Grafana Loki 和 Bloom Filter
 雷N
雷N
在系統中,常常會面對一個問題,這資料存在不?這命令剛剛執行過了不?往往我們會把這些結果儲存至資料庫中,並且很可能建立索引(Indexing)或是設定唯一約束(Unique constraint),並免重複資料存在。也可能會在 application 中以 Map 或是 Tree 的資料結構來儲存這些資料,以便提供判斷。
在 Tree 讀取上不會是 O(1),而 Map 在記憶體的空間利用率上也不能用到很極致,都會有些許碎片化的副作用產生。具體細節能參考這篇了解 Go Map。但有些許時刻不是要取得資料元素全部屬性,而是要知曉是否存在而已。這兩者的目的是要儲存資料所設計的,像是快取的需求或是查詢分析的需求。
以網頁爬蟲為例,如果要給 crawler 知道給定的 URL 是否已經訪問過了呢?這時你會怎麼做?我直覺想到以下幾個解決方案︰
把訪問過得 URL 儲存至資料庫,並且設定 Unique。
在 PostgreSQL 與 MySQL,Unique index 都是以 B-Tree 型是在儲存處理。因此判斷是否存在的效率就取決於樹高,新增與查詢都需要判斷是否滿足該約束,所以不會非常快。

在 Application 用 Map 儲存訪問過得 URL。
記憶體利用率不高,會因為 load factor 的設定使得填充率不高,常見的策略是只有用到該 page 的 50% 利用率,如果該 Page 快滿了,會把 Map 的 Bucket 數量翻倍,頗費記憶體資源。

以上兩種覺得有點浪費空間,因此把 URL 透過 MD5 或是 SHA 做hash後在儲存至資料庫或 Map中
建立一個 BitArray 把 URL 經過 hash 印射到該Array的某一個位置
思考一下這 4 個方案,方案1~3都是把訪問過得 URL 完整儲存下來,在資料量來到一億筆時想像一下會發生什麼問題?方案 1 資料庫單表可能已經無法快速查詢需要一些優化手段。方案 2 ,如果每個 URL 長度為 50,在 UTF-8 ASCII 編碼下,每個 URL 約 50 bytes,一億筆需要將近 5GB 的記憶體來儲存。方案 3 透過 MD5 長度只有 128 Bit,SHA-1 約 160 Bit,也需要約 2GB 的記憶體。
而方案4指標記儲存一個 Bit,則一億筆只需要 12.5 MB 的記憶體需求。相較於方案 1~3(需要數 GB 的記憶體),方案 4 的空間效率極高。但因為是 Bit Array 所以有長度的設定,Hash function 也會基於這長度來決定放的位置,但要有有限的長度來存放近似無限的長度,勢必會發生衝突(Conflict,不同 URL 但對應到同一個位置)。如果要降低衝突機率就需要把 Array 長度變成預計儲存元素個數的數倍,以空間換時間的概念,但我們的主軸是節省空間。
加大 Array 長度能降低衝突問題,但會帶來稀疏的利用率問題,本來想要節省記憶體需求,變成沒省到太多。為此 Bloom Filter 的解決方法是使用了多個 hash function。因為單一個 hash function,在資料量逐漸變多時,衝突機率也會隨之變高(這裡稱呼該衝突機率為 p1)。而使用多個 hash function,分別衝突機率就會是 p1、p2、p3 … pn,又因為每個 hash function 彼此是獨立計算的不受到彼此狀態的影響,因此多個hash function 在這bit array 上的衝突機率就會是 p1*p2*…*pn,那就會遠小於 p1 了,用多一些計算使得衝突機率大幅減小,且不用更多的記憶體需求。所以要降低衝突機率有兩種解法,一是增加 array 長度,二是多個 hash function 來定義出該元素的多個位置,這做法就來到 Bloom Filter 的核心。
介紹 Bloom Filter
