The Anatomy of AI Minds: Decoding Neural Networks
 Spheron Network
Spheron NetworkTable of contents
- Understanding the Foundations: Neural Networks and Neurons
- The Problem of Polysemantic Neurons
- The Feature Discovery Breakthrough
- Feature Graphs: The New Frontier
- Beyond Memorization: Evidence of Reasoning
- Planning Ahead: The Autoregressive Paradox
- The Universal Circuit: Multilingual Capabilities and Beyond
- Implications for AI Development and Understanding
- The Path Forward: Challenges and Opportunities
- Conclusion: A New Era of AI Understanding

One of the most persistent challenges has been understanding exactly how large language models (LLMs) like ChatGPT and Claude work. Despite their impressive capabilities, these sophisticated AI systems have largely remained "black boxes"—we know they produce remarkable results, but the precise mechanisms behind their operations have been shrouded in mystery—that is, until now.
A groundbreaking research paper published by Anthropic in early 2025 has begun to lift this veil, offering unprecedented insights into the inner workings of these complex systems. The research doesn't just provide incremental knowledge – it fundamentally reshapes our understanding of how these AI models think, reason, and generate responses. Let's dive deep into this fascinating exploration of what might be called "the anatomy of the AI mind."
Understanding the Foundations: Neural Networks and Neurons
Before we can appreciate the breakthroughs in Anthropic's research, we need to establish foundational knowledge about the structure of modern AI systems.
At their core, today's most advanced AI models are built upon neural networks – computational systems loosely inspired by the human brain. These neural networks consist of interconnected elements called "neurons" (though the technical term is "hidden units"). While the comparison to biological neurons is imperfect and somewhat misleading to neuroscientists, it provides a useful conceptual framework for understanding these systems.
Large language models like ChatGPT, Claude, and their counterparts are essentially massive collections of these neurons working together to perform a seemingly simple task: predicting the next word in a sequence. However, this simplicity is deceptive. Modern frontier models contain hundreds of billions of neurons interacting in extraordinarily complex ways to make these predictions.
The sheer scale and complexity of these interactions have made it exceptionally difficult to understand exactly how these models arrive at their answers. Unlike traditional software, where developers write explicit instructions that the program follows, neural networks develop their internal processes through training on vast datasets. The result is a system that produces impressive outputs but whose internal mechanisms have remained largely opaque.
The Problem of Polysemantic Neurons
Early attempts to understand these models focused on analyzing individual neuron activations – essentially monitoring when specific neurons "fire" in response to particular inputs. The hope was that individual neurons might correspond to specific concepts or topics, making the model's behavior interpretable.
However, researchers quickly encountered a significant obstacle: neurons in these models turned out to be "polysemantic," meaning they would activate in response to multiple, seemingly unrelated topics.
This polysemantic nature made it exceedingly difficult to map individual neurons to specific concepts or to predict a model's behavior based on which neurons were activating. The models remained black boxes, and their internal workings were resistant to straightforward interpretation.
The Feature Discovery Breakthrough
The first major breakthrough in understanding these systems came when Anthropopic researchers discovered that while individual neurons might be polysemantic, specific combinations of neurons were often "monosemantic "—uniquely related to specific concepts or outcomes.
This insight led to the development of the concept of "features" – particular patterns of neuron activation that could be reliably mapped to specific topics or behaviors. Rather than trying to understand the model at the level of individual neurons, researchers could now analyze it in terms of these feature activations.
To facilitate this analysis, Anthropic introduced a methodology called "sparse autoencoders" (SAEs), which helped identify and map these neuron circuits to specific features. This approach transformed what was once an impenetrable black box into something more akin to a map of features explaining the model's knowledge and behavior.
Perhaps even more significantly, researchers discovered they could "steer" a model's behavior by artificially activating or suppressing the neurons associated with particular features. By "clamping" certain features – forcing the associated neurons to activate strongly – they could produce predictable behaviors in the model.
In one striking example, by clamping the feature associated with the Golden Gate Bridge, researchers could cause the model to essentially behave as if it were the bridge itself, producing text from the perspective of the iconic San Francisco landmark.
Feature Graphs: The New Frontier
Building on these earlier discoveries, Anthropic's latest research introduces the concept of "feature graphs," which takes model interpretability to new heights. Rather than trying to map the billions of neuron activations directly to outputs, feature graphs transform these complex neural patterns into more comprehensible representations of concepts and their relationships.
