Network Engineers' Introductory Guide to NCCL
 adel Iazzag
adel Iazzag
Introduction
In the rapidly evolving field of large language models (LLMs) and deep learning, training these complex models often requires distributed computing. This involves splitting the workload across multiple GPUs or even multiple nodes to achieve faster training times. However, running these parallel workloads necessitates a high level of synchronization and efficient communication between the GPUs.
NCCL, or the NVIDIA Collective Communications Library, is a powerful tool that enables deep learning frameworks like PyTorch and TensorFlow to coordinate communications between NVIDIA GPUs in a distributed manner, ensuring speed and efficiency. This library plays a crucial role in optimizing the collective communication operations essential for parallel and distributed computing.
Wait a second, I’m a network engineer. Why should I care?
As network engineers, we speak a certain language, one made up of bytes, bandwidth, switches, and links. The compute infrastructure and ML/AI application teams have their own technical jargon as well. But to design and operate the networks that power modern AI workloads, we need to understand what’s actually running over them.
A GPU cluster works as a single system — which is why it’s often called a supercomputer. Bridging the gap between teams means going beyond our own domain and learning enough about theirs to make smarter decisions and build better infrastructure.
What are Collective Communication Operations?
Imagine you're faced with a massive problem. If you work on it alone, the time required to solve it is directly tied to how much time and effort you can personally invest. Now, imagine having a team of 10 people. You could break the problem into 10 smaller pieces, assign one piece to each person, and then combine the results. Instead of taking the full time to do everything yourself, the team solves the problem in parallel, completing it in roughly one-tenth the time. This is the core idea behind collective communication in distributed systems and parallel computing: splitting work across multiple processing units, executing in parallel, and efficiently reassembling the results.
Collective communication operations are fundamental communication patterns used in parallel and distributed computing scenarios. Depending on the deep learning algorithm configured in PyTorch or TensorFlow, these frameworks choose the most suitable GPU communication pattern for the specific use case. Some key collective operations include:
AllReduce (Reduce + Broadcast): Combines data from all participating GPUs into a single value and copies it back to each GPU. Useful for tasks like calculating the total loss during training or summarizing statistics across all data.
Reduce: Combines data from all participating GPUs into a single value and sends it to one GPU.
Broadcast: Sends data from one GPU to all other participating GPUs. Ideal for sharing initial model parameters or sharing important updates with all GPUs.
Gather: Gathers data from all GPUs and distributes it to one GPU, resulting in that GPU having a copy of all the data from all other GPUs.
AllGather: Gathers data from all GPUs and distributes it to all GPUs, resulting in each GPU having a copy of all the data from all other GPUs.
ReduceScatter: Splits the data into chunks, reduces each chunk across GPUs, and scatters each chunk back so that each GPU ends up with a distinct portion of the reduced result.
Scatter: Sends data from one GPU and distributes it across multiple GPUs.

NCCL (pronounced nickel), also known as the Nvidia Collective Communications Library, is a library created to optimize and coordinate the collective communication operations explained above between Nvidia GPUs.
How Each GPU Receives “Ranks”
Each GPU participating in the logical job receives a unique identifier called a rank. This happens when MPI is initialized. Here is a high-level overview of the order of operations:
Resource Allocation:
- Orchestrators like SLURM or Kubernetes allocate the requested resources. For example, if the user requests 8 GPUs, the scheduler might allocate 2 nodes with 4 GPUs each.
Process Initialization:
The orchestrator initiates processes on each allocated node.
These processes initialize and set up the infrastructure for communication between them. Each process receives a unique identifier called a rank.
The specific mechanism for assigning ranks depends on the framework or system being used, such as MPI, TensorFlow, PyTorch, or custom scripts. Each process knows its rank and can establish connections with other processes based on predefined communication patterns (e.g., all-to-all, ring, tree).
NCCL Initialization:
NCCL initializes within each MPI process.
NCCL discovers the hardware topology and creates optimized communication paths based on the detected hardware. For example, if NCCL detects that 8 GPUs are interconnected using an NVSwitch, it will prefer using that over network connections for data exchange.
Underlying collective communication topologies
During the collectives discussed above, NCCL orchestrates the communication paths between GPUs necessary for exchanging the required data. We can see the communication patterns in two ways:
Ring-based topology
In ring-based topology, each GPU communicates with a GPU that NCCL determined to be its neighbor. It determines that by using different parameters such as bandwidth, interconnect type, inter-intra node GPU, etc. As seen below, this ring topology can be applied to multiple topologies.

