Alibaba Cloud’s Qwen2.5 Omni: GenAI Meets Multimodality
 Farruh
FarruhTable of contents
- Why Multimodality Matters
- Qwen2.5 Omni: Designed for Comprehensive Multimodality
- Understanding Qwen2.5 Omni: The Technical Edge
- Overview of Thinker (text/audio/video processing) and Talker (speech generation) modules
- How Qwen2.5 Omni Outperforms Other Multimodal Models
- Quickstart for Qwen2.5 Omni on Alibaba Cloud
- Advanced Use Cases: Pushing the Boundaries
- Why Learn Qwen2.5 Omni?
- Troubleshooting & Best Practices
- Conclusion: The Future is Multimodal

Read more of my articles on Alibaba Cloud Blog
In the Generative AI (GenAI) era, Large Language Models (LLMs) are no longer confined to text. Multimodal models like Qwen2.5 Omni bridge the gap between text, images, audio, and videos, enabling AI to think, see, hear, and speak - like us humans.

Why Multimodality Matters
Ubiquity of Multimodal Data: 90% of internet traffic is visual/audio content (e.g., TikTok videos, podcasts).
Human-Like Interactions: Users expect AI to process mixed inputs (e.g., a photo and a voice query).
Industry Disruption: From healthcare diagnostics to e-commerce, multimodal AI is the new standard.
Qwen2.5 Omni: Designed for Comprehensive Multimodality
Far Beyond Text: While LLMs like Qwen2.5-VL excel in text and images, Qwen2.5 Omni adds audio/video streaming, as a leap into full-sensory AI.
Unified Architecture: Unlike siloed tools, Qwen2.5 Omni is a single model for input/output across modalities.
Understanding Qwen2.5 Omni: The Technical Edge

Overview of Thinker (text/audio/video processing) and Talker (speech generation) modules
Key Innovations from the Technical Report
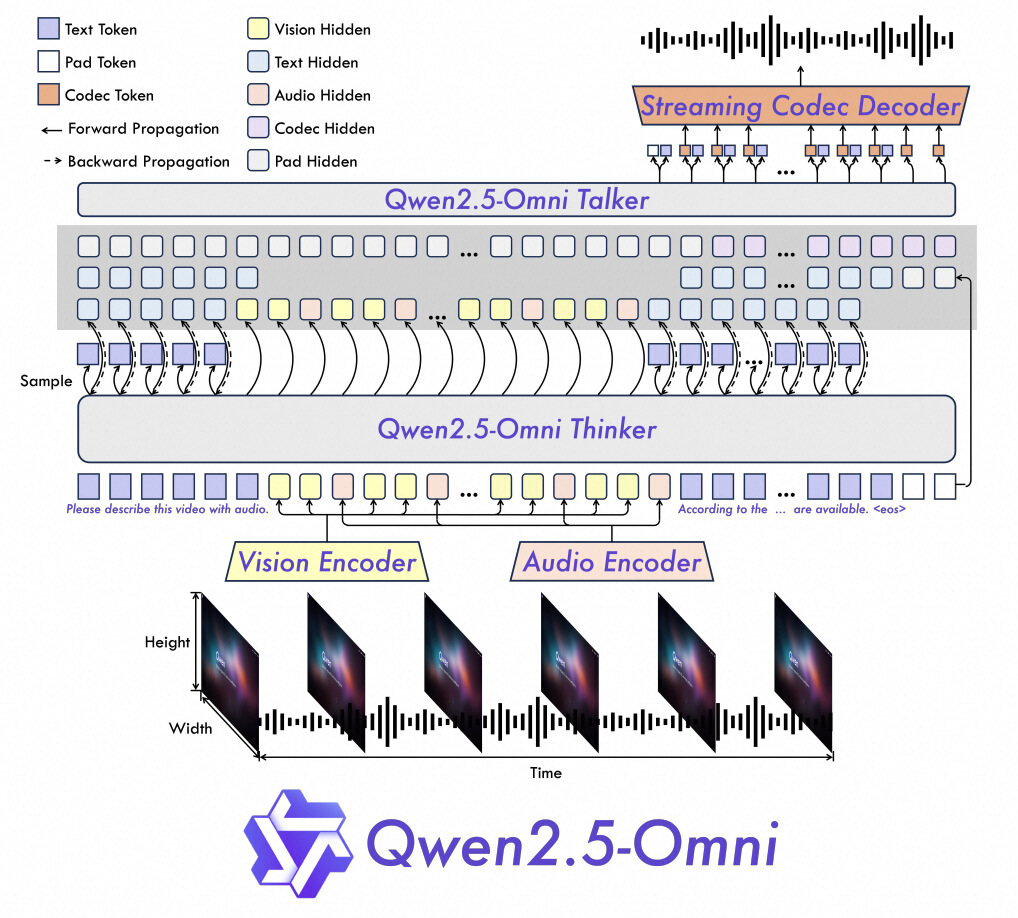
Overview of Qwen2.5-Omni with the Thinker-Talker Architecture
TMRoPE Positional Encoding:
Time-aligned Multimodal RoPE ensures audio and video frames are processed in sync (e.g., lip-syncing in videos).
Interleaved Chunking divides a video into 2-second blocks, combining visual/audio data to reduce latency.
Thinker-Talker Architecture:
Thinker: An LLM for text generation and reasoning.
Talker: A dual-track model for real-time speech generation, reducing audio latency by 40% compared to Qwen2-Audio.
Streaming Efficiency:
Block-wise Encoding processes audio/video in chunks, enabling real-time inference.
Sliding Window Diffusion Transformer (DiT) reduces initial audio delay by limiting receptive fields.
How Qwen2.5 Omni Outperforms Other Multimodal Models

