Query Translation Patterns: Advanced RAG
 Satvik Kharb
Satvik Kharb
“Imagine Google Search but on your personal information”
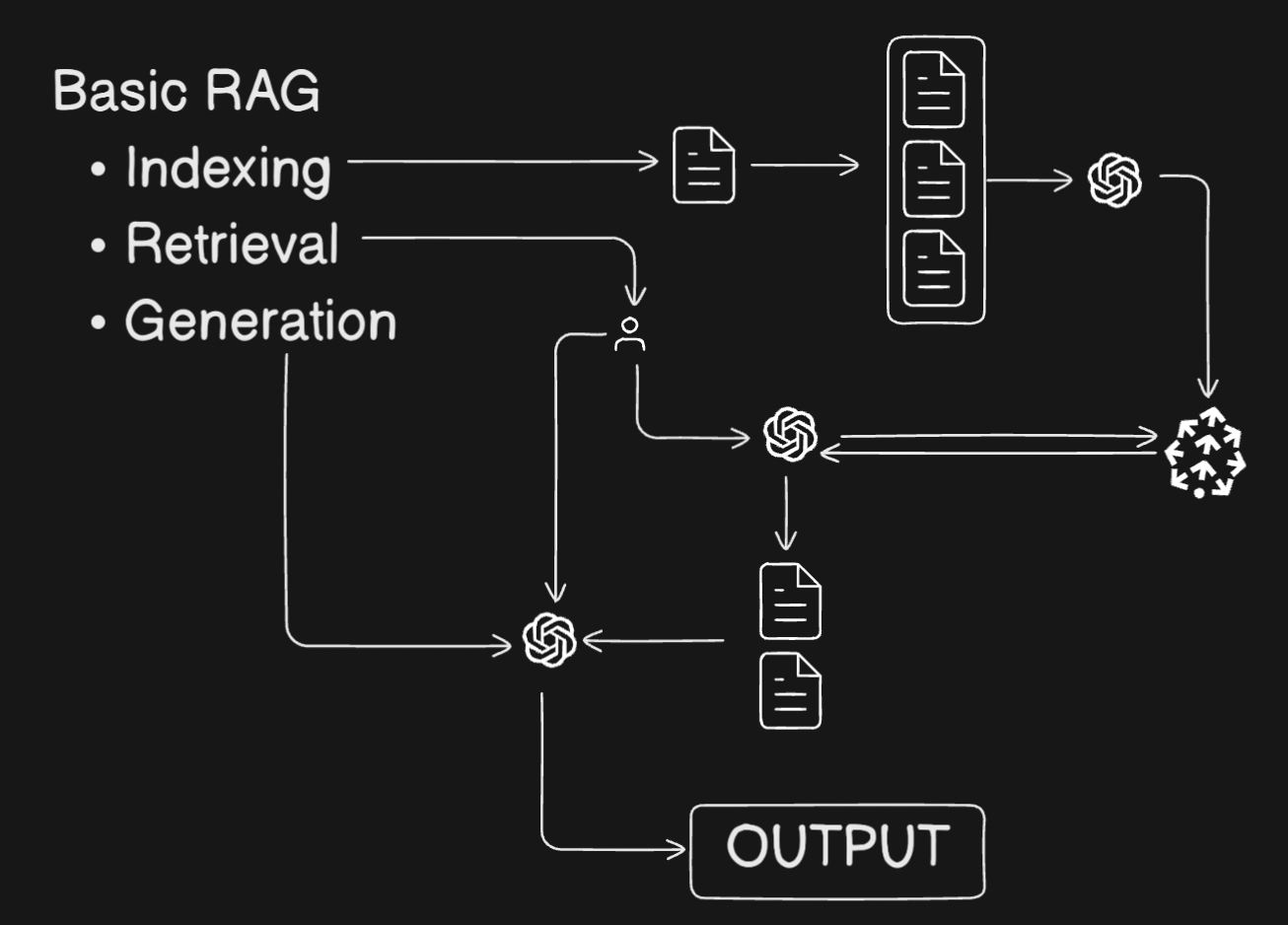
RAG or Retrieval-Augmented Generation is the method of optimizing a vanilla LLM to generate responses based on the personal data it has Retrieved.
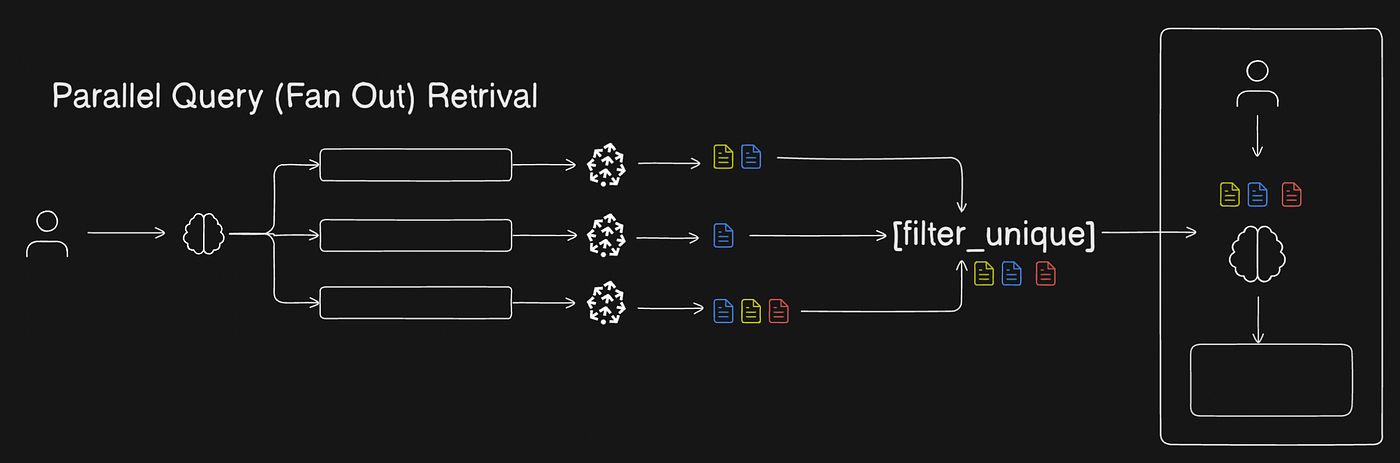
- Parallel Query Retrieval (Fan Out): Here the user query is given to a LLM and the LLM makes a few of similar yet different queries based on the user prompt. These synthetic queries generated do similarity search on the chunks of data in the documents provided and fetch out semantically similar chunks from it. We’ll get several of these chunks based on the number of queries generated by the initial LLM. We’ll filter only the distinct chunks and ingest into the result generation LLM along with the original user query.
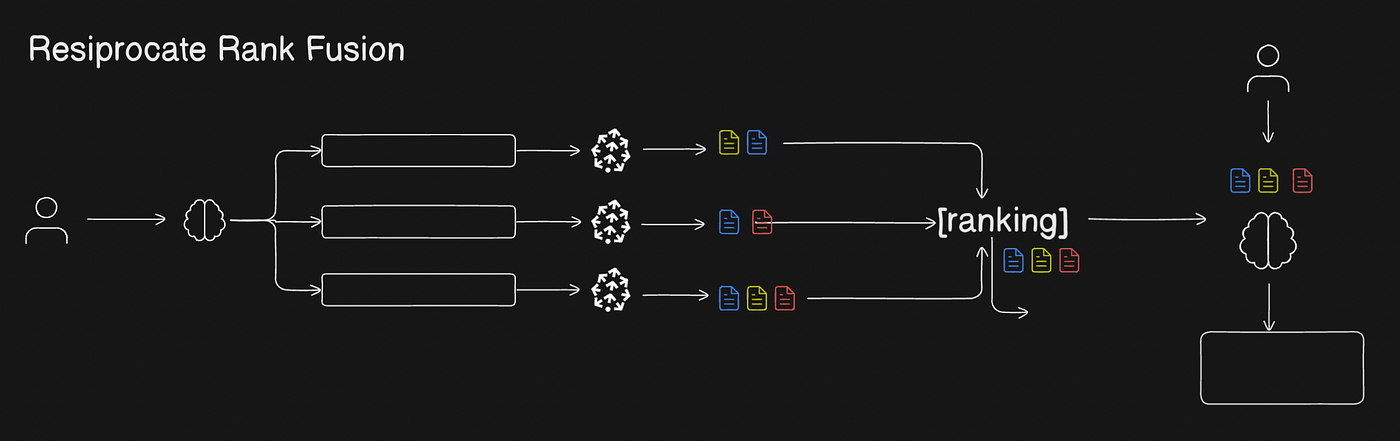
2. Reciprocal Rank Fusion: This is exactly similar to Parallel Query Retrieval with a twist. Earlier we used to pick the unique chunks/docs, now we are ranking the docs/chunks based on similarity score/frequency of occurance.
3. Step Back Prompting Algo: When the user prompt might be abstract or exact but both are a problem for the Large Language model. Why?
Chronology-
Your mom asks you to bring water- specification of hot or cold [exact]
Your mom asks you to bring something from the kitchen [Abstract]

Step back prompting allows us to step back and let the model understand, what kind of information is needed to answer user query? User sends an abstract/vague query and the model first understands the user query in depth before starting to answer it.
4. Chain of Thought(CoT) We all have seen the ability of Deepseek to correct itself. How does it do so? It uses a technique called Chain of Thought that helps itto cross verify it’s approach at each step and then give us the final answer once it’s sure in all aspects.
How is it relevant in RAG? CoT helps the LLM to think step-by-step and reason through the retrieved documents and extracts the needed/relevant chunks. This type is reasoning is helpful where the relevant information is sparse.

5. Hypothetical Document Embedding:
Here we intend to generate an overall document on the basis of the LLM’s knowledge(requiring large LLM’s) and using that document to find the relevant chunks.

How does this help? The Hypothetical document created will have wide variety of knowledge who’s vector embeddings will help us extract a huge variety of semantically similar chunks thus helping us extract nearly all the expected knowledge from the real documents.
Subscribe to my newsletter
Read articles from Satvik Kharb directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by