Decoding AI Jargons with Chai
 Nitesh Singh
Nitesh Singh
A lot of jargon comes up while reading about AI, like tokenization, embedding, corpus, encoder, decoder, and many more. At the time, we also had to make our journey through other jargon. Here are some frequent jargon terms with short and simple meanings in AI, so you don't need to scratch your head while reading about AI next time.
Corpus
A large collection of structured language training data (text, speech, image, video). It is used as a dataset to train algorithms and develop models.

Vector
A data structure to represent a collection of numerical values in an ordered manner. The machine can’t directly understand human language; converting it to a vector helps it understand and implement mathematical models.

Vocal Size
The number of vocal samples in a dataset or the different types of words in the dataset. The bigger the vocal size, the better the model.

Knowledge Cutoff
The point in time after which the AI model was fed with data. If you ask AI questions about things it lacks information, it will give trash results.

Tokenization
Breaking a text into smaller units called tokens. It is essential as it converts the unstructured text format into a format that a computer can understand and process.

Semantic Meaning
Understanding and interpreting the contextual meaning of the data. For example, a bank can mean a financial institution or the side of a river.

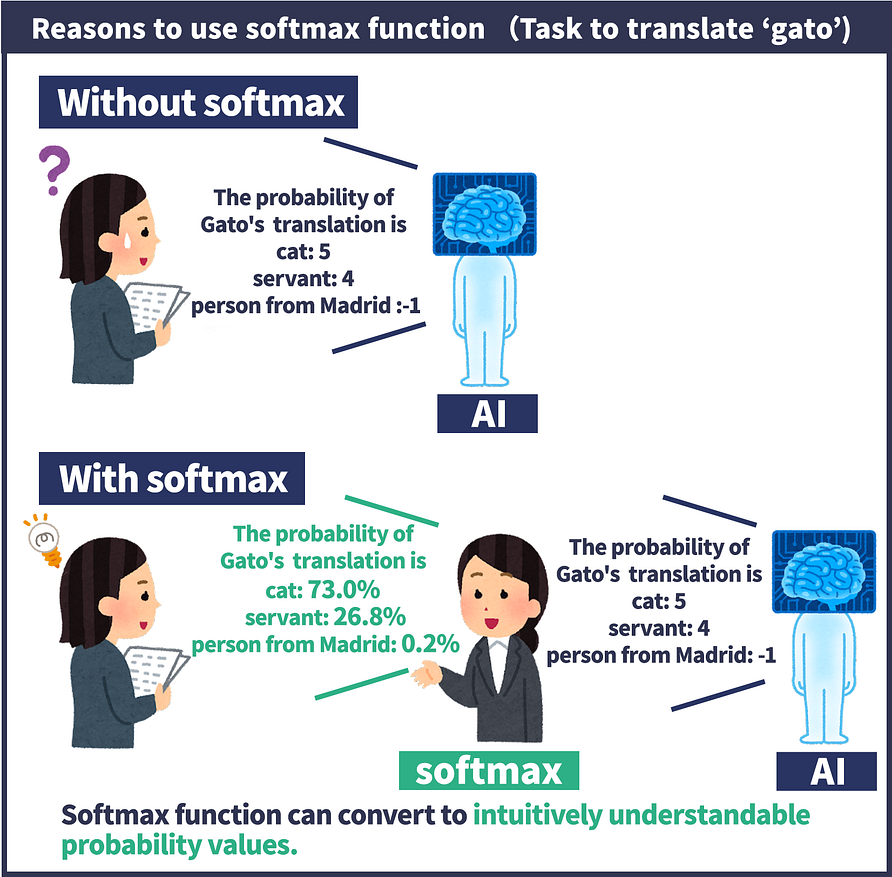
Sofmax
Softmax is a function that converts the input values in the range [0, 1] that sum to 1. Softmax is mainly used in the final layer, where the output value produced by the AI is finally converted.
Encoder and Decoder
The encoder converts the input sequence into a vector, while the decoder converts the hidden vector into an output sequence.

Embedding
Converting the input sequence into a vector representation that captures its inherent properties and relationships. Seems similar to encoding, but encoding does not focus on semantics and relations. Encoding may lead to sparse representation and dense representation in embedding. Encoding works well with small datasets, and embedding helps with larger ones.

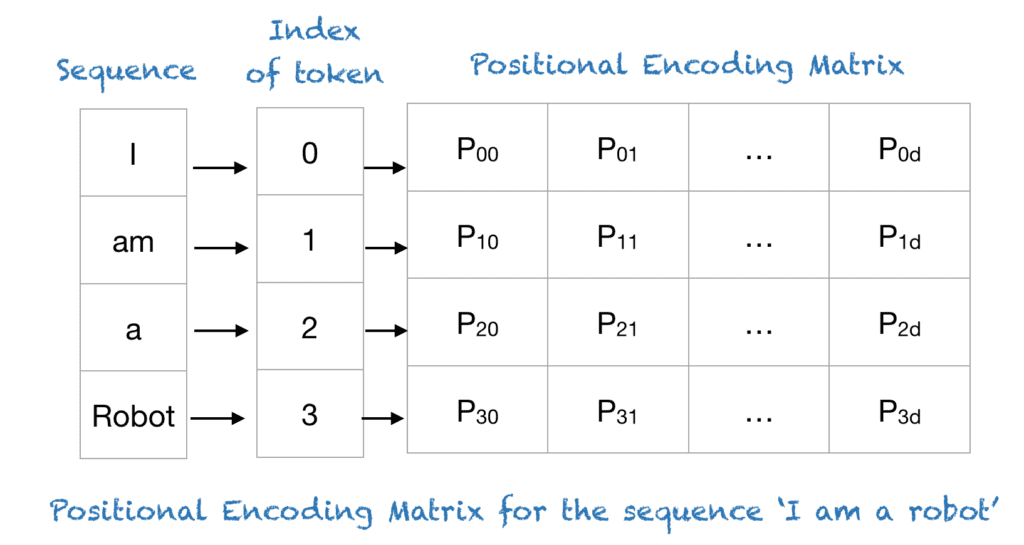
Positional Encoding
Used to assign relative positioning to each token in a sequence. It helps the models to understand the sequence of words in an input, which is essential for language interpretation and generation.
Self, Cross, and Multihead Attention
Self-attention focuses on relationships between words within a single sequence, while cross-attention focuses on the relationships between words in different sequences. Multihead attention is an extension of self-attention, performing multiple self-attention operations in parallel, focusing on various aspects of the relationships.

Transformer
A transformer is a type of neural network architecture that excels at processing sequential data. It has four main parts: tokenization, embedding, positional encoding, transformer blocks(containing attention and feedforward component), and softmax.
Subscribe to my newsletter
Read articles from Nitesh Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by