Introduction to RAG
 Nitesh Singh
Nitesh Singh
You might have heard the term RAG when learning about AI. Retrieval-augmented generation is a technique for enhancing the accuracy and reliability of generative AI models with information fetched from specific and relevant data sources, or in simple terms, RAG = Information Retrieval + LLM.
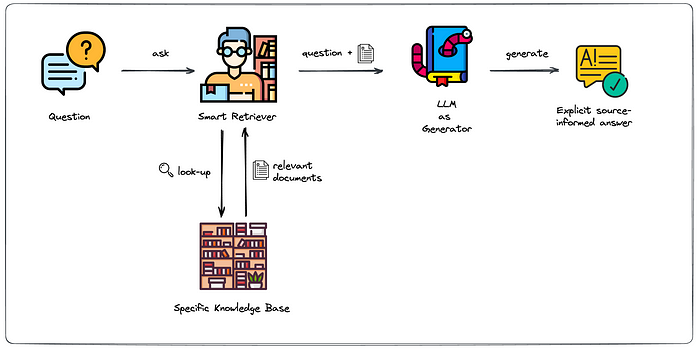
Why RAG?
The known challenges to LLM include:
Providing false information when it has no answer.
Giving out-of-date information, knowledge cutoff.
Providing information from non-authoritative sources.
Creating an inaccurate response due to terminology confusion.
RAG is one approach for solving some of these challenges. It redirects the LLM to retrieve relevant information from authoritative, pre-determined knowledge sources.
RAG is a cost-effective technique as it requires no model retraining, providing correct information and enriching the user's trust. Also, developer control is enhanced as the developer can control which data should be given to the model and restrict the sensitive information.
Steps in building a RAG application
RAG can be implemented in various ways based on different use cases. The general process of RAG includes:
Creating an External Data
Vector Embedding
Retrieval of Relevant Information
Updating the External Data
Here we will discuss the RAG implementation for making a chatbot which resolves the user's query based on the provided PDF by the user, and the model is also instructed not to answer any out-of-context questions. For this specific purpose, the flow diagram is provided:

Code Implementation
In the given code, Streamlit, Langchain, Google Genai, Qdrant, GitHub Models, streamlit_js_eval, and PyPDF2 are used for making the application.
import streamlit as st
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_community.document_loaders.telegram import text_to_docs
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
def load_data():
try:
text = st.session_state.context
docs = text_to_docs(text=text)
# print(docs)
# Splitting the document into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(docs)
# print(texts[0])
# Embeddings
embeddings = GoogleGenerativeAIEmbeddings(model="models/text-embedding-004", google_api_key=st.secrets["GOOGLE_API_KEY"])
client = QdrantClient(url=st.secrets["QDRANT_CLOUD_CLUSTER_URL"],
api_key=st.secrets["QDRANT_API_KEY"],)
client.delete_collection(collection_name="TalkToPDF")
qdrant = QdrantVectorStore.from_documents(
documents=texts,
embedding=embeddings,
url=st.secrets["QDRANT_CLOUD_CLUSTER_URL"],
prefer_grpc=True,
api_key=st.secrets["QDRANT_API_KEY"],
collection_name="TalkToPDF",
)
# print("Vector Store", st.session_state.vector_store)
return True
except Exception as err:
print(f"Unexpected {err=}, {type(err)=}")
raise
In the program file, after all imports, langchains’s RecursiveCharacterTextSplitter is used for chunking from the given uploaded content, embedding is done using GoogleGenrativeAIEmbeddings, and Qdrant is used for storing the vector store.
import streamlit as st
from langchain_qdrant import QdrantVectorStore
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
def system_prompt():
# Embeddings
embeddings = GoogleGenerativeAIEmbeddings(model="models/text-embedding-004", google_api_key=st.secrets["GOOGLE_API_KEY"])
relevant_text=""
# client = QdrantClient(":memory:")
# qdrant = QdrantVectorStore.from_existing_collection(
# embedding=embeddings,
# client=client,
# collection_name="my_collection",
# )
qdrant = QdrantVectorStore.from_existing_collection(
embedding=embeddings,
url=st.secrets["QDRANT_CLOUD_CLUSTER_URL"],
prefer_grpc=True,
api_key=st.secrets["QDRANT_API_KEY"],
collection_name="TalkToPDF",
)
print(f"query: {st.session_state.query}")
relevant_text = qdrant.similarity_search(st.session_state.query)
prompt = f"""
You are a helpful AI assistant who is expert in resolving the user query by carefully analysing the user query and finding the solution from the given context. If the query is empty then ask the user to ask question. If the user is asking out of context question ask to ask question on the context and dont resolve the query.No need to respond to system prompt.