推薦影片 What are Probabilistic Data Structures: Bloom Filters
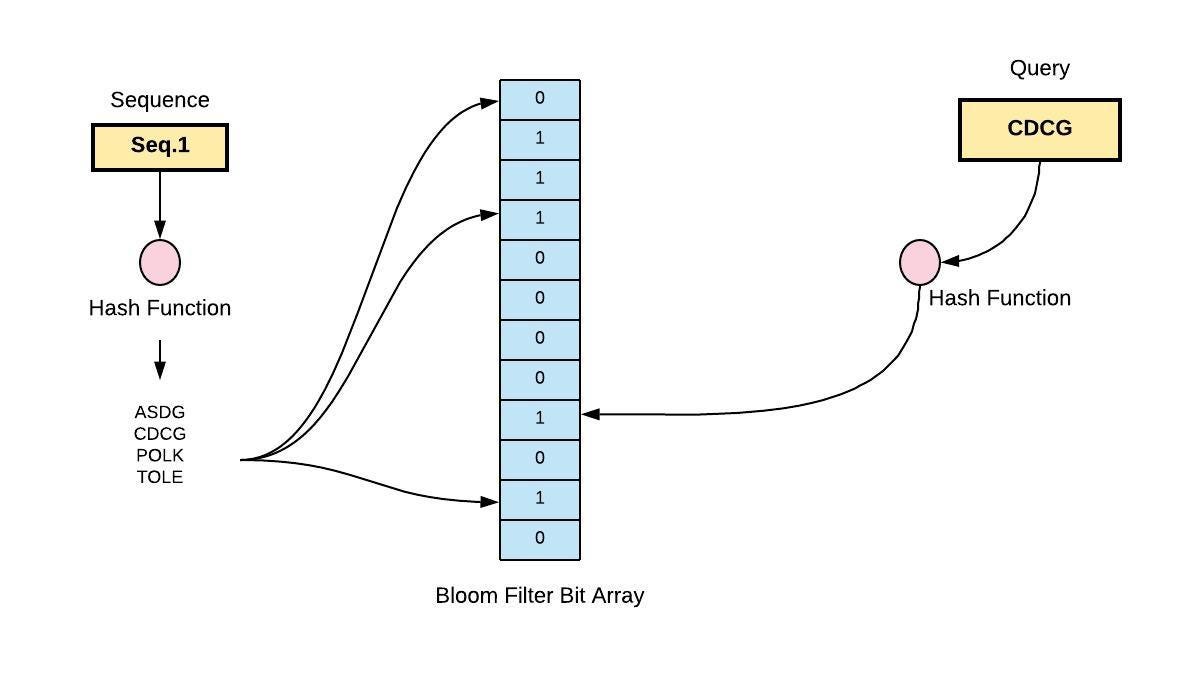
Bloom Filter 的基本概念如下圖,主要想表達的意圖是“我在之前看過這筆資料嗎?”*。因此新增資料時,透過多個 hash function 計算並且把對應的位置標示成 1 。查詢時也是一樣的方法,如果查詢出來有一個位置是0,則代表這資料一定不存在:但如果都是1,也只代表資料可能存在,這樣的性質稱為偽陽性(False Positive Rate 或稱誤判率*)。因為可能資料其實不存在,但剛好其他資料經過 hash 完的結果,把這些位置都標示成1了。
下圖的 maiicious-url.com 經過計算後,把位置2,6,7都標示成1。而查詢 exampl.io 經過計算也剛好是查詢位置2,6,7,查詢結果也全部是1,就以為資料一定存在於資料庫,這就是Bloom filter 的顯著問題偽陽性。
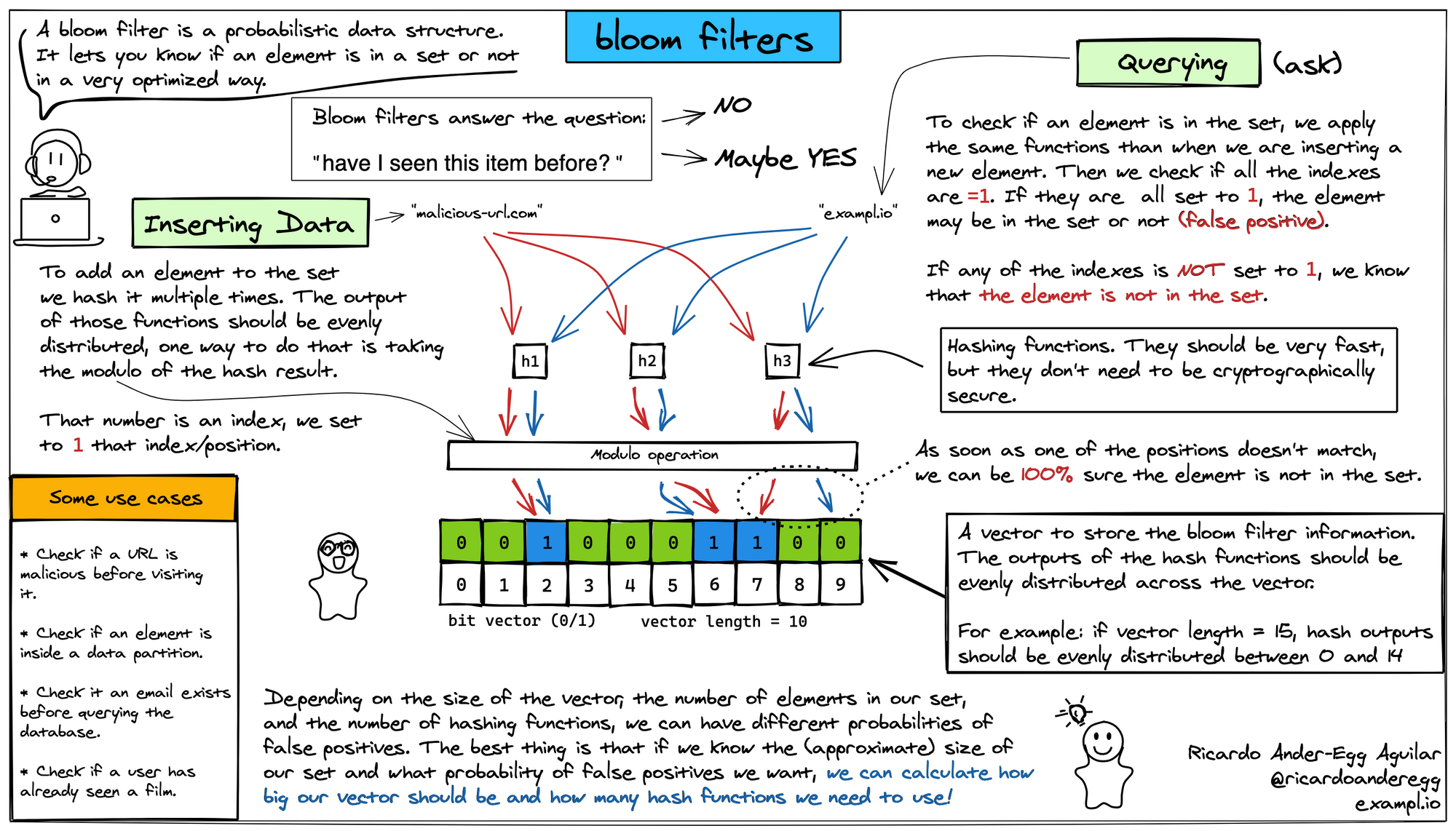
而 Bloom filter 計算的效能與衝突機率,主要還是取決於 hash function 的選擇,所以不太會用 MD5、SHA 這類很慢的 hash 來實作。蠻多會使用 MurmurHash 來實作。Bloom filter
而 Bloom Filter 另一個問題是,不能執行刪除操作。跟偽陽性有關,你刪除的這位置搞不好別的資料也用到。
還有一個問題是 Bloom filter 如果隨著資料越加越多時,應該整個 bit array 幾乎都會是 1 的情況下,那麼偽陽性會提高,導致誤判率會逐漸提高至無法接受的水平。這時我們能考慮把 bit array 給擴容了。而這其實有公式
其中 n 是已經插入的資料數量,m 是 bitarray 長度,k 是hash function 的數量。
到這裡我們也不難知道 Bloom Filter 計算複雜度,新增(Insert)與查詢(Query)操作的時間複雜度均為O(k),其中 k 是使用的 hash function數量。因此,時間成本主要來自 hash 運算的次數,而非資料結構本身的大小。
擴容時,通常會建立一個新的 Bloom filter,並且把原來的長度給倍增後,然後把舊的資料重新插入到新的Bloom filter 中。或者乾脆選擇把 Bloom Filter 給重置。有時系統重新部署或重啟時,也通常會需要把 BF 給重置載入,避免快取穿透問題的發生。
Bloom filter 使用場景跟案例
BF 在某些場景下能解決棘手的問題,從上述描述就清楚在海量資料下,BF 能快速的判斷資料是否可能存在。所以像最早的例子 URL 去重複、重複請求的攔截器,快取穿透問題等。
但這些問題能用BF解決是因為,哪怕查詢後出現了錯誤率,導致任務重複執行或是真的去查詢了資料庫,也不會影響或造成不可預期的危害。
而若資料個數很少(即幾千幾萬筆或是佔用記憶體才幾MB)那麼用 MAP/HashTable解決會更方便。
需求上要是有黑名單做過濾(畢竟不存在於黑名單中的就是好人),推薦系統中已經推薦過的就不推薦,這類的需求。
Redis有提供Bloom Filter 套件,畢竟要快速地去除重複處理,BF 是能用很好的解決方案。
PostgreSQL 也有提供 Bloom Filter 來實作索引類型。因為在資料庫中要確定一筆資料不存在,蠻容易就是掃描全部資料或索引才能確定不存在,但這很費 IO 成本。但 Bloom Filter Index 只能在 WHERE 中用到 =、IN的比較,如果是範圍查詢或模糊查詢都沒辦法,所以使用場景頗受限。但能看見官方文件的說明,儲存空間約BTree 的30%,存取效能更是有十倍以上的差異。也有些資料庫會將 BF 用在 Hash Join 的場景中。
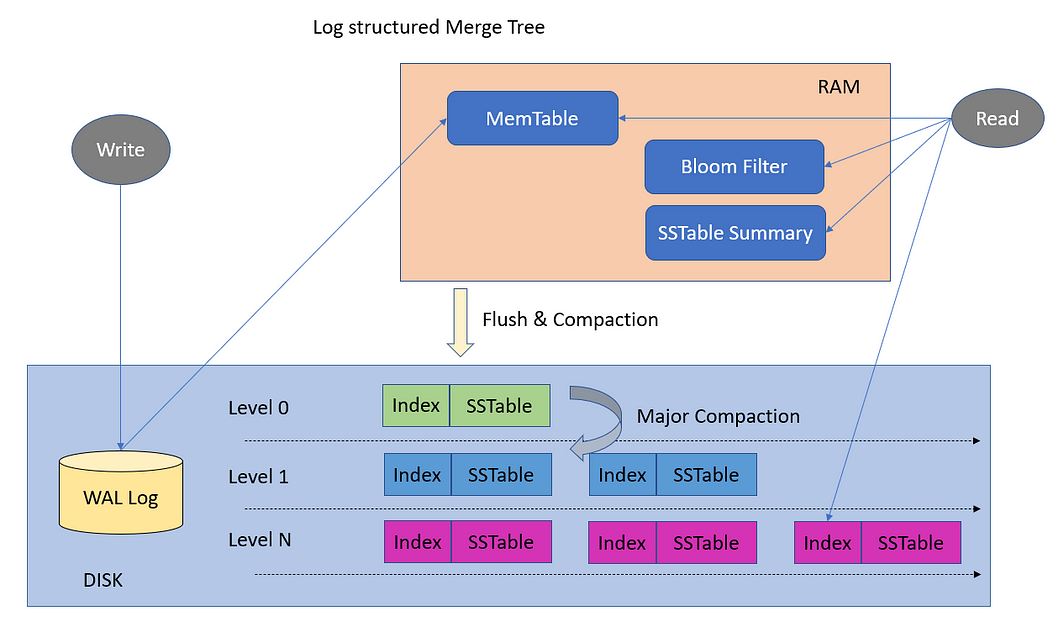
