Decoding AI Jargons In A Simpler Way
 Krish Kalaria
Krish Kalaria
At first glance, AI seems magical in how it generates text for our queries and responds so well. It has become an integral part of our lives, and understanding how AI works makes us feel more in control and helps us use AI tools more effectively. So, let's get started.
Basically, GPT - Generative Pre-Trained Transformers is where the magic happens. Transformers are a type of neural network architecture that has revolutionized how we understand and generate language. Attention is All You Need is an excellent paper by Google that explores the world of transformers, and I recommend everyone read it. It was initially designed for Google Translate to use the transformer, but this same technology makes AI feel magical—though it won't seem so mysterious after reading this article.
Let's first understand what happens when we write a query to the AI. It breaks the query into tokens. Tokens are simply the representation of the query in the form of numbers. Every AI model has its own process of tokenization. Below is an example of how tokenization works with a simple example:
import tiktoken
encoder = tiktoken.encoding_for_model('gpt-4o')
print("Vocab Size", encoder.n_vocab) # 2,00,019 (200K)
text = "The cat sat on the mat"
tokens = encoder.encode(text)
print("Tokens", tokens) # Tokens [976, 9059, 10139, 402, 290, 2450]
my_tokens = [976, 9059, 10139, 402, 290, 2450]
decoded = encoder.decode([976, 9059, 10139, 402, 290, 2450])
print("Decoded", decoded)
But how does it work internally? The answer lies in the vocabulary size. Vocabulary size is the number of words you want your tokenizer to recognize. For example, the vocabulary size for the OpenAI GPT-4o model is 200,000.
But why do we need these numbers? Let's move on to the next step and understand the significance of the numbers we get from tokenization.
Vector Embeddings - These are numerical representations of data, such as words, images, or audio, that capture their semantic relationships and meaning. Essentially, they help us understand the context or meaning behind your query. Semantic relationships involve studying and understanding the meaning conveyed by words, phrases, and sentences. Below is an example of vector embeddings:

Vector embeddings are created in a 3D space, but for simplicity, let's consider them in a 2D plane. After tokenization, if "India" is related to "USA" and "USA" is related to "burger," it implies that "India" is also related to "burger." This is because they share a similar path or distance, providing a semantic meaning or relationship within the sentence.

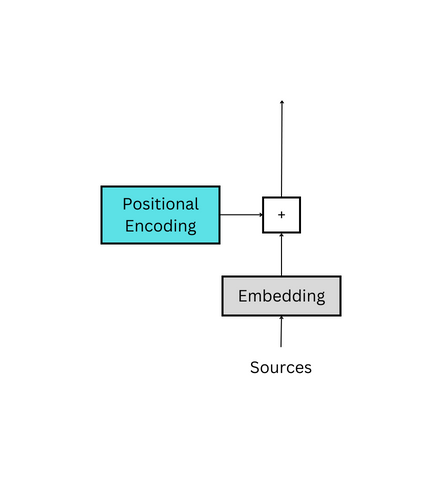
So, after finding the semantic meaning, a question arises: what if, for example, "mat sat on cat" and "cat sat on mat" both have the same semantic meaning but completely different literal meanings? How does it differentiate between them?
Positional Encding is the solution
Positional encoding is used to provide a relative position for each token or word in a sequence. When reading a sentence, each word is dependent on the words around it. For instance, some words have different meanings in different contexts, so a model should be able to understand these variations and the words that each relies on for context. An example is the word “trunk.” In one instance, it could be used to refer to an elephant using its trunk to drink water. In another, it could refer to a tree’s trunk being struck by lighting.
Let's move on to the next important topic - Self-Attention
Self-attention is a machine learning technique that helps models understand the relationships between words in a sequence. For example, in the sentence “Extreme brightness of the sun hurts the eyes,” self-attention determines how each word relates to all the other words in the sequence.
There is also something related to self-attention called Multi-Head Attention. The difference between self-attention and multi-head attention is: Self-Attention is best for simpler tasks, shorter sequences, or environments with limited resources, like analyzing the sentiment of short reviews. Multi-Head Attention is ideal for complex tasks with long sequences or multi-dimensional data, such as translating languages or classifying images.
As I mentioned before, GPT is simply a tool to predict the most likely next outcome, right? So how does it do that?
