GenAi basics - How it actually works
 MagOne
MagOneTable of contents
- Part One - Mechanism of LLM
- Part Two - How mechanism works
- 1. Vocab Size: The Word Bank
- 2. What are Vectors?
- 3. Semantic Meaning: What's the Point?
- 4. Softmax: Making Smart Choices
- 5. Multi-Head Attention: Seeing the Whole Picture
- 6. Temperature: Adding Spice to AI's Creativity
- Why is Temperature Important?
- How Does Temperature Work?
- Examples of Temperature in Action
- Fun Fact: Goldilocks Zone
- 7. Knowledge Cutoff: Staying Up-to-Date
Hey Guys, MagOne here!
Today, we're diving deep into the heart of modern NLP (Natural Language Processing): the Transformer architecture. This is article focusing exclusively on the transformer. This is also inspired by Google's "Attention is All You Need", so let's start!
Part One - Mechanism of LLM
1. Transformer
Imagine you have a sentence, like
"Humpty Dumpty sat on the wall."
A Transformer is like a super-smart machine that reads the whole sentence at once to understand what's happening.
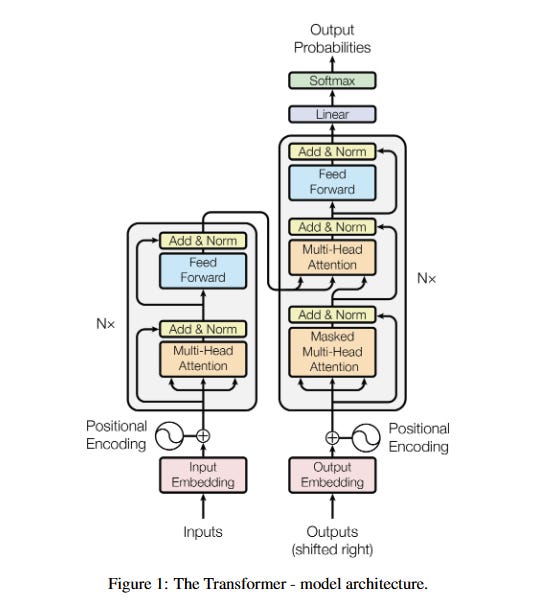
A Transformer is a special brain for computers that helps them understand language. It's used to do things like translate languages, answer questions, and even write stories
It help the computer focus on the important words in a sentence, just like how you focus on the important parts of a story
eg: When you read a book, you don't just read one word at a time, right? You read the whole sentence to understand what's going on. Transformers do the same thing.
How Does It Work?
Reading the Words: First, the Transformer looks at each word in the sentence.
eg: It sees "Humpty," "Dumpty," "sat," "on," "the," and "wall."Understanding Relationships: Then, it figures out how each word is related to the other words. eg: it knows that "Humpty Dumpty" is one thing, and he is doing the → "sitting."
eg: It's like when you're putting together a puzzle. You know that certain pieces fit together to make a picture. The Transformer knows which words fit together to make sense.Self-Attention: This is like the Transformer asking itself, "Which words are most important to understand this sentence?" It pays more attention to the important words.
eg: If someone asks you what happened to Humpty Dumpty, you'd focus on the fact that he "sat on the wall" because that's important information.
So, in the sentence "Humpty Dumpty sat on the wall," the Transformer understands that Humpty Dumpty is a character who is sitting, and the wall is where he is sitting.
Why Are Transformers So Cool?
They understand the whole sentence: Unlike older methods, Transformers don't just read one word at a time. They see everything at once.
They find the important words: They know which words are key to understanding the sentence.
They're super smart: Because of all this, they're great at understanding and using language.
eg: Think of it like having a super-smart friend who always understands what you mean, even if you don't say it perfectly!
So, Transformers are like super-smart readers that help computers understand what we're saying or writing!
How Transformers REALLY Work (Even More Detail)
Okay, so if you want to know how Transformers do all that, keep going!
2. Embeddings: Turning Words into Numbers
First, each word is turned into a list of numbers called an "embedding."
Think of it like giving each word a secret code. This helps the computer understand the word's meaning.