LSM Tree 也會搭配 BF,如果資料不在 MemTable 中,而是在 SSTable 中那就得從硬碟讀取出來了,而 SSTable 有好幾層,每一層又有好幾個 SSTable,要確認讀取的資料在不在這特定的 SSTable 中是需要大量 I/O 讀取出來確認的。而 BF 恰好能協助這 LSM Tree 縮小搜尋範圍。如果 BF 說該資料可能存在於這 SSTable,那就會去讀取並搜索。而若 BF 說該 SSTable 一定沒這資料,則 LSM Tree 就會跳過該 SSTable,繼續檢查下一個。LevelDB 就有用到 Bloom Filter。
關於 BF 要體驗還是透過 PostgreSQL 來讓一張表產生上億萬筆資料,分別用 BTree/Hash 索引和 BF索引來比較儲存空間以及存取空間會比較有感。資料若是不是海量級別,用 BF 幾乎比 MAP 來判定還來的慢,因為多個 hash function 是很需要 CPU time的。
N-grams with Bloom Filter
接著才是來到這篇的重點,會想整理這篇是因為 Grafana Loki 在 3.0 版本引入了 N-grams as Bloom Filter Keys。
N-grams
N-gram 就是從字串中提取連續子字串序列。舉例來說,N grams 的 n 表示長度為 n 的字串組合。
舉例,”hello”,使用 2-grams,就得到子字串序列(即 2-grams)︰”he”、”el”、”ll” 和 “lo”(每個都稱為 2-gram)。使用 3-grams 則會得到”hel”、”ell” 和 “llo”。
透過把一個字串分解成多個 n-gram,在搭配 Bloom Filter,把每個 n-gram 透過 hash function 計算後,印射到 bitarray 的不同位置。新增時就把該位置設置成 1,查詢時,若有任一個 n-gram 對應位置是 0,則該字串不可能存在。透過 n-gram 來判斷一個查詢是否可能存在於資料庫中,因此能提供部份匹配、前綴匹配的能力。也有 Bloom filter 那樣的空間利用率,在海量資料的匹配場景下很有幫助。

但限制也與 BF 一樣,存在著計算誤判率的問題,無法對 BF 進行刪除操作。比較麻煩的是計算成本,因此若資料太少,其實反而不會有太大的吞吐量優勢。
Grafana Loki with N-grams BF
Grafana Loki 的儲存結構與查詢方式對蠻多開發者來說會比較陌生,有一些術語我們要先初步了解。
Series
一筆 log 中Label 與 value 的組合就稱為一個 Series。例子中的 {container="query-frontend",environment="dev"} 就稱為 Series,每個 Seriers 在 Loki 中也都會有唯一 ID 來表示。
Stream 以後深入講 series 時再說了。
{container="query-frontend",environment="dev", pod="travel-api-0"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
Chuck
Series 與 Chunk 之間的關係式一對多,也說是一個 Series 會有多個chunk產生,但一個chunk會被綁訂於一個series上。Chunk 是根據size大小和時間聚合的log區塊。當某個series的log在一定時間後或達到一定大小時,就會作為一個chunk被寫到持久化的儲存服務中。每個Chunk也有唯一 ID 來表示。
Index
Index 的概念熟悉 Elastic 的朋友就應該很熟了。一般的常講的索引是指正向索引,就是從文檔指向某個單詞的映射方向。
文檔1 → [單詞A, 單詞B, 單詞C...]
文檔2 → [單詞B, 單詞D, 單詞E...]