Practical example of ring-based topology:

Each arrow actually represents N–1 sub-steps (one chunk per hop), but I’ve collapsed them into a single pass here for simplicity. More info on the exact steps in this NCCL presentation slide deck.
Tree-based topology
In tree-based topology, GPUs are organized hierarchically. This is useful for operations like reductions and broadcasts where data can be aggregated or distributed in a hierarchical manner. The tree structure is built such that communication flows efficiently from leaf nodes to the root (for reductions) or from the root to the leaf nodes (for broadcasts).
Reduction Operation
Tree construction:
A single tree structure is constructed with one GPU designated as the root.
Other GPUs are organized hierarchically below the root in a way that minimizes communication latency and maximizes bandwidth.
Data Aggregation:
Leaf nodes send their data to their parent nodes.
Intermediate nodes receive data from their children, perform partial reductions, and send the results up to their parent nodes.
The root node receives the final partial results and performs the final reduction.
Broadcast Operation
Tree Construction:
A single tree structure is constructed with one GPU designated as the root.
Other GPUs are organized hierarchically below the root.
Data Distribution:
The root node sends the data to its child nodes.
Intermediate nodes receive data from their parent nodes and forward it to their child nodes.
Leaf nodes receive the final broadcasted data.

Point-to-point communications
Point-to-point communication in NCCL involves direct data exchange between pairs of GPUs. This type of communication is different from collective operations, as it only involves two GPUs at a time, rather than coordinating across multiple GPUs.
Common network issues during collective communications
Incast Congestion and Buffer Drops
Too many senders, one receiver.
In distributed GPU training, certain collective operations like gather and reduce can cause many GPUs to send data simultaneously to a single destination. This creates a many-to-one communication pattern, known as incast. This usually happens in tree-based topologies in large-scale networks as data is moving up the tree and is aggregated by intermediate nodes.

For example, assume GPU nodes G1, G2, G3, and G4 are all sending data to a root GPU (R1) via the same leaf switch. If each GPU sends at 100 Gbps but the receiver's link or switch port only supports 100 Gbps, the total ingress exceeds capacity. In traditional Ethernet networks, this oversubscription results in buffer overflows and packet drops — a critical issue in training workloads where retransmissions are costly or unsupported.
These drops are especially problematic in direct gather or reduce collectives, where synchronized communication is required and recovery from packet loss may not be automatic.
Bursty traffic
During a model training workload, GPUs alternate between computing and communication phases. This means they switch from performing calculations to exchanging results across the cluster. If you were to analyze a GPU switch port using a network monitoring tool, the graph you would see might look like this:

As you can see, the traffic is very bursty and is often close to line rate. Note that the above is just for conceptual understanding; real-world results may vary. For example, modern NCCL tries to overlap compute and comm, so you may see some “baseline” chatter during the heavy compute sections rather than perfect silence.
This communication pattern is challenging in traditional Ethernet networks using TCP as the transport layer because of how TCP handles congestion. TCP congestion control relies on packet loss. It "probes" the network for congestion signs, and if none are found, it keeps increasing the traffic it sends (known as the congestion window). However, if congestion is detected (through duplicate acknowledgments, retransmissions, etc.), it quickly reduces the traffic it sends. The issue is that when traffic is bursty, as shown above, TCP may overreact to short bursts and reduce the congestion window, limiting network throughput. Another problem with TCP is that it needs a signal from the network to detect congestion, and AIML networks must be lossless. By the time TCP congestion control activates, most of the burst has already been dropped. There are efforts to improve TCP to prevent this behavior, such as DCTCP (RFC 8257), but it’s still not specifically designed for AIML networks.
Elephant Flows
In general-purpose computing, you have a large number of small flows that are usually short-lived. This makes load-balancing those flows using ECMP hash-based forwarding very efficient as it will map each individual flow to a different path, avoiding too many flows saturating a certain path and creating a hotspot as we see in the figure below.

AIML compute, on the other hand, has a few number of very large flows which are long-lived. Because NCCL typically uses the same destination port (4791), there's a risk that ECMP hashing might route multiple large flows through the same network path, creating hotspots. Because of that, all flows in a job will be mapped to the same ECMP path, which has the potential to saturate links and create hotspots as we see in the figure below.