For example, using something like OpenAI's tiktoken library, 'Humpty' might get represented as the list of numbers
[123][456][789], and 'Dumpty' as[124][457][790]. Words that appear in similar contexts will tend to have closer, more similar numerical codes. (This is just an example how Embedding works)
Here is an example of how words are converted in tokens using python and tiktokens library of OpenAi
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
words = ["dog", "ice cream", "school"]
for word in words: tokens = encoding.encode(word) print(f"The word '{word}' becomes tokens: {tokens}")
Code Explanation
Import tiktoken: This line imports the tiktoken library, which is essential for using OpenAI's tokenization tools.
Load Encoding: This specifies that we are using the "cl100k_base" encoding, which is designed to work well with OpenAI models like
gpt-4andgpt-3.5-turbo.Define Words: A list of words is created which you want to convert into tokens.
Loop and Encode: The code iterates through each word in the
wordslist. Inside the loop:encoding.encode(word): This encodes the current word into tokens using the specified encoding.print(...): This prints the original word and the corresponding tokens.
The word 'dog' becomes tokens: [1405]
The word 'ice cream' becomes tokens: [7460, 2753]
The word 'school' becomes tokens: [1477]
Output Explanation
Dog: The word "dog" is converted into the token
1405.Ice Cream: The word "ice cream" is converted into two tokens:
7460and2753. This is because "ice cream" is treated as two separate words by the tokenizer.School: The word "school" is converted into the token
1477.
3. Positional Encoding
Since Transformers read all the words at once, they need to know the order of the words.
Positional encoding adds another set of numbers to the embeddings to tell the Transformer where each word is in the sentence.
Think of it like telling the Transformer, "This is the first word, this is the second word," and so on.
4. Attention
The Transformer uses "attention" to figure out which words are most important.
It asks three questions about each word:
"What am I looking for?" (Query) - What does this word want to find in the other words?
"What do I know?" (Key) - What information does this word have to offer?
"What info do I have?" (Value) - What is the actual content of this word?
Then, it compares these questions for all the words. If two words are related, they get a higher score.
5. Self-Attention: the Math part
- The Transformer uses this formula to figure out how much attention to pay to each word:
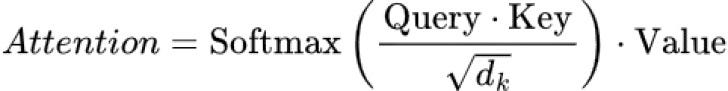
Query and Key are multiplied to see how related the words are.
d_k is a number (the dimension of the Key) used to make sure the numbers don't get too big.
Softmax turns the scores into percentages that add up to 100%. (we will see more about softmax later)
Finally, the Value is multiplied by these percentages to get the weighted values.
6. Multi-Head Attention
To understand the sentence in different ways, the Transformer uses "multi-head attention."
This means it does the attention thing several times, each time focusing on different aspects of the words.
It's like looking at the sentence from different angles!
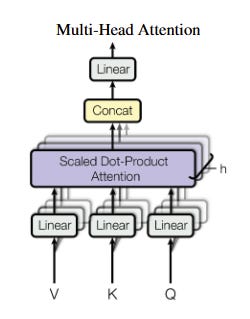
Putting It All Together (Layers):
The Transformer does all of this in multiple layers.
Each layer takes the output of the previous layer and makes it better.
This helps the Transformer understand even more complex sentences.
In conclusion of Transformer
A Transformer is like a super-smart detective that uses math and clever tricks to understand what we're saying, It turns words into numbers, figures out which words are important, and puts everything together to get the meaning. This is how it can translate languages, answer questions, and write stories or long essays.
Part Two - How mechanism works
1. Vocab Size: The Word Bank
Now we’ll be exploring a key aspect of how AI understands language: vocabulary size. This is like the number of words an AI knows, and it plays a huge role in its abilities. Let's dive in!
What is Vocabulary Size?
Vocabulary size refers to the total number of unique tokens that a model recognizes. These tokens can be words, parts of words, or even individual characters. Think of it as the size of the AI's dictionary.
Why is Vocabulary Size Important?
The vocabulary size affects an AI's ability to:
Understand Language: A larger vocabulary allows the AI to recognize and understand a wider range of words and expressions.
Generate Text: It can generate more diverse and nuanced text.
Handle Rare Words: A larger vocabulary helps handle rare or specialized words.
Factors Affecting Vocabulary Size
Training Data: The more data used to train the model, the larger the vocabulary can become.
Tokenization Method: The tokenization method affects the size of the vocabulary. Subword tokenization can create a smaller vocabulary while still handling a large number of words.
Model Size: Larger models can handle larger vocabularies.
Examples of Vocabulary Size
Small Vocabulary: A small vocabulary might contain only the most common words in a language. This is sufficient for basic tasks like simple text classification.
Large Vocabulary: A large vocabulary can contain millions of words, including rare words, proper nouns, and technical terms. This is necessary for complex tasks like language translation and question answering.
Fun Fact: The Bigger, The Better?
While a larger vocabulary is generally better, it also comes with challenges. Larger vocabularies require more memory and processing power. There's a trade-off between vocabulary size and model efficiency.
Conclusion
Vocabulary size is a critical factor in determining an AI's ability to understand and generate human language. A larger vocabulary allows the AI to handle a wider range of linguistic tasks, but it also requires more resources. By understanding the concept of vocabulary size, we can better appreciate the complexities of AI language models.
2. What are Vectors?
Imagine you have a bunch of LEGOs & you’re making some MOC with that. You can describe each MOC by giving it some numbers:
Cars: Speed (8), Size (3), Color (Red)
Bat Mobile: Hair Length (10), Dress Color (Pink), Cuteness (9)
Avengers Tower: Number (50), Colorfulness (7), Size (2)
See? Each toy gets a set of numbers that tells you something about it. Vectors are like that, but for words!
How Do Vectors Work?
Computers can't understand words like you and me. So, we give each word a list of numbers called a vector. These numbers represent different things about the word, like its meaning and how it relates to other words.
- Example: Let's say we have the word "Tony". If we use a special tool called tiktoken, which is like a secret decoder for computers, it turns "Tony" into the number 9617. Think of it like this: tiktoken has seen tons of words and figured out that "Tony" often shows up in certain places or with certain other words. So, 9617 is a quick way for the computer to remember all that without having to spell out "Tony" every time!
Why are Vectors Important?
Vectors help computers do all sorts of cool things:
Understanding Sentences: By looking at the vectors of each word in a sentence, a computer can understand what the sentence is about.
Finding Similar Words: Words with similar vectors are likely to have similar meanings. So, a computer can find words that are like "Happy," such as "Joyful" or "Excited."
Translating Languages: Vectors can help computers translate languages by finding words in different languages that have similar vectors.
Here's How the Code Works for Vectors with Tiktoken
import tiktoken
import numpy as np
encoding = tiktoken.get_encoding("cl100k_base")
words = ["dog", "ice cream", "school"]
for word in words:
tokens = encoding.encode(word)
print(f"The word '{word}' becomes tokens: {tokens}")
# Create a simple vector representation (not true embeddings)
vector = np.zeros(encoding.n_vocab) # Vector of zeros
for token in tokens:
vector[token] = 1 # Set element to 1 if token is present
print(f"Simple vector representation: {vector}")
print(f"Shape of vector: {vector.shape}")
Code Explanation:
Import Libraries: Imports
tiktokenfor tokenizing andnumpyfor creating vectors.Load Encoding: Loads the
cl100k_baseencoding, which is compatible with OpenAI models.Define Words: Creates a list of sample words.
Loop Through Words: Iterates through each word:
Tokenize: Encodes the word into tokens using
encoding.encode(word).Print Tokens: Displays the tokens.
Create Zero Vector: Initializes a NumPy array (vector) filled with zeros. The length of the vector is equal to the vocabulary size of the tokenizer (
encoding.n_vocab).Set Vector Elements: For each token in the list of tokens, it sets the corresponding element in the vector to 1. This creates a simple one-hot vector representation (not a true embedding, but an illustration).
Print Vector: Outputs the vector representation.
Print Vector Shape: Outputs the dimensions of the vector (which is the vocabulary size).
Sample Output:
The word 'dog' becomes tokens: [1405]
Simple vector representation: [0. 0. 0. ... 0. 0. 0.]
Shape of vector: (100257,)
The word 'ice cream' becomes tokens: [7460, 2753]
Simple vector representation: [0. 0. 0. ... 0. 0. 0.]
Shape of vector: (100257,)
The word 'school' becomes tokens: [1477]
Simple vector representation: [0. 0. 0. ... 0. 0. 0.]
Shape of vector: (100257,)
Output Explanation:
Tokens: The tokens are the same as in the previous example.
Vector Representation: The output shows a vector (NumPy array) where most elements are 0, except for the elements corresponding to the tokens, which are set to 1.
Vector Shape: The shape of the vector is
(100257,), which means it's a 1D array with 100,257 elements. This corresponds to the vocabulary size of the tokenizer.
Keep in mind that this is a simplified example and doesn't create true word embeddings. Real-world embeddings (like those used in advanced NLP models) are much more complex and capture more nuanced relationships between words. However, it can help illustrate the concept of converting words into numerical vectors using tokenization.
In Conclusion of Vectors
Vectors are a super important part of how computers understand language. They're like secret codes that unlock the meaning of words! So, next time you hear about vectors, remember they're just friendly numbers helping computers make sense of the world. Keep exploring, and you'll be a vector expert in no time.
3. Semantic Meaning: What's the Point?
Semantic meaning is all about understanding what words really mean. It's not just about recognizing the words themselves, but about grasping the ideas and relationships behind them. It's like understanding the point of what someone is saying.
Why Is It Important?
Think about it: computers can easily read words on a page. But to truly "get" what's being said, they need to understand the meaning behind those words. This allows them to:
Distinguish Similar Words: Understand the subtle differences between "happy" and "joyful" or "big" and "huge."
Understand Context: Figure out that "bank" can mean a place to keep money or the side of a river, depending on the sentence.
Answer Questions: If a computer understands semantic meaning, it can answer questions about a text, not just repeat words from it.
Examples of Semantic Meaning
Let's look at some examples:
"The dog is running in the park." A computer that understands semantic meaning knows that a "dog" is an animal, "running" is an action, and "park" is a place. It understands the relationship between these concepts.
"I'm feeling blue." Here, "blue" doesn't mean the color. A computer with semantic understanding knows it means "sad."
How Do Computers Learn Semantic Meaning?
Computers learn semantic meaning by:
Reading Lots of Text: They analyze huge amounts of text to see how words are used in different situations.
Finding Relationships: They identify connections between words and concepts. For example, they might learn that "cat" is related to "animal," "pet," and "meow."
Using Vectors (Again!): They create more sophisticated vectors that capture the subtle meanings of words.
In Conclusion of Semantic Meaning
Semantic meaning is where the real magic happens in NLP. It's what allows computers to go beyond just processing words to truly understanding and interacting with human language. So, the next time you're chatting with an AI, remember that it's all thanks to the power of semantic meaning.
4. Softmax: Making Smart Choices
Imagine you’ve got a table full of yummy treats: pizza, ice cream, and cookies. You need to choose your favorite, but you also want to rank how much you like each treat. Softmax is like the brain of an AI model that decides which option to pick, while also giving a ranking of how likely each option is.
In simpler terms, Softmax is a mathematical function that converts a list of numbers (scores) into probabilities. These probabilities tell the AI how likely each option is the right answer, and they always add up to 1. Cool, right?
Why is Softmax Important?
Softmax is super important because it helps models make smart choices. Here's what it does:
Turns scores into probabilities: It takes raw scores (numbers) generated by the model and turns them into probabilities (between 0 and 1).
Picks the best option: The option with the highest probability is picked as the answer.
Adds fairness: It ensures all probabilities add up to 1, so the model knows how confident it is about its decision.
How Does Softmax Work?
Let’s break it down into three simple steps:
Raw Scores: Imagine a model has to choose the next word in a sentence. It generates scores for possible words like:
"happy": 2.0
"excited": 3.0
"sad": 0.5
Exponentiation: Softmax raises each score to the power of e (Euler’s number, ~2.718). This makes bigger scores grow faster than smaller ones:
"happy": e^2.0 ≈ 7.39
"excited": e^3.0 ≈ 20.09
"sad": e^0.5 ≈ 1.65
Normalization: Finally, Softmax divides each exponentiated score by the sum of all scores, turning them into probabilities:
"happy": 7.39 / (7.39 + 20.09 + 1.65) ≈ 0.24
"excited": 20.09 / (7.39 + 20.09 + 1.65) ≈ 0.65
"sad": 1.65 / (7.39 + 20.09 + 1.65) ≈ 0.05
The probabilities are:
"happy": 24%
"excited": 65%
"sad": 5%
The model picks "excited" because it has the highest probability.
Where is Softmax Used?
Softmax is widely used in machine learning, especially in NLP tasks like:
Text Prediction: Picking the next word in a sentence.
Classification: Choosing the right category for an input (e.g., is this text about sports or music?).
Attention Mechanisms: Helping models focus on the most important words in a sentence.
Fun Fact: Why Softmax is Special?
Softmax doesn’t just pick one option—it weights all the options based on their probabilities. This means even if "excited" is the best choice, the model still considers "happy" and "sad for context. It’s like keeping all options in mind while making the decision.
In Conclusion of Softmax
Softmax is the hidden genius behind a lot of AI magic. It takes raw numbers, turns them into probabilities, and helps machines make smart, confident choices. So, the next time you’re chatting with an AI or using a language tool, remember the role Softmax plays in making it all work.
5. Multi-Head Attention: Seeing the Whole Picture
What is Multi-Head Attention?
Remember how regular attention helps a model focus on the most important words in a sentence? Well, Multi-Head Attention is like having multiple attention mechanisms working together. It allows the model to look at the sentence from different angles, capturing different relationships and nuances.
Why is Multi-Head Attention Important?
Multi-Head Attention is super powerful because it helps models understand sentences more completely. It does this by:
Capturing Different Relationships: Each "head" focuses on a different aspect of the sentence, like grammar, meaning, or context.
Improving Accuracy: By considering multiple perspectives, the model makes more accurate predictions.
Handling Complexity: It allows the model to handle complex sentences with lots of different connections between words.
How Does Multi-Head Attention Work?
Let’s break it down step by step:
Multiple Heads: Instead of just one attention mechanism, we have several "heads" working in parallel. Each head has its own set of parameters and learns to focus on different things.
Splitting Input: The input sentence is split and fed into each head.
Attention Mechanism: Each head performs its own attention calculation, figuring out which words are most important to each other.
Combining Outputs: The outputs from all the heads are combined to create a final representation of the sentence.
Example: Understanding "The cat sat on the mat"
Imagine we have two attention heads:
Head 1 (Grammar Head): Focuses on the grammatical structure of the sentence, understanding that "cat" is the subject and "sat" is the verb.
Head 2 (Context Head): Focuses on the meaning of the sentence, understanding that "cat" is an animal and "mat" is a place.
By combining the outputs from both heads, the model gains a more complete understanding of the sentence.
Where is Multi-Head Attention Used?
Multi-Head Attention is a key component of Transformer models and is used in a wide range of NLP tasks, including:
Language Translation: Accurately translating sentences from one language to another.
Text Summarization: Creating concise summaries of long articles.
Question Answering: Understanding questions and providing accurate answers.
Fun Fact: More Heads, More Power!
The more attention heads a model has, the more complex relationships it can capture. Some models have dozens of heads, allowing them to understand sentences in incredible detail!
In Conclusion of Multi-Head Attention
Multi-Head Attention is like having a team of super-smart experts, each looking at a sentence from a different angle. By combining their insights, the model gains a deeper and more accurate understanding of the language. So, next time you're using a language tool, remember the power of Multi-Head Attention.
6. Temperature: Adding Spice to AI's Creativity
In the world of AI language models, "temperature" is a parameter that controls the randomness of the model's output. It determines how much risk the model takes when generating text. It’s like a seasoning you add to a dish:
Low Temperature (e.g., 0.2): The model sticks to the most probable and common words. The output is safer, more predictable, and often more boring.
High Temperature (e.g., 1.0): The model takes more chances, using less common and more creative words. The output is riskier, more surprising, and potentially more nonsensical.
Why is Temperature Important?
Temperature is important because it allows us to fine-tune the behavior of AI models for different tasks:
Consistency: For tasks needing reliable, accurate answers (like factual questions), a low temperature is preferred.
Creativity: For tasks requiring creativity, storytelling, or brainstorming, a higher temperature is better.
Avoiding Repetition: Adjusting temperature can help prevent the model from getting stuck in repetitive loops.
How Does Temperature Work?
Remember Softmax? Temperature adjusts the probabilities that Softmax uses to make its decisions. Here's the breakdown:
Model Generates Scores: The model produces scores for each possible next word.
Adjusting Scores: Before Softmax, we divide these scores by the temperature.
Low Temperature: Dividing by a small number makes the high scores even higher and the low scores even lower. This encourages the model to pick the most probable word.
High Temperature: Dividing by a larger number makes the scores more uniform. This gives less probable words a higher chance of being selected.
Softmax Picks a Word: Softmax converts these adjusted scores into probabilities, and the model chooses the next word based on these probabilities.
Examples of Temperature in Action
Writing Code:
Low Temperature: Generates clean, functional code, sticking to established patterns.
High Temperature: Might produce unconventional or buggy code, but could also come up with a novel solution.
Storytelling:
Low Temperature: Tells a straightforward story, following familiar tropes.
High Temperature: Creates a wild and unpredictable story, full of surprises.
Chatting:
Low Temperature: Provides sensible, informative answers.
High Temperature: Engages in imaginative and whimsical conversations.
Fun Fact: Goldilocks Zone
Just like Goldilocks, finding the right temperature is crucial. Too low, and the output is bland. Too high, and it's chaotic. The ideal temperature depends on the specific task and desired outcome.
In Conclusion of Temprature
Temperature is a simple yet powerful parameter that allows us to control the creativity and predictability of AI. By adjusting the temperature, we can make AI models adapt to various tasks, from generating accurate code to crafting imaginative stories.
7. Knowledge Cutoff: Staying Up-to-Date
The knowledge cutoff refers to the point in time after which an AI model has not been trained on any new information. AI models learn from massive amounts of data, but this data isn't constantly updated. So, every AI has a "last seen" date, and anything that happened after that date is a mystery to it.
Why is Knowledge Cutoff Important?
Knowing the knowledge cutoff helps us understand the limitations of an AI:
Outdated Information: If you ask an AI about a recent event, and it happened after its cutoff date, it won't know the answer.
Historical Context: It's important to consider the cutoff when evaluating the AI's responses. What was true before the cutoff might not be true today.
Reliability: Knowing the cutoff helps us gauge the reliability of the AI's information. If you need up-to-the-minute facts, an AI with an old cutoff might not be the best source.
Examples of Knowledge Cutoff
Sports Scores: If an AI's cutoff date is January 2023, it won't know who won the Super Bowl in 2024.
Current Events: It won't be able to discuss news that happened after its cutoff.
Technology Trends: It might not be aware of the latest advancements in AI or other fields.
How to Find an AI's Knowledge Cutoff
Check the Documentation: Many AI providers state the knowledge cutoff in their documentation.
Ask Directly: You can ask the AI, "What is your knowledge cutoff date?" However, be aware that the AI's response might not always be accurate.
Test Its Knowledge: Ask the AI about recent events and see if it knows the answers.
Fun Fact: The Ever-Evolving AI
AI models are constantly being updated with new data. This means their knowledge cutoffs are always changing. The goal is to create AIs that have access to the most up-to-date information possible, often by connecting them to the internet and other real-time data sources.
In Conclusion of Knowledge Cut-off
Knowledge cutoff is a crucial concept for understanding the limitations of AI. By knowing when an AI's information stops being current, we can use it more effectively and avoid relying on outdated data.
Subscribe to my newsletter
Read articles from MagOne directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by