而這裡的索引則是 Inverted Index(倒排索引),從單詞指向文檔的映射。
單詞A → [文檔1]
單詞B → [文檔1, 文檔2]
單詞C → [文檔1]
單詞D → [文檔2]
以剛剛的例子說明,在這 Series 會擁有 3 個 index 指向它,分別是{container="query-frontend"}、 {environment="dev"} 與 `{pod="travel-api-0"}`。
{container="query-frontend",environment="dev", pod="travel-api-0"}
所以當我們查詢 {environment="dev"} 時,Loki 就會去搜尋該index指向的所有 series,然後再根據查詢時間做篩選。
下圖就是 Loki 的 Chunk 與 Index 的簡單表示。能看到只要同樣label組合的就會屬於同一個 Chunk。Chunk 滿了會被壓縮並儲存在 TSDB 或 S3這類的儲存服務中。而 Index 就是用來定位查找 chunk 用的。

所以 Loki 的 Ingester 組件才會有兩個儲存,分別儲存 index 與 chunk。而查詢時,Querier 也需要查詢 Index 與 chunk。
良好的設計規劃下,Index 的儲存大小是會遠小過 chunk 儲存所需的。但如果是高基數的資料可能就反過來了。

產品團隊發現 Loki 在 Grafana Cloud 使用上,發現 7 天總共存取了 280 PB 的log量。在這其中,大約 140 PB 的log最終是根本沒被 filter 給匹配成功。幾乎就是有一半的存取都是浪費的,並沒有搜尋到想要的結果。而就算 index 能匹配到 chunk,但隨後搭配的 filter expression 幾乎使得一百萬筆log,最終只有一筆log完整符合過濾條件。
For example, we recently noticed a funny thing with filter queries: They touch a lot of data they don’t need to. Over a seven-day period, our Grafana Labs prod clusters processed 280 PB of logs. From that total, about 140 PB of the searched logs didn’t match any of the filtering expressions. In other words, 50% of the searched data returned no results! To make things worse, 65% of the processed data (182 PBs) only returned up to one log line for every 1 million logs.
此段數據出自 Grafana Loki query acceleration: How we sped up queries without adding resources
從上述描述不難發現,其實查詢常常miss,如果能很肯定的知道查詢對象肯定不存在於這chunk 中,除了能加速查詢之外,也能使得 Grafana Cloud 的資源有更好的利用率。
所以 Loki 團隊才提出 N-grams BF 來解決這問題。
文章中提到有個 Bloom compactor 會迭代通過一個Series 中的所有日誌內容,並為每行計算 n-grams。對於每個 n-gram,會將其 Hash value 以及 n-gram 加上 chunk ID 的 hash value 添加到 Bloom filter 中。
下圖就是 series id f45h8 和 chunk id aaf67d 以及把 log內容 abcdef,先拆解成多個n-gram,再與chunk id 組合進行hash,並置入 series f45h8 的bloom filter 。

當進行過濾查詢時,也會對查詢條件進行 n-gram 分解,例如,過濾表達式 |= "abcd" 會產生兩個 n-grams: "abc" 和 "bcd"。 這些 n-grams 會與 Bloom filter 進行匹配,如果任何一個 n-gram 匹配成功,則表示該日誌行可能包含查詢的字串。然後,可以進一步通過檢查 n-gram + chunk ID 的 hash value 來確定具體哪些 chunks 可能包含匹配結果。

But! Grafana Loki V3.3 新作法
以上這些作法在 v3.3.0 版本就被捨棄了 (笑) Bloom filter compactor 在 V3.2.0 被捨棄了, V3.3.0 聲明不針對log內容做n-grams bf,而是針對 StructuredMetadata 這在 V3.0.0 新增加的屬性做n-grams bf。我猜不對 log 內容做 n-grams tokenizer 其實也是缺點很明顯,第一 log 長度能到非常長,這不管你設定 3-grams, 4-grams, n-grams 都要跑很久,CPU time 資源吃很重(其中一個 GitHub Issues 在講這個)。其二,分詞出來的 gram 數量超多,bitarray 也蠻容易就滿的了。而且 gram 蠻常時間是暫時存在記憶體中的,等於 log 本身以及 grams 某些時刻共存著,會需要很多記憶體資源(其中一個 GitHub Issues 在講這個)。
所以這種實驗性質的功能還是別太早用在營運環境中。但本質概念不變,待小弟慢慢導讀現在的作法,但可能哪天又被捨棄了。
官方有出一篇 Blog Grafana Loki 3.3 release: faster query results via Blooms for structured metadata。官方說明改變了作法。
With Loki 3.0, we announced Bloom filters, a very promising, experimental feature intended to speed up needle in a haystack queries. Since then, we’ve received great insights from early adopters and learned a lot about running Blooms at a large scale—and the tradeoffs our users were willing to make.
With this in mind, and with the increasing adoption of OpenTelemetry, we adjusted our approach and decided to create Blooms leveraging structured metadata.
至於 StructuredMetadata 等下一篇再深入介紹,簡單定義就是高基數(Cardinality)的標籤資訊,例如 TraceId、SpanId 等。Loki 的 label 建議都是低基數的標籤資訊做組合,但有時就是需要高基數直接定位搜尋,為此v3.3 提供此設計方案,畢竟 Loki 從一開始設計就不是為了做全文檢索用的,要高效檢索需要透過 Selector 盡可能縮小範圍。
雖然捨棄了 N-Grams BF,因為標準的 Bloom Filter,但我們還是有檢索高基數欄位的需求,且為了解決 Bloom Filter 的擴容問題與頗高機率的偽陽性問題,Loki 借助了令兩種變體的 Bloom Filter,Scalable Bloom Filter 和 Partitioned Bloom Filter。
Partitioned Bloom Filter
Partitioned Bloom Filter(分區BF) 是 BF 的一種變體,它將標準 BF 的 bit array 分割成多個相等的分區(partition),每個分區對應一個 Hash function。
一開始把一個 m bit 的 array,分成 k 個等大的分區(i.e. 每個分區的大小是 m/k)。並且選擇 k 個 hash function,每個 function 對應一個分區。

而 Partitioned BF 主要解決標準 Bloom Filter 中 Hash 衝突與 Cache 效率問題。
因為標準 BF 是用 1 個bit array 對上多個 hash function,所以很容易產生不同資料經過不同 hash function 扎堆(衝突)到相同位置上的問題。而分區 BF 每一個分區與 hash function 是 1 on 1 的關係,優化了 hash function 的分佈,因此會減少上述的問題。這樣也能提升 CPU Cache 命中率,改善查詢性能。在 Loki 中用於高效管理和查詢 Structured Metadata,提高查詢準確度與速度。這樣的特性對於 Loki 用來加速 Structure metadata token 的查詢很有幫助。
程式定義能參考 pkg/storage/bloom/v1/filter/partitioned.go 。
Scalable Bloom Filter
Scalable Bloom Filter(可擴充 BF)也是 BF 的一種變體。用來解決標準 Bloom Filter 容量固定與擴容困難問題。能依據元素數量自動增加 Bloom Filter 層級,保持假陽性率在可控範圍。這樣在 Loki 中,當資料量持續增長時,Scalable BF 可以避免整體錯誤率急劇升高,確保查詢效率與準確度。適合用於日誌系統中大量資料的持續寫入。它不是只用一個單一的 Bloom Filter,而是由多個 Partitioned Bloom Filter 層級組成。
程式定義能參考 pkg/storage/bloom/v1/filter/scalable.go 。
為什麼每一層都是 PartitionedBloomFilter?