NCCL Tests
Before transitioning a GPU compute cluster to production, infrastructure teams typically run NCCL tests, which is a library designed to validate and benchmark the performance of collective communication across the entire cluster. The NCCL Test executes specific collectives based on the user's choice, for example, all-reduce, and runs them once for each data size. An example of the NCCL Test output is below:
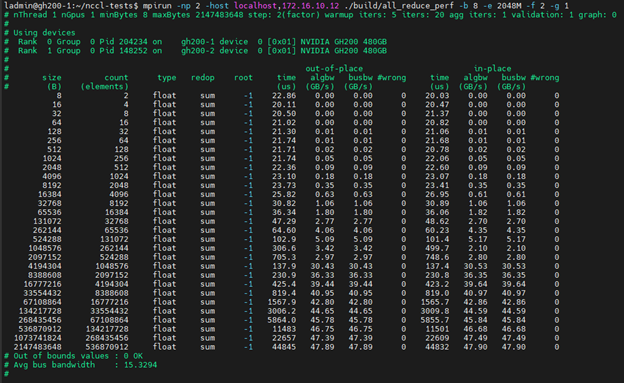
Let’s take some time to decipher what we see in the output above:
Size: The size of the message used to evaluate performance. The larger the size, the more data is being passed around.
Count: The number of elements in that message. For example, if we have 2 counts for 8 Bytes, then each element is 4 Bytes each.
Type: Data type of each element.
Redop: The reduction operation being used. This is when we are doing reduce or all-reduce tests.
Root: Rank of the root node. This is for collectives where the source is one GPU, such as Reduce or Broadcast. In collectives like All-Reduce, which are symmetric, meaning that data is being passed around through all GPUs, we will say -1 as we see above.
The next 6 columns are divided into 2 sections, Out-of-place and In-Place:
Out-of-place requires two device buffers per GPU, a send-buffer and recv-buffer. It will copy the contents of each GPU’s send-buffer to the neighbor's receive buffer, always keeping a copy of the original send buffer, thus keeping the original data intact. This requires two buffers worth of space and has some overhead for the extra write to the receive buffer.
In-place requires only one device buffer and overwrites the buffer at each data exchange with the neighbor. NCCL-Tests runs both modes because they represent two common real-world usage patterns—and their performance can differ. We want the full picture of the performance of all scenarios here.
Here are the 3 out-of-place and in-place columns we see above:
Time: Time it took to complete the collective operation.
Algbw: Now pay attention here, this is where it’s really important for network engineers. Algbw is a simple calculation of time divided by data size, so if you look at the bottom row data size, which is message size (GB) / time (s) = 2.147483648 GB ÷ 0.044848 s ≈ 47.89 GB/s.
Busbw: Algbw is a simplistic calculation that doesn’t take into account the different collective communication patterns. For example, in an all-reduce, the traffic goes once through the ring to accumulate every GPU’s data, and then the data goes through the ring a second time to distribute the result, so the bandwidth effectively goes through the ring 2 times. In large-scale environments with a large number of GPUs, it’s not uncommon to see that the busbw is double the algbw. The above example is only between 2 GPUs, so it does not fully demonstrate this concept.
FAQ
Are same rank GPUs communicating with each other or is it any-to-any communication?
In a multi-node multi-GPU setup, the communication between nodes will often involve GPUs of the same ranks, but it is not exclusively limited to this pattern. The communication strategy depends on the specific collective operation being performed and the optimization chosen by NCCL based on the hardware topology. Here are some examples.
All-Reduce:
Intra-Node Reduction: Each node first performs the reduction operation among its own GPUs.
Inter-Node Reduction: GPUs with the same rank on different nodes then communicate with each other to further reduce the data.
Intra-Node Broadcast: The reduced results are broadcast back to all GPUs within each node.
All-Gather:
Intra-Node Gathering: Each node gathers data from its own GPUs.
Inter-Node Gathering: GPUs with the same rank across nodes gather data from each other.
Intra-Node Distribution: The gathered data is distributed back to all GPUs within each node.
How do we know which optimization is chosen by NCCL and how can we influence it?
NCCL automatically selects the optimal communication strategy based on the hardware topology and the collective operation being performed. To determine the optimizations chosen by NCCL, you can enable debugging and logging via the NCCL_DEBUG environment variable and use profiling tools like NVIDIA Nsight Systems and Nsight Compute. To influence NCCL's optimizations, you can set various environment variables such as NCCL_ALGO, NCCL_PROTO, NCCL_NTHREADS, and more. These settings allow you to customize and optimize NCCL's behavior for your specific hardware and workload.
References
NCCL Reference docs
https://github.com/NVIDIA/nccl-tests
https://network.nvidia.com/sites/default/files/related-docs/solutions/hpc/paperieee_copyright.pdf
https://outshift.cisco.com/blog/training-llms-efficient-gpu-traffic-routing
https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/index.html
https://www.ietf.org/archive/id/draft-yao-tsvwg-cco-problem-statement-and-usecases-00.html
Subscribe to my newsletter
Read articles from adel Iazzag directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by