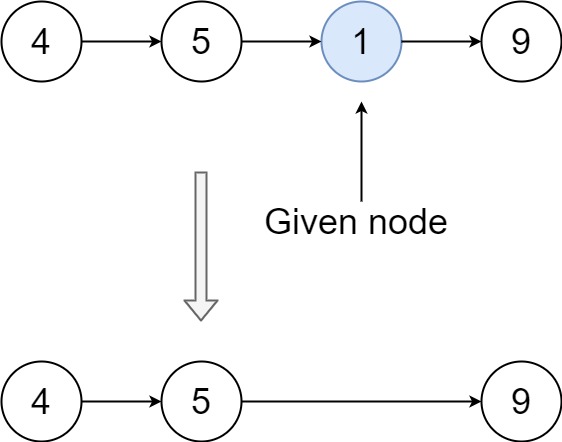
Input: head = [4,5,1,9], node = 1
Output: [4,5,9]
Explanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.
Constraints:
The number of the nodes in the given list is in the range
[2, 1000].-1000 <= Node.val <= 1000The value of each node in the list is unique.
The
nodeto be deleted is in the list and is not a tail node.
✅ Approach & Logic
We're given only a reference to the node that needs to be deleted, not the head of the list.
To delete a node in a singly linked list, you usually need access to the previous node. But here, we don’t have that.
So, the trick is:
🔁 Copy the data from the next node to the current node,
➡️ then skip over the next node by updating thenextpointer.
✔ Steps:
node.val =node.next.val→ overwrite current node’s value with the next node’s value.node.next=node.next.next→ skip the next node, effectively deleting it.
🧠 We're not really deleting the node we were given — we're copying the next one into it and deleting that one!
class Solution {
public void deleteNode(ListNode node) {
node.val=node.next.val;
node.next=node.next.next;
}}
📊 Dry Run / Key Observations
🧪 Input Linked List:
1 → 2 → 3 → 4 → 5
↑
node to delete
Step-by-Step:
node = 3node.val =node.next.val→ node becomes4node.next=node.next.next→ skip4, now list is:
1 → 2 → 4 → 5
Result: node 3 has been replaced by 4, and the original 4 is gone.
🎨 Physical Representation
Before:
Head → 1 → 2 → 3 → 4 → 5
↑
node to delete
After:
Head → 1 → 2 → 4 → 5
The node with value
3now acts like the node with value4.The original
4node is removed from the chain.
🔍 Edge Cases Handled
- 🚫 You’re guaranteed that the node to be deleted is not the tail, so we don’t need to handle null checks for
node.next.
💡 What I Learned
I learned a clever in-place trick to delete a node in a linked list without access to the head. Instead of deleting the node directly, I learned how to copy and bypass the next node to simulate deletion.
3️⃣ Remove Nth Node From the End of List
Given the head of a linked list, remove the n<sup>th</sup> node from the end of the list and return its head.
Example 1:

Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1
Output: []
Example 3:
Input: head = [1,2], n = 1
Output: [1]
Constraints:
The number of nodes in the list is
sz.1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
✅ Approach & Logic
✨ Method 1: Two Pass Approach (Find Length First)
We first calculate the total length of the linked list, then determine the position from the front using length - n.
✔ Steps:
Traverse the list once to calculate its length (
len).Create a dummy node and link it to the head (to handle edge cases like removing the head itself).
Start from dummy and move
len - ntimes to reach the previous node of the one to be deleted.Modify the
nextpointer to skip the nth node.Return
dummy.nextas the new head.
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
int len=0;
ListNode cur =head;
while(cur!=null){
cur=cur.next;
len=len+1;
}
ListNode dummy=new ListNode(0);
dummy.next=head;
ListNode prev=dummy;
int jumps=len-n;
while(jumps>0){
prev=prev.next;
jumps=jumps-1;
}
prev.next=prev.next.next;
return dummy.next;
✨ Method 2: One Pass Approach (Two Pointers)
This is a more optimized solution using two pointers – fast and slow – to do the job in a single pass.
✔ Steps:
Move the
fastpointernsteps ahead.Start both
fastandslowfrom dummy (before head).Move both pointers one step at a time until
fastreaches the end.Now
slowwill be right before the node to be deleted.Remove that node by skipping its pointer.
Return
dummy.next.
int currjumps=n;
ListNode cur=head;
while(currjumps!=0){
cur=cur.next;
currjumps=currjumps-1;
}
ListNode dummy=new ListNode(0);
dummy.next=head;
ListNode prev=dummy;
while(cur!=null)
{
cur=cur.next;
prev=prev.next;
}
prev.next=prev.next.next;
return dummy.next;
📊 Dry Run / Key Observations
Input:
javaCopyEdithead = [1, 2, 3, 4, 5], n = 2
🧪 Method 1 Dry Run:
Full length = 5
Position to delete from front =
5 - 2 = 3Go 3 steps from dummy → reach node with value 3
Skip next (node 4) → result:
[1, 2, 3, 5]
🧪 Method 2 Dry Run:
Move
fast2 steps → now at node 3Start
slowat dummyMove both until
fastreaches endslowwill be at node 3Skip node 4 → result:
[1, 2, 3, 5]
🎨 Physical Representation
Initial List:
cssCopyEdit[1] -> [2] -> [3] -> [4] -> [5]
After Removing 2nd Node from End (Node with value 4):
cssCopyEdit[1] -> [2] -> [3] -> [5]
🔍 Edge Cases Handled
✅ Removing the head node.