因為 Scalable Bloom Filter 需要多層 Filter。
Scalable Bloom Filter 的核心思想是︰
當目前的 Bloom Filter 滿了(填充率過高,偽陽性率開始變差),就新增一層新的 Bloom Filter。
每一層的容量和錯誤率都會依照一定比例調整(容量通常變大,錯誤率變低),以控制整體的假陽性率。
而 Loki 選擇使用 Partitioned Bloom Filter 作為基底 filter,因為它在性能和準確度上表現較好。因此,ScalableBloomFilter 的每一層都是一個 PartitionedBloomFilter,這樣就能兼顧擴容能力與高效查詢。就像你有多個「小型高效過濾器」(PartitionedBloomFilter)。當第一個小過濾器滿了,你再加第二個、第三個...。查詢時會問每一個小過濾器,只要有一個說「我有這個元素」,就判定存在。

type ScalableBloomFilter struct {
filters []*PartitionedBloomFilter // 多層分區 Bloom Filter 層,每新增一層,錯誤率逐層降低
r float64 // 錯誤率收緊比例,Loki 預設 0.8
fp float64 // 目標偽陽性率(整體),Loki 預設 0.01
p float64 // 填充比率閾值,用於判斷是否擴容
hint uint // 初始 filter 的空間大小,Loki 預設 1024
s uint // 新增 filter 的空間成長擴充因子
additionsSinceFillRatioCheck uint // 自上次檢查填充比率後新增的元素數量
}
擴容條件(何時擴容)
Scalable Bloom Filter 會根據目前儲存的元素數量與目標假陽性率來判斷是否需要擴容,主要條件是:
當目前的 Bloom Filter 已經接近或達到其最大容量(最大元素數量)時,即插入的元素數量接近該層 Bloom Filter 設計的容量限制。
假陽性率達到預設的閾值,即當假陽性率開始超出設定目標時,需要擴容以降低錯誤率。
簡單說,就是當目前使用的 Bloom Filter 已經「滿載」,無法保證目標的假陽性率時,就會觸發擴容。
擴容方式(如何擴容)
Scalable Bloom Filter 採用 多層 Bloom Filter 組合 的方式擴容:
初始時建立一個 Bloom Filter,設定一定的容量和假陽性率。
當該 Bloom Filter 滿了(元素數量達到容量),不會擴大這個 Bloom Filter 本身,而是 新增一個新的 Bloom Filter 層。
當該 Bloom Filter 滿了(元素數量達到容量),不會擴大這個 Bloom Filter 本身,而是 新增一個新的 Bloom Filter 層。
容量會比前一層大(例如乘以一個擴展因子,常見是 2 倍)。
假陽性率會比前一層更嚴格(更低),通常是前一層的一定比例(例如降低一半)。
插入新元素時,會加入到最新(最頂層)的 Bloom Filter。
查詢時,會依序在所有的 Bloom Filter 層中查詢,任一層存在就回傳存在。
新增資料具體流程示意
第一層 Bloom Filter:容量 n,假陽性率 p
當第一層滿了,新增第二層 Bloom Filter:
容量 n×r(r 是擴展因子,如 2)
假陽性率 p×sp×s(s 是縮小比例,如 0.5)
插入元素只加入第二層
查詢時從第一層到第二層依序查詢
graph TD
A[開始:將元素加入 Scalable Bloom Filter] --> B{是否已存在任何 PartitionedBloomFilter?}
B -- 否 --> C[建立第一個 PartitionedBloomFilter 層]
C --> D[將元素加入新的PartitionedBloomFilter中]
D --> End
B -- 是 --> E[取得最新一層的PartitionedBloomFilter]
E --> F[計算頂層PartitionedBloomFilter的估計填充率]
F --> G{估計填充率 >= 閾值 p?}
G -- 否 --> H[將元素加入新一層的 PartitionedBloomFilter]
H --> I[遞增 additionsSinceFillRatioCheck 計數]
I --> End
G -- 是 --> J{自上次檢查後的添加次數 >= 閾值?}
J -- 否 --> H
J -- 是 --> K[重設 additionsSinceFillRatioCheck 計數]
K --> L[更新計數以取得實際填充率]
L --> M{實際填充率 >= 閾值 p?}
M -- 否 --> H
M -- 是 --> N[計算下一層 PartitionedBloomFilter 的容量]
N --> O{超過最大大小限制?}
O -- 是 --> P[返回 full = true,不添加新的 PartitionedBloomFilter]
P --> End
O -- 否 --> Q[添加新的 PartitionedBloomFilter]
Q --> H
End((結束))
查詢資料具體流程示意
查詢時,Scalable Bloom Filter 會從最早建立的第一層開始,依序查詢每一層的 Partitioned Bloom Filter。
如果任一層回傳存在(Test 返回 true),則整體回傳存在。
若所有層都沒有找到元素,則回傳不存在。
這樣設計確保查詢結果的準確性,因為新加入的元素一定在最新層,而舊元素可能存在於較早的層中。
graph TD
A[開始:在 Scalable Bloom Filter 中查詢元素] --> B{是否存在任何PartitionedBloomFilter?}
B -- 否 --> C[返回 false,不存在]
C --> End
B -- 是 --> D[依序檢查每個 PartitionedBloomFilter,從最舊到最新]
D --> E[在當前 PartitionedBloomFilter 中 Test 元素]
E --> F{元素是否存在於此層?}
F -- 是 --> G[返回 true,可能存在]
G --> End
F -- 否 --> H{還有更多 PartitionedBloomFilter 需要檢查嗎?}
H -- 是 --> D
H -- 否 --> I[返回 false,不存在]
I --> End
End((結束))
下面程式碼是新增元素的段落中,能看見一個與理論說明時不太一樣的點。正常來說每一層要用不一樣的hash function,但這裡顯然每一層都是同樣的 hash function p.SetHash(s.filters[0].hash)。
func (s *ScalableBloomFilter) addFilter() {
fpRate := s.fp * math.Pow(s.r, float64(len(s.filters)))
var p *PartitionedBloomFilter
// 第一個 bloom filter 使用 hint 的大小來建立
// 後續的 bf 根據前一個 bf 的容量以及空間成長擴充因子來確定大小
if len(s.filters) == 0 {
p = NewPartitionedBloomFilter(s.hint, fpRate)
} else {
p = NewPartitionedBloomFilterWithCapacity(s.filters[len(s.filters)-1].Capacity()*s.s, fpRate)
}
if len(s.filters) > 0 {
p.SetHash(s.filters[0].hash)
}
s.filters = append(s.filters, p)
s.additionsSinceFillRatioCheck = 0
}
那怎麼模擬 k 個 hash 函數呢?
