AWS Fault Injection Service (FIS)
 Rupak Chakraborty
Rupak ChakrabortyTable of contents
- What Is AWS Fault Injection Service?
- What is Chaos Engineering?
- Why Use AWS Fault Injection Simulator?
- The Exam Analogy: Chaos Engineering as Your Practice Test
- The FIS Experiment Lifecycle: Your Mock-Test for Production Readiness
- Experiments and Experiment Templates
- Pre-requisites: Checklist Before You Break Things
- Common Fault Scenarios
- The 10 Golden Rules of Running AWS FIS Experiments
- Real-Life Use Cases: How AWS FIS Helps Companies
- Integrations with AWS Ecosystem
- Metrics & Monitoring: Tracking Success During AWS FIS Experiments
- Final Thoughts
- Endcard
Imagine preparing for a major exam without ever taking a mock test. Sure, you’ve studied — but how do you know your strategy holds under pressure?
This is exactly why companies embrace chaos engineering, and why AWS built a tool to make it safe and structured: AWS Fault Injection Simulator (FIS).
In this post, we’ll break down AWS FIS in depth — from setting it up to best practices — using exam analogies, hands-on tips, and clear insights that’ll help you confidently inject failure into your cloud.
What Is AWS Fault Injection Service?
AWS FIS is a managed chaos engineering tool that helps you test how your AWS environment responds to failures, such as instance terminations, API throttling, or network latency. By running controlled experiments, you can simulate real-world disruptions and learn how your systems behave under stress.
Think of FIS as your exam hall for production readiness. Instead of guessing whether your app will survive a database failure, you simulate it, learn from it, and strengthen your architecture to ensure real-world success.

What is Chaos Engineering?
Chaos engineering is like giving your system a real-world stress test — on purpose. It’s the practice of injecting failures like server crashes or network issues to see how your application reacts under pressure. You start by defining what “normal” looks like, form a hypothesis, then trigger faults in a controlled way. The goal? To uncover hidden weaknesses, monitor how systems recover, and make them stronger before real failures hit.
At its core, chaos engineering is about proactive testing. The earlier you uncover issues, the sooner you can fix them and ensure your system's resilience.
Why Use AWS Fault Injection Simulator?
AWS Fault Injection Simulator isn’t just about breaking things for fun — it’s about building systems that bounce back stronger. Here’s why it’s worth your time:
Validate High Availability and Failover Mechanisms:
You’ve built your application across multiple Availability Zones or with auto-scaling in place — but will it actually recover when a node fails? FIS lets you test those high-availability (HA) setups in real time, confirming that failovers trigger correctly and workloads shift seamlessly.Discover Hidden Single Points of Failure:
Even the best-designed architectures can have hidden weaknesses — a misconfigured load balancer, an overlooked dependency, or a critical service with no redundancy. FIS exposes these blind spots before your users do, allowing you to address them before they become costly issues.Improve Incident Response Playbooks:
Chaos experiments don’t just test machines; they test your team. How fast can your team detect issues? Are alerts reaching the right people? Can incidents be resolved without escalating into panic? FIS helps refine your response strategy by showing what happens when things go wrong — and how your team handles it.Meet SLAs with Confidence:
When you're contractually bound to 99.9% uptime, "we think it'll hold" isn’t enough. Regular FIS testing gives you confidence — backed by data — that your system can withstand real-world disruptions and still hit your Service Level Agreements (SLAs).
As Werner Vogels, AWS CTO, famously said: "Everything fails, all the time."
The Exam Analogy: Chaos Engineering as Your Practice Test
Let’s break down AWS FIS using an analogy every student can relate to:
| Exam World | AWS World |
| Mock Test | Chaos Experiment |
| Syllabus | Cloud Architecture |
| Unexpected Question | Fault Injection |
| Timer | Stop Condition |
| Teacher Supervision | IAM Permissions + CloudWatch Alarms |
| Marks | Cloud Metrics & Logs |
Why take a mock test? To understand how you perform under stress.
Why use AWS FIS? To know how your system performs under failure.
So, you’re not learning just to pass. You’re preparing to handle the unknown confidently.
The FIS Experiment Lifecycle: Your Mock-Test for Production Readiness
Running a chaos experiment is like taking a mock exam to test your preparedness. Here's how the FIS experiment lifecycle works:
Define Hypothesis: What are you trying to learn?
Choose Targets: Where do you want to simulate failure?
Select Actions: What kind of failure will you inject?
Set Stop Conditions: What should make you stop the experiment early?
Run Experiment: Monitor carefully.
Analyze & Improve: What did you learn, and what can you improve?
