🔧 Optimizing RAG: How to Improve Accuracy with Advanced RAG
 Buddy Coder
Buddy CoderGuide to optimize RAG pipeline performance. Solving challenges of Retrieval-Augmented Generation.
Retrieval-Augmented Generation (RAG) is like giving your LLM a brain plus a memory card. But as usage scales, so does the need for optimization. Think of basic RAG like a one-lane road: it works, but what happens when traffic (queries) starts piling up? That’s where Advanced RAG kicks in, especially using techniques like Parallel Query Retrieval (Fan-Out). This is part of a RAG Series.
🔁 Basic RAG: The Starting Line
At its core, a RAG system runs in a 3-step loop:
You give it a document, chunk it, embed it, store it (in Pinecone, maybe).
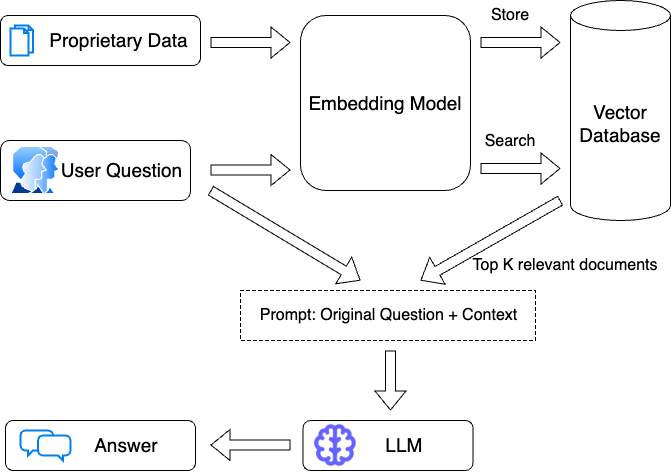
the general flow is that you take the users question and pass that directly to an embedding model. That embedding is then compared to documents stored in the vectorstore, and the top k most similar ones are returned.
I have discussed this in detail in previous article https://devsingh.hashnode.dev/rag-simplified-smarter-ai-with-real-world-knowledge
🟡 But here’s the thing: If the input query is ambiguous, the output is also ambiguous. Garbage in, garbage out (GIGO).
🤔 Let's Talk Abstraction
Let’s say a user asks:
“What is the company’s vision?”
Sounds valid, right? But…
It lacks context.
It sits at a higher level of abstraction.
It’s too open-ended, so RAG may return all kinds of loosely related stuff.
To fix this, you either:
Improve the prompt (user side)
Upgrade retrieval logic (system side)
📱Query Translation Techniques
Query translation is used in improving the effectiveness of search process. It involves transforming or reformulating the original user query into one or more alternative forms that are more likely to match relevant documents or information in the knowledge base. Query translation aims to bridge the gap between a user's natural language input and how information is structured or indexed within the system. This helps retrieve more relevant data and leads to higher-quality generated responses. There are 5 main types:
Multi Query/ Parallel Query Retrieval / Fan Out
RAG Fusion
Query Decomposition
Step Back Prompting
Hypothetical Document Embedding (HyDE)
In this article we will introduce the first one:
🚀 What is Multi Query / Parallel Query Retrieval (Fan-Out)?
Parallel Query Retrieval, also called Fan-Out, is when instead of sending just one query to the retriever, you break the user’s prompt into multiple sub-queries, run them in parallel, and then combine the results. This method uses language models to rephrase and enrich the original query, uncovering various angles or interpretations of the user's intent.
To remove ambiguity and move to less abstraction of user query, translate what user asked to what the user actually desire.
Analogy:
Imagine walking into a giant library (like... Google-sized 🏛️) and asking the librarian:
“Tell me something about climate change.”
Now, two types of librarians could help you out:
📚 Basic Librarian (Basic RAG)
They go to a shelf, pick a random book based on your vague question, skim a few pages, and read you an answer. Not bad—but not to the mark if your question wasn't clear.
⚡️ Advanced Librarian (Advanced RAG with Fan-Out)
Instead of one pass, this librarian breaks your question into focused sub-questions like:
“What causes climate change?”
“How does it affect sea levels?”
“What are possible solutions?”
Then they fan out to different sections, fetch relevant pages from multiple books, cross-reference them, and give you a much smarter, synthesized answer.
🤔 Why It Matters
Advanced RAG using Fan-Out leads to:
✅ Less ambiguity
✅ Better coverage of user intent or possible outcomes
✅ More accurate results from downstream generation
And especially when your data spans multiple domains (e.g., product docs, user guides, case studies), fan-out helps bridge abstraction levels between “what the user asked” and “what’s actually stored”.
🪭When to Use
Use Multi Query when dealing with complex or ambiguous queries, or when initial retrieval results are unsatisfactory. This technique is particularly useful in scenarios where the original query might not fully capture the user's intent or when the desired information could be expressed in various ways.
👨💻Implementation Code using NodeJs, langchainJs
📦 Setting Up the Environment
Install the necessary packages:
npm install @langchain/community @langchain/openai @langchain/textsplitters dotenv
Create a .env file in your project root and add your API keys:
OPENAI_API_KEY=your_openai_api_key
⬆️ Loading ,✂️ Splitting the document and 🧱embedding
Here I am creating sample multiple docs. You can use pdf and split it as already shown in previous article https://devsingh.hashnode.dev/how-to-build-a-rag-with-langchain-js-openai-and-pinecone-to-read-a-pdf-file.
import { ChatOpenAI } from "@langchain/openai";
import { PromptTemplate } from "@langchain/core/prompts";
import { RunnableSequence } from "@langchain/core/runnables";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { RetrievalQAChain } from "langchain/chains";
import dotenv from "dotenv";
dotenv.config();
// Initialize OpenAI model and embeddings
const model = new ChatOpenAI({ temperature: 0.2, model: "gpt-4o-mini" });
// 🔑 create embeddings
const embeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
apiKey: process.env.OPENAI_API_KEY,
batchSize: 512, //max 2048
dimensions: 1024,
});
// Sample documents
const documents = [
new Document({ pageContent: "The capital of France is Paris." }),
new Document({ pageContent: "Paris is a beautiful city in France." }),
new Document({ pageContent: "France is known for its wine and cheese." }),
new Document({ pageContent: "The Eiffel Tower is in Paris." }),
];
// Create a vector store from the documents
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 50,
});
const splits = await splitter.splitDocuments(documents);
🗃️ Storing Embeddings in vector Db
In this example I have used langchain memory vector. You can use pinecone or other vector db. Implementation using pinecode db can be seen in the previous article.
const vectorStore = await MemoryVectorStore.fromDocuments(splits, embeddings);
console.log("🚀 ~ vectorStore:", vectorStore);
sample output of vector store -