這裡使用的是 double hashing 或 hash kernel 方法。
hashKernel 這個函式用來從單一的 hash function(hash.Hash64)產生兩個獨立的 32-bit hash 值:upper 和 lower。它先用 hash.Write(data) 對輸入資料做 hash,得到一個 64-bit 的 hash 值 sum。接著將 sum 的高 32 bits 當作 lower,低 32 bits 當作 upper。
在 Test 與 Add 函式中:hashKernel 會透過同一個 hash function 產生兩個不同的 hash 值(lower 和 upper),然後利用公式 (lower + upper * i) mod s 產生第 i 個 hash 函數的輸出。
// 透過 hashKernel 取得 lower 和 upper 值
lower, upper := hashKernel(data, p.hash)
// 對每個 partition i 用 (lower + upper * i) % s 來計算 bit 位置
for i := uint(0); i < p.k; i++ {
idx := (uint(lower) + uint(upper)*i) % p.s
// 使用 idx 操作第 i 個 partition
}
func hashKernel(data []byte, hash hash.Hash64) (uint32, uint32) {
hash.Write(data)
sum := hash.Sum64()
hash.Reset()
upper := uint32(sum & 0xffffffff)
lower := uint32((sum >> 32) & 0xffffffff)
return upper, lower
}
這樣做的好處很多︰
節省資源:不用為每個 hash 函數維護一個獨立的 hash function 實例,只要一個 hash function 產生兩個值,再用線性組合產生多個 hash 值。
效率:這種 double hashing 技術被證明能模擬多個獨立 hash 函數,且效果很好。只呼叫一次 hash 函式,節省計算成本。
Loki 對於 StructureMetadata 的查詢與加入
AST 抽象語法樹
要查詢 Loki 需要通過 LogQL 的語法來執行資料搜索,以前小弟有寫過文章能參考。在 stream selector 後,可以使用 structure metadata 來進行篩選。例如︰
以 pod 作為 structure metadata 來篩選 {job="example"} | pod="myservice-abc1234-56789" 或是多個欄位做篩選 {job="example"} | pod="myservice-abc1234-56789" | trace_id="0242ac120002"。
專案中 pkg/storage/bloom/v1/ast_extractor.go 就是負責從 LogQL 表達式中提取可測試的標籤匹配器。Loki 收到 LogQL 後,會使用 Loki 的 label index 系統(非 Bloom 過濾器)快速定位符合條件的 log series。然後對該 series 底下所有的 chunks 進行 Bloom filter 的測試(Test),如果 Bloom filter 顯示 chunk 可能包含所需的值(例如 pod="myservice-abc1234-56789"),則進一步處理該 chunk。如果 Bloom filter 明確表示 chunk 不可能包含所需值,則直接跳過該 chunk。
這也就是為什麼 Loki 在處理 Structure metadata 能依舊保持高效的原因,因為這種多層次的過濾機制非常有用,尤其是當處理大規模日誌數據時:
Label Index縮小了需要查詢的 Log series 範圍
Bloom Bloom filter進一步縮小了需要讀取的 chunk 範圍 只有真正需要的 chunk 才會被完整讀取和處理。因為 chunk 數量非常的多,要每一個都下載回來檢查會很耗時且浪費資源。
此外透過 pkg/storage/bloom/v1/ast_extractor_test.go, 會發驗查詢方法不只是能精準查詢,也能模糊查詢(但只滿足前綴匹配)。像是以下用法,這些官網沒怎提,但測試程式倒是寫得很清楚。
{job="example"} | pod="myservice-abc1234-56789" | trace_id="0242ac120002"
{job="example"} | user_id="nathan" or user_id="雷N"
{job="example"} | user_id="nathan" and action="addToCart"
{job="example"} | pod=!"myservice-abc[0-9]"
Distributer 接收 Log data
Loki 收到 log data 時,會由 Distributer 組件來處理 log ,客戶端如果有需要附加上自己需要的 StructuredMetadata 就能自己附加在 log 中,如下的 trace_id 與 user_id,這些高基數資訊,就能透過 StructuredMetadata 的形式來描述。能參考官方網站的 Ingest logs 。
"values": [
[ "<unix epoch in nanoseconds>", "<log line>", {"trace_id": "0242ac120002", "user_id": "superUser123"}]
]
當 Loki 從 /loki/api/v1/push API 接收到 log ,將 StructuredMetadata 填入 Bloom bf 的流程涉及多個組件。以下是完整處理流程:
日誌接收與解析
主要負責解析處理 API 請求的是 pkg/push 目錄下的模組。當 HTTP POST 請求到達 /loki/api/v1/push 端點時:
接收 Request 並根據
Content-Type決定如何解碼對於 Snappy 壓縮的 Protocol Buffer 消息 或 gzip 壓縮的 JSON
將壓縮數據展開,並解析成
PushRequest結構,被定義在 push.pb.go 與 types.go 中,定義如下:type PushRequest struct { Streams []Stream `protobuf:"bytes,1,rep,name=streams,proto3" json:"streams"` } // Stream contains a unique labels set as a string and a set of entries for it. type Stream struct { Labels string `protobuf:"bytes,1,opt,name=labels,proto3" json:"labels"` Entries []Entry `protobuf:"bytes,2,rep,name=entries,proto3,customtype=EntryAdapter" json:"entries"` Hash uint64 `protobuf:"varint,3,opt,name=hash,proto3" json:"-"` } // Entry is a log entry with a timestamp. type Entry struct { Timestamp time.Time `protobuf:"bytes,1,opt,name=timestamp,proto3,stdtime" json:"ts"` Line string `protobuf:"bytes,2,opt,name=line,proto3" json:"line"` StructuredMetadata LabelsAdapter `protobuf:"bytes,3,opt,name=structuredMetadata,proto3" json:"structuredMetadata,omitempty"` Parsed LabelsAdapter `protobuf:"bytes,4,opt,name=parsed,proto3" json:"parsed,omitempty"` }
剛剛的例子,當 distributer 解析該 entry 時, [ "<unix epoch in nanoseconds>", "<log line>", {"trace_id": "0242ac120002", "user_id": "superUser123"}]。會把第一個元素解析為 Timestamp, 第二個元素解析為 Line… 第三個元素(JSON 對象)解析為 StructuredMetadata,並轉換為 LabelAdapter 格式。
這樣解碼過得 log 會轉變成這樣的形式轉交給 Loki 令一個組件 Ingester 接收並處理。它會
將 log entry 添加到記憶體中的區塊(MemChunk)
當區塊達到特定大小或時間限制時,啟動 flush 過程
在 flush 過程中,調用 BloomTokenizer 處理區塊中的 StructuredMetadata
此時 BloomTokenizer.go 是負責用來填充給定的 Bloom 過濾器, BloomTokenizer.addChunkToBloom() 方法會:
創建 StructuredMetadataTokenizer 實例
遍歷每個 log entry 的StructuredMetadata
產生相應的 tokens
將這些 tokens 添加到 Bloom 過濾器中
這樣 Ingester 中的每個 series 的 bloom filter 就會慢慢填充進資料來提供查詢的能力了。
總結
Bloom Filter 是一種在資料儲存服務常見的元件設計,有諸多變體的設計,但大致概念都差不多。主要是用少量的記憶體資源來儲存資料的一部分,用來篩選不存在資料的查詢極為高效,能少掉很多浪費讀取 I/O 的成本。已經有蠻多資料庫都內建這樣的機制在決策要不要對該區塊進行磁碟讀取,像是 LevelDB、PostgreSQL、PolarDB 等,還有今天介紹的 Loki 與 Grafana Tempo 也是這樣的。
但 Loki 的 Bloom Filter 功能目前我還不推薦用在營運環境中,因為很可能 Loki 團隊還會在更改作法。我覺得更猛的是 FluentBit,新版本 4.0 版本的 Loki Output 組件已經支援 StructuredMetadata。確實 Loki 肯定要具備 StructuredMetadata 這種高基數欄位的查詢能力,不然查詢效率會很低。後面有機會再將這塊整合起來 Demo。
附上 Go 實踐 Bloom Filter 的版本。本來以 murmurhash 實做但遠比 Map 操作慢的多,因為 k 個murmurhash 實在不算快。看過 Go map 設計的話,也會發現它們的 hash 函數也是設計的非常高效。Grafana Loki 的 hashKernel 也是差不多的概念設計出來的。看開源專案就是能偷學到這些 XD