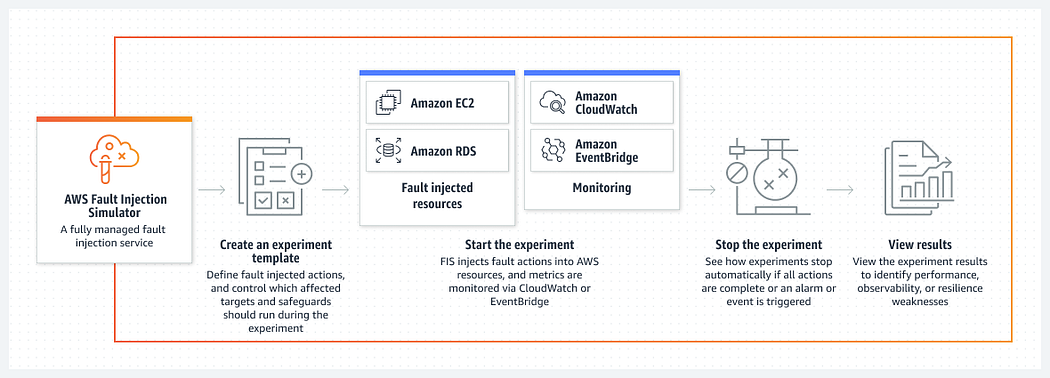
Experiments and Experiment Templates
In AWS FIS, an experiment is a real-time fault injection activity where you simulate failures (like instance termination or network latency) to test how your system responds.
Experiment templates are predefined blueprints that describe which faults to inject, which resources to target, and what stop conditions to set. These templates allow you to standardize and repeat chaos tests safely and consistently.

Pre-requisites: Checklist Before You Break Things
Before launching your first experiment, here’s a checklist of what you need to set up:
Target Resources Ready: Ensure your EC2, ECS, RDS, etc., are running and properly tagged for targeting.
SSM Agent Setup (for EC2 actions): The Systems Manager (SSM) agent should be installed and running, and the instance must have an instance profile with
AmazonSSMManagedInstanceCore.IAM Role for FIS: The FIS service role must be properly set up with permissions based on the experiment type (e.g., EC2: reboot, stop, terminate).
CloudWatch Alarms (Stop Conditions): Set up alarms to automatically stop a fault injection experiment if certain thresholds are exceeded (e.g., CPU usage > 90%, error rate > 10%).
Region Support & Quotas: Make sure the AWS region supports the actions you plan to execute.
Common Fault Scenarios
| Type of Fault | Example |
| EC2 | Stop, reboot, terminate instance, inject CPU stress |
| ECS/EKS | Kill container, stop task, CPU/memory throttling |
| RDS | Reboot instance, failover |
| Network | Packet loss, latency injection (via SSM) |
| Auto Scaling | Disable scale-in protection |
| API Throttling | Simulate API rate limit errors |
| SSM Command | Custom scripts or failure simulation on OS level |
The 10 Golden Rules of Running AWS FIS Experiments
If you're going to intentionally break things in your environment, you need to do it with precision, planning, and purpose. Here are ten best practices — the golden rules — for running successful chaos experiments using AWS FIS:
1. Define a Clear Hypothesis
Start with a focused question: What exactly are you trying to prove or learn? Are you testing failover mechanisms, monitoring tools, or recovery time? A well-defined hypothesis helps you measure success and avoid unstructured chaos.
2. Start in a Non-Production Environment
Before experimenting in production, validate your experiment in a dev or staging environment. This reduces risk while giving you confidence that your application and recovery strategies behave as expected.
3. Always Define Stop Conditions
Use CloudWatch alarms to automatically stop an experiment if critical thresholds are breached — such as CPU usage spikes or error rates. This acts as your safety net to avoid real outages.
4. Use Tags for Target Selection
Tagging resources allows precise targeting of instances, containers, or databases during experiments. It ensures that only the intended resources are affected and helps enforce resource-level access control.
5. Scope IAM Roles Properly
Least privilege always applies. Grant AWS FIS only the permissions it needs to perform specific actions on defined resources. Avoid broad permissions like *:*, especially in production environments.
6. Monitor in Real Time
Don’t "fire and forget." Watch logs, metrics, and alarms in real-time during your experiment. Monitoring ensures you're aware of impacts as they happen and can respond if necessary.
7. Communicate Before You Inject
Let relevant teams know when and why an experiment will run. Involving DevOps, support teams, and even business stakeholders ensures there are no surprises and fosters a culture of shared resilience.
8. Keep Experiments Reproducible
Use version-controlled experiment templates. This allows teams to rerun tests consistently, debug easier, and compare outcomes over time. It also helps with compliance and auditing.
9. Document Everything
Capture what happened, what failed, what worked, and what you learned. These records will improve incident response plans, architecture design, and help onboard new team members with real-world scenarios.
10. Iterate Continuously
Chaos engineering isn’t a one-time exercise. As your system evolves, so do its failure points. Schedule recurring tests to ensure ongoing resilience, especially after major releases or infrastructure changes.
Real-Life Use Cases: How AWS FIS Helps Companies
AWS Fault Injection Simulator is being leveraged by various organizations to ensure their systems can withstand unexpected failures and maintain optimal uptime. Below are a few examples of how companies are benefiting from AWS FIS:
E-Commerce Platform – Improving Uptime During Peak Sales Events: A major e-commerce platform used AWS FIS to test how their infrastructure would behave during high-traffic sales events like Black Friday. By simulating network latency and API throttling, they were able to identify and fix bottlenecks in their auto-scaling policies. As a result, the platform experienced fewer disruptions during peak traffic times and was able to handle higher customer demand with greater reliability, improving overall customer satisfaction.