| Task | Qwen2.5-Omni | Qwen2.5-VL | GPT-4o-Mini | State-of-the-Art |
| Image→Text | 59.2 (MMMUval) | 58.6 | 60.0 | 53.9 (Other) |
| Video→Text | 72.4 (Video-MME) | 65.1 | 64.8 | 63.9 (Other) |
| Multimodal Reasoning | 81.8 (MMBench) | N/A | 76.0 | 80.5 (Other) |
| Speech Generation | 1.42% WER (Chinese) | N/A | N/A | 2.33% (English) |
Why Qwen2.5 Omni Excels
Unified Model: You do not need to switch between audio and video models like Qwen2-Audio and Qwen2.5-VL.
Low Latency: Qwen2.5 Omni processes 2-second video chunks in real-time, which ideal for applications and services with real-time content.
Versatility: Qwen2.5 Omni handles end-to-end speech instructions as well as text (e.g., “Summarize this video and read it aloud”).
Quickstart for Qwen2.5 Omni on Alibaba Cloud
Step 1: Choose the Model
Go to Alibaba Cloud ModelStudio or the Model Studio introduction page.
Search for “Qwen2.5-Omni” and navigate to its page.
- Authorize access to the model (free for basic usage).
Step 2: Prepare Your Environment
Security-first setup:
- Create a virtual environment (recommended):
python -m venv qwen-env
source qwen-env/bin/activate # Linux/MacOS | Windows: qwen-env\Scripts\activate
- Install dependencies:
pip install openai
- Store API key securely:
Create a.envfile in your project directory:
DASHSCOPE_API_KEY=your_api_key_here
Step 3: Make an API Call with OpenAI Compatibility
Use the OpenAI library to interact with Qwen2.5-Omni:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
)
# Example: Text + Audio Output
completion = client.chat.completions.create(
model="qwen2.5-omni-7b",
messages=[{"role": "user", "content": "Who are you?"}],
modalities=["text", "audio"], # Specify output formats (text/audio)
audio={"voice": "Chelsie", "format": "wav"},
stream=True, # Enable real-time streaming
stream_options={"include_usage": True},
)
# Process streaming responses
for chunk in completion:
if chunk.choices:
print("Partial response:", chunk.choices[0].delta)
else:
print("Usage stats:", chunk.usage)
Key Features of API
| Feature | Details |
| Input Type | Text, images, audio, video (via URLs/Base64) |
| Output Modality | Specify modalities parameter (e.g., ["text", "audio"] for dual outputs) |
| Streaming Support | Real-time results via stream=True |
| Security | Environment variables for API keys (.env file) |
Advanced Use Cases: Pushing the Boundaries
1. Real-Time Video Analysis
Use Case: Live event captioning with emotion detection.
Input: A 10-second video clip.
Output: Text summary + audio commentary (e.g., “The crowd is cheering热烈!”).
2. Cross-Modal E-commerce
Use Case: Generate product descriptions from images and user reviews.
# Input: Product image + "Write a 5-star review in Spanish"
# Output: Text review + audio version in Spanish.
Why Learn Qwen2.5 Omni?
Future-Ready Skills: Multimodal models are the next-gen standard for AI applications.
Competitive Edge: Businesses using Qwen2.5 Omni can:
Reduce Costs: One model for all text/audio/video tasks.
Accelerate Innovation: Deploy real-time apps (e.g., virtual assistants, smart surveillance).
Troubleshooting & Best Practices
File Size Limits:
Images: ≤10MB per file.
Total Tokens: Respect the model’s 32k token limit (text + image/audio embeddings).
Optimize for Streaming:
Use Alibaba Cloud’s OSS for large files.
Enable
stream=Truefor real-time outputs.
Conclusion: The Future is Multimodal

As GenAI evolves, multimodal capabilities will dominate industries from healthcare to entertainment. By mastering Qwen2.5 Omni, you’re entering the next era of human-AI collaboration.
Start experimenting today and join the revolution!
References
Model Studio Help: Get Started Guide
Model Studio Product Page: Explore Features
Qwen2.5-Omni Blog: In-Depth Overview
Technical Report: ArXiv Paper
GitHub: Code & Docs
HuggingFace: Model Download
Wan Visual Generation: Create Amazing Videos
Subscribe to my newsletter
Read articles from Farruh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by