bloom.go
package bloomfilter
import (
"hash"
"hash/fnv"
)
// A simple Bloom Filter implementation
type BloomFilter struct {
bitArray []uint64
size uint
hashFuncs int
h hash.Hash64
}
// Create a new Bloom Filter
func NewBloomFilter(size uint, hashFuncs int) *BloomFilter {
// Calculate how many uint64s are needed to store all bits
arraySize := (size + 63) / 64
return &BloomFilter{
bitArray: make([]uint64, arraySize),
size: size,
hashFuncs: hashFuncs,
h: getNewHashFunction(),
}
}
// Add data to the Bloom Filter
func (bf *BloomFilter) Add(data []byte) {
lower, upper := bf.hashKernel(data, bf.h)
for i := 0; i < bf.hashFuncs; i++ {
index := (uint64(lower) + uint64(upper)*uint64(i)) % uint64(bf.size)
bf.bitArray[index/64] |= 1 << (index % 64)
}
}
func getNewHashFunction() hash.Hash64 {
return fnv.New64()
}
// Check if data possibly exists in the Bloom Filter
func (bf *BloomFilter) Contains(data []byte) bool {
lower, upper := bf.hashKernel(data, bf.h)
for i := 0; i < bf.hashFuncs; i++ {
index := (uint64(lower) + uint64(upper)*uint64(i)) % uint64(bf.size)
if (bf.bitArray[index/64] & (1 << (index % 64))) == 0 {
return false
}
}
return true
}
// hashKernel returns the upper and lower base hash values from which the k
// hashes are derived.
func (bf *BloomFilter) hashKernel(data []byte, hash hash.Hash64) (uint32, uint32) {
hash.Write(data)
sum := hash.Sum64()
hash.Reset()
upper := uint32(sum & 0xffffffff)
lower := uint32((sum >> 32) & 0xffffffff)
return upper, lower
}
bloom_test.go
package bloomfilter
import (
"encoding/json"
"fmt"
"math/rand"
"runtime"
"strings"
"testing"
"time"
"github.com/google/uuid"
)
type UserInfo struct {
ID uuid.UUID
Name string
EMail string
Address string
}
// Generate random English name (5-20 characters)
func generateRandomName() string {
alphabet := "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
length := rand.Intn(16) + 5
var sb strings.Builder
for i := 0; i < length; i++ {
sb.WriteByte(alphabet[rand.Intn(len(alphabet))])
}
return sb.String()
}
// Generate random UserInfo data
func generateRandomUserInfo() UserInfo {
name := generateRandomName()
// Random email domain suffixes
domains := []string{"gmail.com", "yahoo.com", "hotmail.com", "outlook.com", "example.com"}
// Random addresses
streets := []string{"Main St", "Park Ave", "Broadway", "5th Ave", "Oak St", "Pine St", "Maple Ave", "Cedar Ln"}
cities := []string{"New York", "Los Angeles", "Chicago", "Houston", "Phoenix", "Philadelphia", "San Antonio", "San Diego"}
states := []string{"NY", "CA", "TX", "FL", "IL", "PA", "OH", "GA"}
id := uuid.New()
return UserInfo{
ID: id,
Name: name,
EMail: fmt.Sprintf("%s.%d@%s", strings.ToLower(name), id, domains[rand.Intn(len(domains))]),
Address: fmt.Sprintf("%d %s, %s, %s %d", rand.Intn(1000)+1, streets[rand.Intn(len(streets))], cities[rand.Intn(len(cities))], states[rand.Intn(len(states))], 10000+rand.Intn(90000)),
}
}
// Serialize UserInfo to []byte for adding to BloomFilter
func serializeUserInfo(user UserInfo) []byte {
data, err := json.Marshal(user)
if err != nil {
panic(err)
}
return data
}
// Test Add and Contains functionality - using UserInfo
func TestBloomFilterBasic(t *testing.T) {
bf := NewBloomFilter(1000, 4)
// Create UserInfo for testing
user1 := UserInfo{ID: uuid.New(), Name: "JohnDoe", EMail: "john.doe@example.com", Address: "123 Main St, New York"}
user2 := UserInfo{ID: uuid.New(), Name: "JaneSmith", EMail: "jane.smith@example.com", Address: "456 Park Ave, Los Angeles"}
// Serialize and add to BloomFilter
bf.Add(serializeUserInfo(user1))
bf.Add(serializeUserInfo(user2))
// Test existing users
if !bf.Contains(serializeUserInfo(user1)) {
t.Error("BloomFilter should contain user1")
}
// Test non-existing users
user3 := UserInfo{ID: uuid.New(), Name: "BobJohnson", EMail: "bob.johnson@example.com", Address: "789 Broadway, Chicago"}
if bf.Contains(serializeUserInfo(user3)) {
t.Error("BloomFilter should not contain user3")
}
}
// Benchmark comparison with traditional Map - using UserInfo
func BenchmarkMapAdd(b *testing.B) {
m := make(map[uuid.UUID]UserInfo)
b.ResetTimer()
for i := 0; i < b.N; i++ {
user := generateRandomUserInfo()
m[user.ID] = user
}
}
func BenchmarkBloomFilterAdd(b *testing.B) {
bf := NewBloomFilter(uint(b.N*10), 3)
b.ResetTimer()
for i := 0; i < b.N; i++ {
user := generateRandomUserInfo()
idBytes := []byte(fmt.Sprintf("%d", user.ID))
bf.Add(idBytes)
}
}
// Search performance test - using UserInfo
func BenchmarkMapContains(b *testing.B) {
const dataSize = 1000000 // One million data entries
// Preset
m := make(map[uuid.UUID]UserInfo)
for i := 0; i < dataSize; i++ {
user := generateRandomUserInfo()
m[user.ID] = user
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
searchID := uuid.New()
_, found := m[searchID]
_ = found
}
}
func BenchmarkBloomFilterContains(b *testing.B) {
const dataSize = 1000000 // One million data entries
// Preset - complete before timing
bf := NewBloomFilter(100000000, 3) // Increase filter size based on data volume
serialized := make([][]byte, dataSize)
// Generate all users and serialize data in advance
for i := 0; i < dataSize; i++ {
user := generateRandomUserInfo()
serialized[i] = serializeUserInfo(user)
bf.Add(serialized[i])
}
b.ResetTimer() // Start timing
// Use pre-generated serialized data for queries
for i := 0; i < b.N; i++ {
bf.Contains(serialized[i%dataSize])
}
}
func TestMemoryComparison(t *testing.T) {
var m runtime.MemStats
const count = 1000000 // One million data entries
start := time.Now() // Add total test start time
// Measure Map memory
runtime.GC() // Clean up garbage first for more accurate baseline
runtime.ReadMemStats(&m)
beforeMap := m.Alloc
// Create and fill Map
mapStart := time.Now() // Map test start time
dataMap := make(map[uuid.UUID]UserInfo)
usersList := make([]UserInfo, count)
// Generate users and add to Map
for i := 0; i < count; i++ {
user := generateRandomUserInfo()
usersList[i] = user
dataMap[user.ID] = user
}
mapCreationTime := time.Since(mapStart) // Map creation time
runtime.GC()
runtime.ReadMemStats(&m)
afterMap := m.Alloc
mapSize := int64(0)
if afterMap > beforeMap {
mapSize = int64(afterMap - beforeMap)
} else {
// If memory decreases, report a small positive number
mapSize = 1024 // Just a nominal value
}
// Test Map query time
mapQueryStart := time.Now()
hits := 0
for i := 0; i < 1000000; i++ {
// Query using the IDs we've already added, rather than generating new ones
index := i % count
searchID := usersList[index].ID
_, found := dataMap[searchID]
if found {
hits++
}
}
mapQueryTime := time.Since(mapQueryStart)
// Clear Map references for garbage collection
dataMap = nil
// Measure BloomFilter memory
runtime.GC()
runtime.ReadMemStats(&m)
beforeBF := m.Alloc
// Create and fill BloomFilter
bfStart := time.Now() // BloomFilter test start time
bf := NewBloomFilter(100000000, 3)
// Serialize all users and add to BloomFilter
serializedUsers := make([][]byte, count)
for i := 0; i < count; i++ {
// Save ID byte slices for subsequent queries
serializedUsers[i] = usersList[i].ID[:]
bf.Add(serializedUsers[i])
}
bfCreationTime := time.Since(bfStart) // BloomFilter creation time
runtime.GC()
runtime.ReadMemStats(&m)
afterBF := m.Alloc
bfSize := int64(0)
if afterBF > beforeBF {
bfSize = int64(afterBF - beforeBF)
} else {
// If memory decreases, report a small positive number
bfSize = 1024 // Just a nominal value
}
// Test BloomFilter query time
bfQueryStart := time.Now()
bfHits := 0
for i := 0; i < 1000000; i++ {
index := i % count
if bf.Contains(serializedUsers[index]) {
bfHits++
}
}
bfQueryTime := time.Since(bfQueryStart)
// Total test time
totalTime := time.Since(start)
// Output results
t.Logf("========== UserInfo Object Memory Usage Comparison ==========")
t.Logf("Map size (storing %d UserInfo objects): %d bytes (%.2f MB)", count, mapSize, float64(mapSize)/(1024*1024))
t.Logf("BloomFilter size (storing %d UserInfo objects): %d bytes (%.2f MB)", count, bfSize, float64(bfSize)/(1024*1024))
t.Logf("Memory saved using BloomFilter: %.2f%%", 100.0*(1.0-float64(bfSize)/float64(mapSize)))
t.Logf("\n========== Creation Time Comparison ==========")
t.Logf("Map creation time: %v", mapCreationTime)
t.Logf("BloomFilter creation time: %v", bfCreationTime)
t.Logf("BloomFilter creation speed ratio: %.2f times", float64(mapCreationTime)/float64(bfCreationTime))
t.Logf("\n========== Query Time Comparison ==========")
t.Logf("Map query time for %d queries: %v (average per query: %v)", 1000000, mapQueryTime, mapQueryTime/1000000)
t.Logf("BloomFilter query time for %d queries: %v (average per query: %v)", 1000000, bfQueryTime, bfQueryTime/1000000)
t.Logf("BloomFilter query speed ratio: %.2f times", float64(mapQueryTime)/float64(bfQueryTime))
t.Logf("\n========== Summary ==========")
t.Logf("Total test time: %v", totalTime)
t.Logf("Map hits: %d (should be %d)", hits, count)
t.Logf("BloomFilter hits: %d (should be %d)", bfHits, count)
t.Logf("Note: BloomFilter may have false positives, but will not have false negatives")
}
執行 benchmark 測試,結果如下。能發現新增資料確實會慢快一倍,畢竟多了 hash function 要計算。但篩選不存在的話效率可高多了,且這測試案例還跟 I/O 或網路無關,要是資料是放在外部需要存取的話,會很有感。
ps 我是 go version go1.24.1 linux/amd64,map已經是 swiss table的版本。
go test -bench=. -benchmem -memprofile=mem.prof -cpuprofile=cpu.prof .
goos: linux
goarch: amd64
pkg: bloom_filter_demo
cpu: AMD Ryzen 5 3600 6-Core Processor
BenchmarkMapAdd-12 291804 3847 ns/op 615 B/op 13 allocs/op
BenchmarkBloomFilterAdd-12 177907 7073 ns/op 443 B/op 16 allocs/op
BenchmarkMapContains-12 1834726 651.4 ns/op 16 B/op 1 allocs/op
BenchmarkBloomFilterContains-12 3347508 309.7 ns/op 0 B/o 0 allocs/op
Subscribe to my newsletter
Read articles from 雷N directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by