Financial Institution – Enhancing Disaster Recovery Readiness: A financial institution in the U.S. used AWS FIS to simulate database failures and network partitioning in a multi-region setup. This allowed them to validate their failover mechanisms and disaster recovery plans, ensuring that their system could handle major failures without compromising service availability. By running these controlled experiments, the company was able to enhance their incident response times and meet stringent SLAs, offering more reliable financial services to their clients.
Streaming Service – Improving Service Continuity During Global Events: A global streaming service used AWS FIS to simulate instance terminations across multiple Availability Zones to test the resilience of their service during a global event. The testing revealed some flaws in their redundancy configurations, which were subsequently addressed, resulting in improved uptime during high-demand periods like major live event broadcasts. By using FIS, they proactively minimized the chances of service disruption, improving the user experience for millions of viewers.
Integrations with AWS Ecosystem
AWS FIS integrates seamlessly with other AWS services to offer more powerful and automated fault injection experiments. Here’s how these integrations enhance the testing process:
AWS Lambda – Automating Responses During Experiments: AWS FIS can be integrated with AWS Lambda to automate responses during experiments. For instance, if a particular fault injection, such as an API failure, occurs, AWS Lambda can be used to trigger automatic corrective actions, such as restarting services or rerouting traffic to healthy resources. This integration can help reduce manual intervention and enable more sophisticated, automated chaos engineering workflows.
AWS CloudWatch – Monitoring and Alerts: AWS FIS works hand-in-hand with AWS CloudWatch to monitor metrics and set alarms during experiments. CloudWatch helps track resource utilization, such as CPU and memory usage, and sends alerts when predefined thresholds are breached. This integration ensures that you can stop an experiment early if certain conditions are met, preventing potential damage and ensuring that any anomalies are caught quickly.
AWS CodePipeline – Continuous Testing: For organizations practicing continuous integration and continuous delivery (CI/CD), AWS FIS can integrate with AWS CodePipeline to inject faults at various stages of the software release process. By doing this, companies can ensure that their code is resilient to failure even before it goes into production. This integration enables teams to test their systems under realistic conditions in a controlled manner before deploying to a live environment, helping to reduce the risk of production incidents.
Metrics & Monitoring: Tracking Success During AWS FIS Experiments
The real value of AWS FIS comes from the insights you gain through experimentation. Monitoring and tracking the right metrics during and after the experiment ensures that the results are meaningful and actionable. Here are some important metrics and monitoring practices to follow:
Resource Utilization Metrics: During chaos experiments, track key metrics like CPU usage, memory utilization, disk I/O, and network throughput. These metrics can give you a clear picture of how the system is performing under stress. If CPU usage spikes to an unusually high level or network throughput drops, it indicates that the fault is having a significant impact on your resources.
Error Rates & Latency: Monitoring error rates and latency is crucial for understanding how your system handles disruptions. For instance, if you’re simulating API throttling, check the error rates (e.g., 5xx errors) and ensure that they remain within acceptable limits. Similarly, latency spikes during network issues will help you evaluate how your application’s performance is impacted under load.
Recovery Metrics: One of the most important aspects of chaos engineering is testing how well your system recovers after a failure. Metrics like Mean Time to Recovery (MTTR) and Mean Time Between Failures (MTBF) will help you gauge the effectiveness of your failover mechanisms and recovery strategies. If your system recovers slowly or fails to recover, you can dive deeper into the root causes and make necessary adjustments.
Health Checks & Availability: AWS FIS provides the ability to monitor health checks on critical resources during experiments. For example, when you simulate instance terminations, track the availability of your application and ensure that your health checks are functioning correctly to trigger failovers when necessary.
CloudWatch Alarms & Automated Responses: Setting up CloudWatch Alarms allows you to stop an experiment early if performance exceeds or falls below certain thresholds. For instance, you might want to halt the experiment if latency exceeds 500ms or if the error rate rises above a specific threshold, thereby preventing any unintended disruptions in your system.
By closely tracking these metrics and analyzing them after the experiment, you can not only confirm that your system is resilient but also uncover areas that need improvement, ensuring a more reliable and robust production environment in the long run.
Final Thoughts
AWS FIS is your exam hall for resilience. It’s where you learn:
What breaks
What recovers
What you can improve
Run it with care. Run it with purpose. Run it often.
Chaos engineering is not about testing your systems just once but integrating failure simulations into your regular testing practices. By doing so, you ensure that your systems are not only built to survive failures but to recover swiftly and keep delivering value to your customers.
"Hope is not a strategy. Test your systems the hard way — before reality does it for you."
Endcard
Thank you for joining me on this insightful blog on AWS FIS.
If you found this blog helpful and informative, don't forget to give it a like!
Stay updated with my latest posts and never miss out on exciting content! Click that Follow button to join and stay in the loop!
Follow me on Linkedin --> rupak1chakraborty
Stay tuned for more such content...👋🔍🌈
Subscribe to my newsletter
Read articles from Rupak Chakraborty directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by