🔍 Retrieving Relevant Chunks
Define prompt for generating multiple queries.
// --- MultiQuery Implementation --- // 1. Define a prompt for generating multiple queries const multiQueryPrompt = PromptTemplate.fromTemplate( `Generate multiple search queries based on the user's question to retrieve relevant documents. The queries should be diverse and cover different aspects of the question. User question: {question} Queries: (in a comma-separated list)` );Create a chain for generating multiple queries through pipeline.
// 2. Create a Runnable chain for generating multiple queries const multiQueryChain = RunnableSequence.from([ multiQueryPrompt, model.pipe(new StringOutputParser()), (output) => output.split(",").map((query) => query.trim()), ]);Write function to retrieve documents for each parallel query (generated query)
// 3. Define a function to retrieve documents for each generated query
async function retrieveDocuments(queries) {
const results = await Promise.all(
queries.map((query) => retriever.getRelevantDocuments(query))
);
// Flatten the results and remove duplicates (optional, but recommended)
const uniqueDocuments = Array.from(
new Set(results.flat().map((doc) => JSON.stringify(doc)))
).map((json) => JSON.parse(json));
return uniqueDocuments;
}
🧠 Generating Responses with OpenAI
- Create prompt
// 4. Define a prompt for the final answer
const answerPrompt = PromptTemplate.fromTemplate(`You are a helpful assistant. Answer the question based on the provided context.
Context:
{context}
Question: {question}
Answer:`);
Create a final chain that orchestrates the process :
Generating multiple search queries from a user question.
Retrieving relevant documents for those queries.
Using the retrieved documents to generate a final answer.
The chain is created using RunnableSequence.from(), which combines multiple steps into a sequential pipeline.
Each step processes the input and passes its output to the next step.
Input: The user provides a question.
Query Generation: The multiQueryChain generates multiple search queries.
Document Retrieval: Relevant documents are retrieved for the generated queries.
Answer Generation: The retrieved documents are used as context to generate a final answer.
Output: The final answer is returned.
// 5. Create the final chain
const multiQueryRAGChain = RunnableSequence.from([
{
question: (input) => input.question,
context: async (input) => {
const queries = await generateMultiQueryChain.invoke({
question: input.question,
});
const retrievedDocs = await retrieveDocuments(queries);
// console.log("retrievedDocs:", retrievedDocs);
return retrievedDocs;
},
},
{
Answer: answerPrompt,
Question: (input) => input.question,
Context: (input) => input.context.map((doc) => doc.pageContent).join("\n"),
},
async (input) => {
const response = await model.invoke(input.Answer); //process answerPrompt
return response;
},
new StringOutputParser(),
]);
The retrievedDocs gave relevant documents array based on queries.

The documents are used to form answerPrompt with context and question. This is then fed to model to generate final answer.
- Usage:
// --- Usage ---
async function main() {
const question = "What is Paris known for?";
console.log("--- MultiQuery Retrieval ---");
const multiQueryResult = await multiQueryRAGChain.invoke({ question });
console.log("final Answer:", multiQueryResult); // Ensure the final answer is logged
}
main().catch(console.error);
The multiple queries generated are
Queries:1. "What are the main attractions in Paris?"
2. "Cultural significance of Paris"
3. "Famous landmarks in Paris"
4. "What is Paris famous for in terms of cuisine?"
5. "Historical events associated with Paris"
6. "Art and museums in Paris"
7. "Paris fashion and shopping highlights"
8. "Paris nightlife and entertainment"
9. "What makes Paris a romantic destination?"
10. "Parisian architecture and its importance"
11. "Festivals and events celebrated in Paris"
12. "Influential figures from Paris"
13. "Paris as a center for education and innovation"
14. "Tourist experiences in Paris"
15. "Parisian neighborhoods and their unique characteristics"
Answer received:

🔗Git Link
Full source link https://github.com/Devendra616/cohort-rag-pdf/blob/main/ParallelQuery.js
📈 Final Thoughts
Advanced RAG isn't just a “nice-to-have”—it's essential if you're building production-grade AI pipelines where accuracy, context, and intent actually matter.
➡️ Fan-Out Retrieval is one of the most effective optimizations you can add to your RAG stack. Combine it with smarter prompts and context ranking, and your LLM won't just be smart—it'll be laser focused.
If this helped you level up your RAG knowledge, smash that ❤️, drop a 💬 if you’ve got questions, and hit follow for more AI + dev breakdowns! Got a project or idea? Let’s discuss it together.
Thanks for reading—keep building dope stuff! 💻🚀
Subscribe to my newsletter
Read articles from Buddy Coder directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by