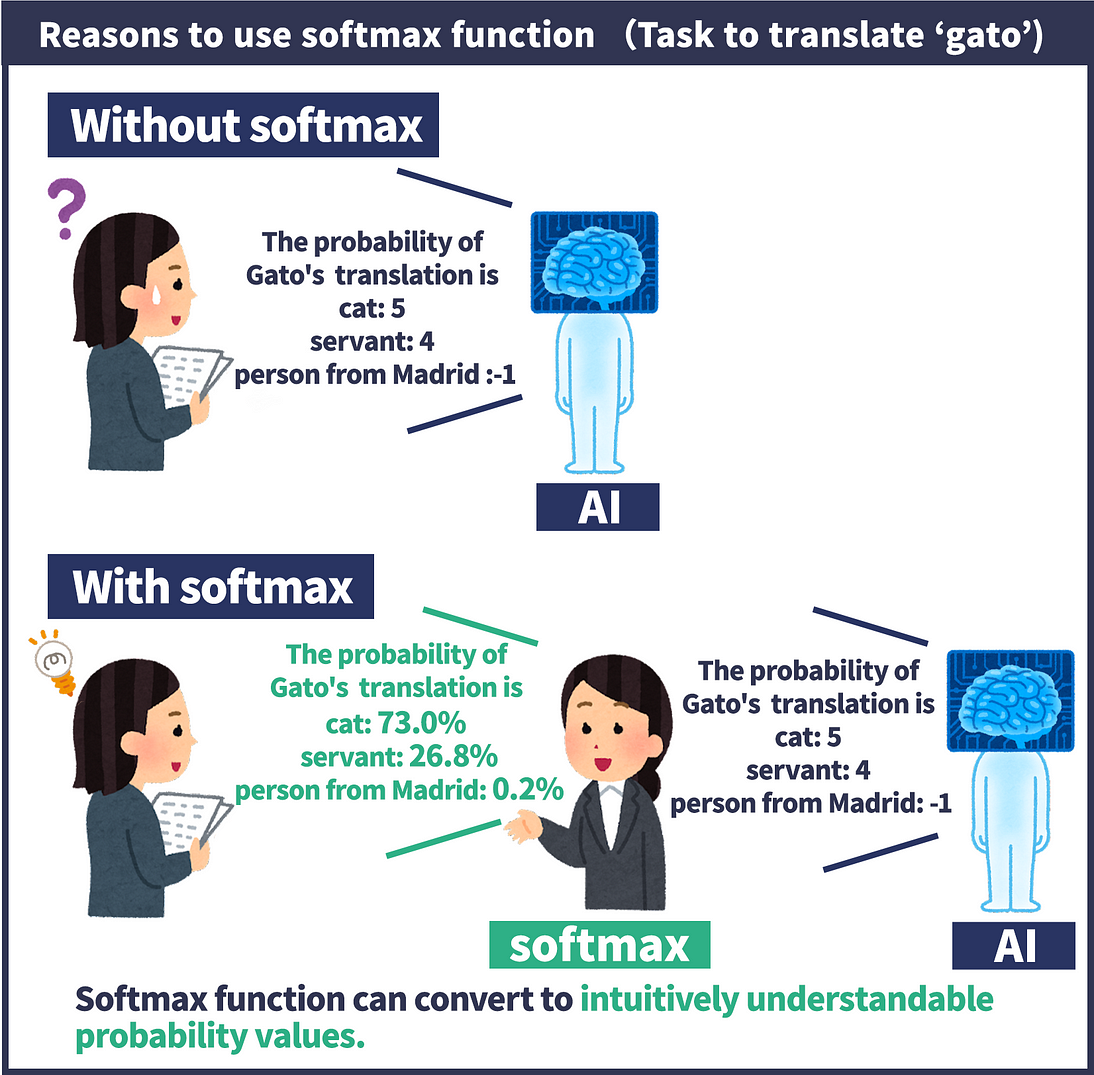
Softmax is the key behind this.
Think of it like this:
You have a group of friends, and you're trying to guess which one likes a particular song the most.
You ask each friend, and they give you a "score" indicating how much they like the song.
The softmax function takes those scores and turns them into percentages, showing the probability of each friend being the biggest fan.
The knowledge cutoff is the point up to which the AI's information is based. For example, Gemini 2.5 Pro has a knowledge cutoff of January 2025, meaning it will not know or have any idea about events after that date.
Temperature controls how random the output prediction is. The higher the temperature, the more creative and varied the output will be. If the temperature is higher, the softmax value is lower because it chooses the next character with a lower probability.
So that's it... eww, now you won't feel the magic behind how AI works, and it won't seem as mysterious once you understand it.
Subscribe to my newsletter
Read articles from Krish Kalaria directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by