To understand how this works, consider a simple example: When a model is asked, "What is the capital of Texas?" The expected answer is "Austin." In traditional approaches to understanding the model, we would need to analyze billions of neuron activations to understand how the model arrived at this answer—an effectively impossible task.
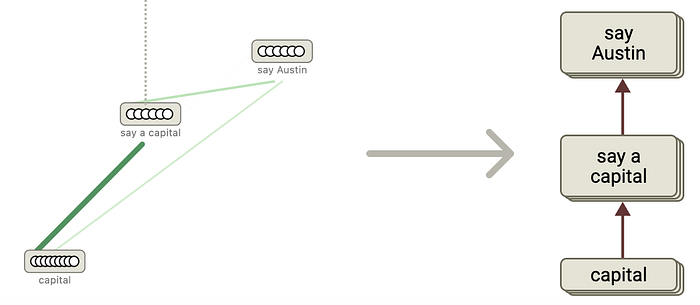
But feature graphs show something remarkable: When the model processes the words "Texas" and "capital," it activates neurons related to these concepts. The "capital" neurons promote a set of neurons responsible for outputting a capital city name. Simultaneously, the "Texas" neurons provide context. These two activation patterns then combine to activate the neurons associated with "Austin," leading the model to produce the correct answer.
This represents a profound shift in our understanding. For the first time, we can trace a clear, interpretable path from input to output through the model's internal processes. LLM outputs are no longer mysterious; they have a mechanistic explanation.
Beyond Memorization: Evidence of Reasoning
At this point, it would be easy to take a cynical stance and argue that these circuits simply represent memorized patterns rather than genuine reasoning. After all, couldn't the model just be retrieving the memorized sequence "Texas capital? Austin" rather than performing any real inference?
What makes Anthropic's findings so significant is that they demonstrate these circuits are actually generalized and adaptable – qualities that suggest something more sophisticated than simple memorization.
For example, if researchers artificially suppress the "Texas" feature while keeping the "capital" feature active, the model will still predict a capital city – just not Texas's capital. The researchers could control which capital the model produced by activating neurons representing different states, regions, or countries, while still utilizing the same basic circuit architecture.
This adaptability strongly suggests that what we're seeing isn't rote memorization but a form of generalized knowledge representation. The model has developed a general circuit for answering questions about capitals and adapts that circuit based on the specific input it receives.
Even more compelling evidence comes from the model's ability to handle multi-step reasoning tasks. When prompted with a question like "The capital of the state containing Dallas is...", the model engages in a multi-hop activation process:
It recognizes the terms "capital" and "state," activating neurons that promote capital city predictions
In parallel, it activates "Texas" after processing "Dallas"
These activations combine – the urge to produce a capital name and the context of Texas – resulting in the prediction of "Austin"
This activation sequence bears a striking resemblance to how a human might reason through the same question, first identifying that Dallas is in Texas, then recalling that Austin is Texas's capital.
Planning Ahead: The Autoregressive Paradox
Perhaps one of the most surprising discoveries in Anthropic's research concerns the ability of these models to "plan ahead" despite their fundamental architectural constraints.
Large language models like GPT-4 and Claude are autoregressive, meaning they generate text one token (roughly one word) at a time, with each prediction based solely on the tokens that came before it. Given this architecture, it seems counterintuitive that such models could plan beyond the immediate next word.
Yet Anthropic's researchers observed exactly this kind of planning behavior in poetry generation tasks. When writing poetry, a particular challenge is ensuring that the final words of verses rhyme with each other. Human poets typically address this by planning the rhyming word at the end of a line first, then constructing the rest of the line to lead naturally to that word.
Remarkably, the neural feature graphs revealed that LLMs employ a similar strategy. As soon as the model processes a token indicating a new line of poetry, it begins activating neurons associated with words that would make both semantic sense and rhyme appropriately – several tokens before those words would actually be predicted.
In other words, the model is planning the outcome of the entire verse before generating a single word of it. This planning ability represents a sophisticated form of reasoning that goes well beyond simple pattern matching or memorization.