✅ Removing the last node.
✅ Removing when the list has only one node.
✅ Handles all using a dummy node for simplicity.
💡 What I Learned
Using a dummy node helps elegantly handle edge cases.
Two-pass method is easier to understand but less efficient.
Single-pass method with two pointers is more optimized and elegant.
This is a classic pattern for problems like detecting/removing kth elements from the end in a list.
4️⃣ Reverse Linked List
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:

Input: head = [1,2,3,4,5]
Output: [5,4,3,2,1]
Example 2:

Input: head = [1,2]
Output: [2,1]
Example 3:
Input: head = []
Output: []
Constraints:
- The number of nodes in the list is the range
[0, 5000].
-5000 <= Node.val <= 5000
✅ Approach & Logic
This is an iterative solution to reverse a linked list in-place using three pointers:
curr– Points to the current node we’re processing.prev– Tracks the previous node (initially null).next– Temporarily stores the next node to not lose the link.
✔ Steps:
Start with
curr = head,prev = nullLoop while
curr != null:After the loop,
prevwill point to the new head of the reversed list.
📊 Dry Run / Key Observations
Input:
head = [1, 2, 3, 4, 5]
Iteration-wise Status:
| Step | curr.val | next.val | prev.val | Action |
| 1 | 1 | 2 | null | Reverse link, move pointers |
| 2 | 2 | 3 | 1 | Reverse link, move pointers |
| 3 | 3 | 4 | 2 | Reverse link, move pointers |
| 4 | 4 | 5 | 3 | Reverse link, move pointers |
| 5 | 5 | null | 4 | Reverse link, move pointers |
Final Output:
[5] -> [4] -> [3] -> [2] -> [1]
class Solution {
public ListNode reverseList(ListNode head) {
ListNode curr=head;
ListNode prev=null;
while(curr!=null){
ListNode next=curr.next;
curr.next=prev;
prev=curr;
curr=next;
}
return prev;
}
}
🎨 Physical Representation with Diagrams
Initial List:
head → [1] → [2] → [3] → [4] → [5] → null
↑
curr
prev = null
🔁 Iteration 1:
curr = [1],next = [2],prev = null
Before Reversing:
prev = null
curr = [1] → [2] → [3] → [4] → [5] → null
Step:
After Reversing:
prev = [1] → null
curr = [2] → [3] → [4] → [5] → null
🔁 Iteration 2:
curr = [2],next = [3],prev = [1]
Before Reversing:
prev = [1] → null
curr = [2] → [3] → [4] → [5] → null
Step:
After Reversing:
prev = [2] → [1] → null
curr = [3] → [4] → [5] → null
🔁 Iteration 3:
curr = [3],next = [4],prev = [2]
Before Reversing:
prev = [2] → [1] → null
curr = [3] → [4] → [5] → null
Step:
next =curr.next→[4]curr.next= prev→[3] → [2] → [1] → nullprev = curr→[3]curr = next→[4]
After Reversing:
prev = [3] → [2] → [1] → null
curr = [4] → [5] → null
🔁 Iteration 4:
curr = [4],next = [5],prev = [3]
Before Reversing:
prev = [3] → [2] → [1] → null
curr = [4] → [5] → null
Step:
next =curr.next→[5]curr.next= prev→[4] → [3] → [2] → [1] → nullprev = curr→[4]curr = next→[5]
After Reversing:
prev = [4] → [3] → [2] → [1] → null
curr = [5] → null
🔁 Iteration 5:
curr = [5],next = null,prev = [4]
Before Reversing:
prev = [4] → [3] → [2] → [1] → null
curr = [5] → null
Step:
next =curr.next→nullcurr.next= prev→[5] → [4] → [3] → [2] → [1] → nullprev = curr→[5]curr = next→null
After Reversing:
prev = [5] → [4] → [3] → [2] → [1] → null
curr = null
✅ Final Output:
return prev; // head of the new reversed list
[5] → [4] → [3] → [2] → [1] → null
🔍 Edge Cases Handled
✅ Empty list (
head == null)✅ Single element list (automatically reversed)
✅ Multiple elements
💡 What I Learned
Reversing a linked list can be done in O(n) time and O(1) space using just three pointers.
Pointer manipulation is key in linked list problems – store the next node before changing any link!
This is a foundational problem for mastering linked list manipulation and recursion alternatives.
5️⃣ Merge Two Sorted Lists
You are given the heads of two sorted linked lists list1 and list2.
Merge the two lists into one sorted list. The list should be made by splicing together the nodes of the first two lists.
Return the head of the merged linked list.
Example 1:

Input: list1 = [1,2,4], list2 = [1,3,4]
Output: [1,1,2,3,4,4]
Example 2:
Input: list1 = [], list2 = []
Output: []
Example 3:
Input: list1 = [], list2 = [0]
Output: [0]
Constraints:
The number of nodes in both lists is in the range
[0, 50].-100 <= Node.val <= 100Both
list1andlist2are sorted in non-decreasing order.
✅ Approach & Logic
We use the Two Pointer Technique along with a dummy node to simplify the merging of two sorted linked lists.
Initialize a dummy node to act as the head of the merged list.
Use a
currpointer that always points to the last node in the merged list.Iterate through both
list1andlist2, picking the smaller value node and updating links.After one list ends, simply attach the remaining part of the other list to the merged list.
🧠 Step-by-Step Code Explanation
ListNode dummy = new ListNode(0); // Dummy node to build result
ListNode curr = dummy; // Pointer to build the new list
while(list1 != null && list2 != null) {
if(list1.val < list2.val) {
curr.next = list1;
curr = list1;
list1 = list1.next;
} else {
curr.next = list2;
curr = list2;
list2 = list2.next;
}
}
// Add remaining elements
if(list1 == null) {
curr.next = list2;
} else {
curr.next = list1;
}
return dummy.next;
🎨 Physical Representation
Let’s say:
list1: [1] → [3] → [5]
list2: [2] → [4] → [6]
🔁 Iteration 1:
list1.val = 1,list2.val = 2Pick
1curr.next= list1→ [0] → [1]curr = list1list1 =list1.next
🔁 Iteration 2:
list1.val = 3,list2.val = 2Pick
2curr.next= list2→ [1] → [2]curr = list2list2 =list2.next
🔁 Iteration 3:
list1.val = 3,list2.val = 4Pick
3→ [2] → [3]curr = list1,list1 =list1.next
🔁 Continue...
Eventually:
Merged list: [1] → [2] → [3] → [4] → [5] → [6]
🧠 First, the Concept:
Think of a linked list like a train, where each box is a node, and the connector between them is the .next pointer.
When we say:
✅ curr.next = list1;
We're saying:
“Connect the next box of the current train to the front of list1.”
When we say:
✅ curr = list1;
We're saying:
“Now move the current pointer to the box you just added.”
🎯 Why Do We Need Both?
Let’s say you're building a new train by choosing coaches from two existing trains (list1 and list2).
curr.next= list1:
You attach the next coach of your current train to a coach fromlist1.curr = list1:
Now that you’ve added that coach, you need to move your hand forward to that new coach. Otherwise, the next addition will overwrite the same place!
🔧 Without curr = list1, you'd be stuck!
If you don’t update curr, your pointer will stay on the same node. The next time you try to attach a node, it’ll overwrite the .next again!
📊 Dry Run Example
Input:
list1 = [1, 2, 4]
list2 = [1, 3, 4]
Output:
Merged List: [1, 1, 2, 3, 4, 4]
🔍 Edge Cases Handled
One list is
nulland the other is not → It attaches the remaining non-null list.Both lists are
null→ Returns an empty list (null).Lists with duplicate values → They’re preserved in sorted order.
💡 What I Learned
Using a dummy node simplifies edge cases (like empty lists).
curr.next= list1/list2connects the node.curr = list1/list2moves the pointer to the end of the merged list.Proper pointer movement is key in linked list problems.
✅ Conclusion for Blog (Day 5 - DSA Challenge)
As Day 5 of the 90 Days DSA Challenge comes to a close, I feel a deeper understanding and greater confidence building within me. Today’s problems, ranging from string manipulation to advanced linked list operations, were not just coding exercises—they were logical puzzles that pushed my analytical thinking, attention to edge cases, and pointer manipulation.
Each problem taught me something crucial:
Longest Common Prefix sharpened my skills in string traversal and understanding boundary conditions.
Delete Node in a Linked List was a concise yet clever trick that reminded me how direct manipulation can save space and time.
Remove Nth Node from End pushed me to implement multiple approaches, ensuring robustness and flexibility in problem-solving.
Reverse a Linked List reinforced the importance of clear visual representation when dealing with pointer-based data structures.
Merge Two Sorted Lists highlighted how auxiliary nodes like
dummycan simplify even the trickiest of scenarios.
💡 With each problem, I’m not just solving LeetCode questions—I’m becoming more fluent in the language of logic, learning how to think like a software engineer.
Thank you for joining me on this journey. Let’s keep building momentum together—one problem at a time!
👨💻 — A. Saivaishnav, Final Year CSE
Subscribe to my newsletter
Read articles from Saivaishnav Ambati directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by