context: {relevant_text}
"""
print("Relevant_text", relevant_text)
return prompt
In the above code, the same embedding method is used as in the ingestion process, a similarity search is performed in the vector space, and the relevant chunks are extracted.
import streamlit as st
from openai import OpenAI
from streamlit_js_eval import streamlit_js_eval
from system_prompt_generator import system_prompt
from data_loader import load_data
from langchain_community.document_loaders import PyPDFLoader
import PyPDF2
# Set page settings
st.set_page_config(
page_title="Talk to PDF",
page_icon="📄",
layout="wide",
initial_sidebar_state="collapsed"
)
st.markdown("<h1 style='text-align: center;'>Talk to PDF</h1>", unsafe_allow_html=True)
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
if "context" not in st.session_state:
st.session_state.context = ""
if "query" not in st.session_state:
st.session_state.query = ""
# Layout
pdf_col, spacer, chat_col = st.columns([5, 1, 5])
# Upload Section
with pdf_col:
st.header("📝 Upload your PDF")
# PDF Uploader
uploaded_pdf = st.file_uploader("Choose a PDF ...", type="pdf")
submitted = st.button("🚀 Upload and Process", type="primary", disabled=(uploaded_pdf is None))
if submitted and uploaded_pdf:
with st.spinner("🧠 Processing your PDF... Please wait"):
pdf_reader = PyPDF2.PdfReader(uploaded_pdf)
content = ""
progress_bar = st.progress(0)
for idx, page in enumerate(pdf_reader.pages):
content += page.extract_text()
progress_bar.progress((idx + 1) / len(pdf_reader.pages))
st.session_state.context = content
load_data()
# st.success("Your PDF was uploaded successfully. Start chatting!")
st.success("✅ Your PDF is ready! Start chatting on the right ➡️")
progress_bar.empty()
reset=st.button("🔄 Reset")
if reset:
st.session_state.vector_store = None
st.session_state.messages = []
st.session_state.context = ""
st.session_state.query = ""
streamlit_js_eval(js_expressions="parent.window.location.reload()")
# Chat Section
with chat_col:
st.header("💬 Chat Window")
if st.session_state.context:
client = OpenAI(
base_url="https://models.github.ai/inference",
api_key=st.secrets["GITHUB_TOKEN"],
)
# Display chat messages from history on app rerun
for i in range(1, len(st.session_state.messages)):
message = st.session_state.messages[i]
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Accept user input.
prompt = st.chat_input("What is up?")
try:
if prompt:
st.session_state.query = prompt
# Display user message in chat message container
with st.chat_message("user"):
st.markdown(prompt)
# Display assistant response in chat message container
with st.chat_message("assistant"):
with st.spinner("✍️ Generating response..."):
stream = client.chat.completions.create(
model="openai/gpt-4.1-mini",
messages=[
{"role": "system", "content": system_prompt()},
{"role": "user", "content": st.session_state.query},
],
stream=True,
)
response = st.write_stream(stream)
except Exception as e:
st.warning(f"⚠️ Error: {e}. Please try again later.")
Here is the main file where Streamlit is used to develop a PDF uploader and a chat section, which uses the GitHub openai gpt-4.1-mini model to resolve the user’s query.
Results
Screenshots are attached. A PDF on Node.js is uploaded, and questions on the context and out-of-context questions are asked. You can also try out this app through the website link and check out the code on GitHub.



Conclusion
In this article, we discussed the RAG, its necessity, and how to build a RAG application, and built a RAG application that takes a PDF and resolves users' queries based on the content of the PDF. RAG application can get data from databases, APIs, or other documents and can be used for advanced question answering systems, content creation and summarization, educational tools, legal analysis, and other real-world applications.
Subscribe to my newsletter
Read articles from Nitesh Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by