The Universal Circuit: Multilingual Capabilities and Beyond
The research uncovered additional fascinating capabilities through these feature graphs. For instance, models demonstrate "multilingual circuits" – they understand user requests in a language-agnostic form, using the same basic circuitry to answer while adapting interchangeably to the input language.
Similarly, for mathematical operations like addition, models appear to use memorized results for simple calculations but employ elaborate circuits for more complex additions, producing accurate results through a process that resembles step-by-step calculation rather than mere retrieval.
The research even documents complex medical diagnosis circuits, where models analyze reported symptoms, use them to promote follow-up questions, and elaborate on correct diagnoses through multi-step reasoning processes.
Implications for AI Development and Understanding
The significance of Anthropic's findings extends far beyond academic interest. These discoveries have profound implications for how we develop, deploy, and interact with AI systems.
First, the evidence of generalizable reasoning circuits provides a strong counter to the narrative that large language models are merely "stochastic parrots" regurgitating memorized patterns from their training data. While memorization undoubtedly plays a significant role in these systems' capabilities, the research clearly demonstrates behaviors that transcend simple memorization:
Generalizability: The circuits identified are general and adaptable, used by models to answer similar yet distinct questions. Rather than developing unique circuits for every possible prompt, models abstract key patterns and apply them across different contexts.
Modularity: Models can combine different, simpler circuits to develop more complex ones, tackling more challenging questions through composition of basic reasoning steps.
Interventability: Circuits can be manipulated and adapted, making models more predictable and steerable. This has enormous implications for AI alignment and safety, potentially allowing developers to block certain features to prevent undesired behaviors.
Planning capacity: Despite their autoregressive architecture, models demonstrate the ability to plan ahead for future tokens, altering current predictions to enable specific desired outcomes later in the sequence.
These capabilities suggest that while current language models may not possess human-level reasoning, they are engaged in behaviors that certainly transcend mere pattern matching – behaviors that could reasonably be characterized as a primitive form of reasoning.
The Path Forward: Challenges and Opportunities
Despite these exciting discoveries, important questions remain about the future development of AI reasoning capabilities. The current capabilities emerged after training on trillions of data points, yet remain relatively primitive compared to human reasoning. This raises concerns about the viability of improving these capabilities within current paradigms.
Will models ever develop truly human-level reasoning capabilities? Some experts suggest that we may need fundamental algorithmic breakthroughs that improve data efficiency, allowing models to learn more from less data. Without such breakthroughs, there's a risk that these models could plateau in their reasoning abilities.
On the other hand, the new understanding provided by feature graphs opens exciting possibilities for more controlled and targeted development. By understanding exactly how models reason internally, researchers might be able to design training methodologies that specifically enhance these reasoning circuits, rather than relying on the current approach of massive training on diverse data and hoping for emergent capabilities.
Furthermore, the ability to intervene in specific features opens new possibilities for AI alignment – ensuring models behave in accordance with human values and intentions. Rather than treating alignment as a black-box problem, developers might be able to directly manipulate the specific circuits responsible for potentially problematic behaviors.
Conclusion: A New Era of AI Understanding
Anthropic's research represents a watershed moment in our understanding of artificial intelligence. For the first time, we have concrete, mechanistic evidence of how large language models process information and generate responses. We can trace the activation of specific features through the model, watching as it combines concepts, makes inferences, and plans.
While these models still rely heavily on memorization and pattern recognition, the research conclusively demonstrates that there's more to their capabilities than these simple mechanisms. Identifying generalizable, modular reasoning circuits provides compelling evidence that these systems are engaging in processes that, while not identical to human reasoning, certainly transcend simple retrieval.
As we continue to develop more powerful AI systems, this deeper understanding will be crucial for addressing concerns about safety, alignment, and the ultimate capabilities of these technologies. Rather than flying blind with increasingly powerful black boxes, we now have tools to peer inside and understand the anatomy of the AI mind.
The implications of this research extend beyond technical understanding – they touch on fundamental questions about the nature of intelligence itself. If seemingly simple neural networks can develop primitive reasoning capabilities through exposure to patterns in data, what does this tell us about the nature of human reasoning? Are there deeper information processing principles that underlie biological and artificial intelligence?
These questions remain open, but Anthropic's research has given us powerful new exploration tools. As we continue to map the anatomy of artificial minds, we may gain unexpected insights into our own.
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute