Let’s Decode How Large Language Models Work
 Rishikesh K V
Rishikesh K VEver wondered how AI systems like ChatGPT actually understand language gives results that blow you up from stories, poems to even code completion?. In this article, I will be giving you an idea on how the LLM’s actually churns out human-like text on our prompt and what is actually happening behind the scenes.
“Attention Is All You Need“- The paper that brought life to todays LLM
One of the most influential works in the development of modern LLMs is the “Attention Is All You Need” paper introduced in 2017. This groundbreaking research introduced the Transformer architecture, which revolutionized natural language processing.
So what exactly is Transformer?
Transformers are a type of neural network architecture that has revolutionized Natural Language Processing (NLP). Unlike older models that processed words sequentially (one after another), Transformers can process words in parallel, making them much faster and better at understanding long-range dependencies in text.
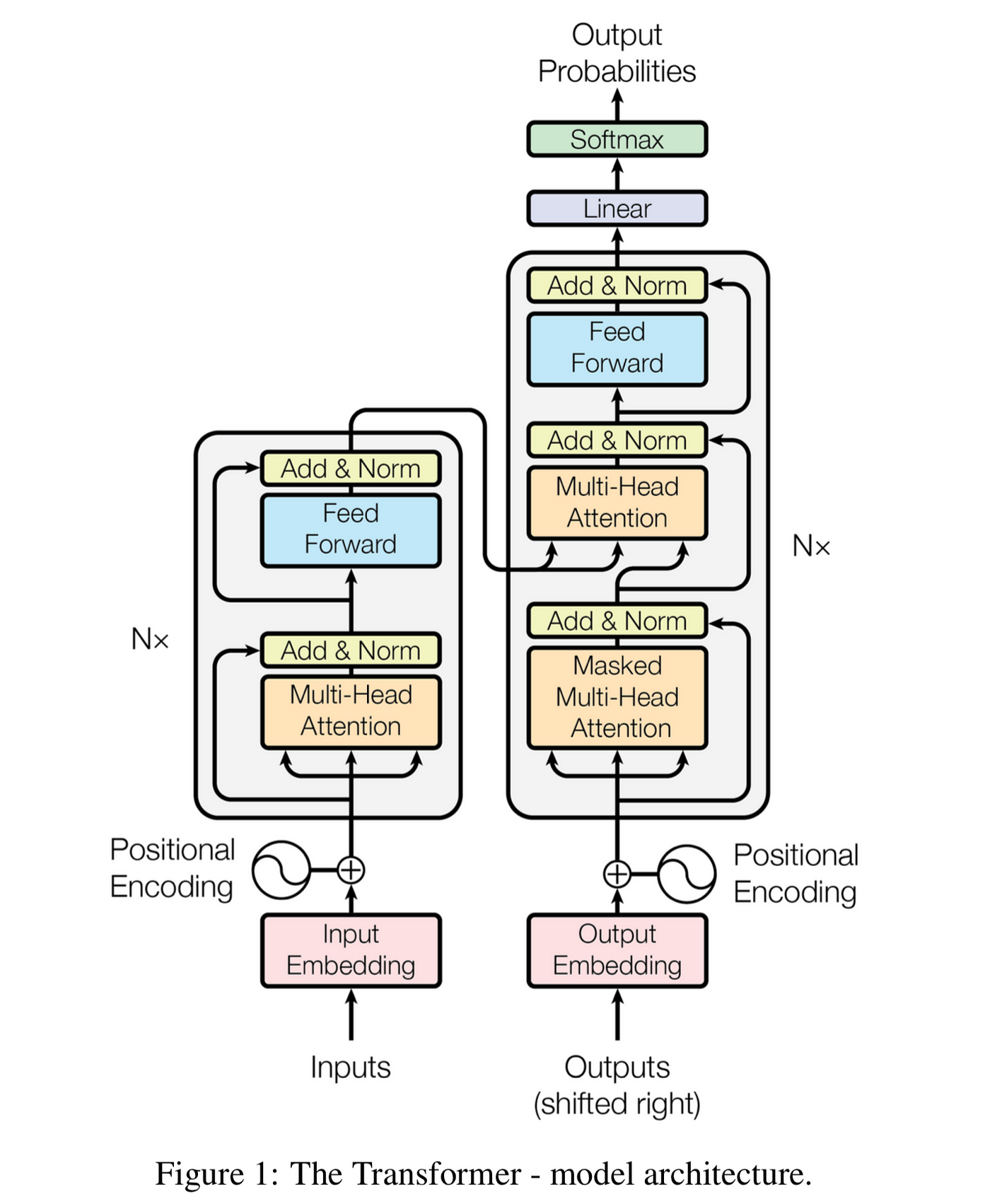
They typically consist of two main parts: an Encoder and a Decoder.
Encoder & Decoder
Encoder: Reads the input text (e.g., a sentence to be translated) and builds a rich numerical representation that captures its meaning.
Decoder: Takes the Encoder's output and generates the target text (e.g., the translated sentence), one word at a time.
But how does the text we prompt to this LLM get processed?
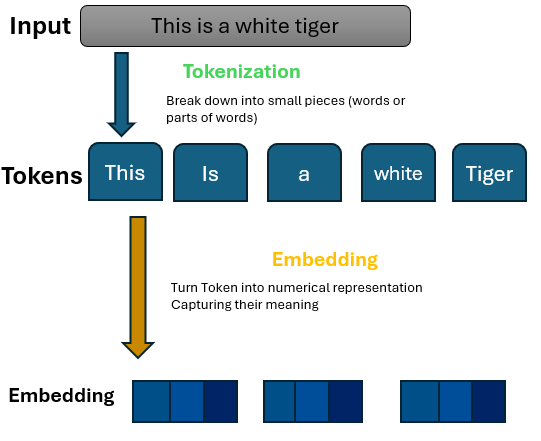
Tokenization: Breaking down into tokens
Imagine you’re cutting a big pizza into slices so it’s easier to share and eat. Similarly the prompt you give to the LLM is broken down into tokens.These can be words, parts of words (subwords), or characters.
Image below represent how tokeniztion is performed in gpt models, have a play around with it openai tokenizer

Vectors & Embedding : The Number Game
Computer understands numbers, not words.So once the LLM has the token, it converts the token to numbers which can be represented in a graph(vectors).This process is called embedding. These aren't just random numbers; embedding are learned such that tokens with similar meanings have mathematically similar vectors. This helps the model capture semantic meaning.
Positional Encoding: Knowing the Order!
Words like “The dog bit the man” vs. “The man bit the dog” have the same words, but different meaning because of word order.
Since Transformers process words in parallel, they lose the original order information. To fix this, they add another vector called Positional Encoding to each token's embedding. This vector provides information about the token's position in the sequence.
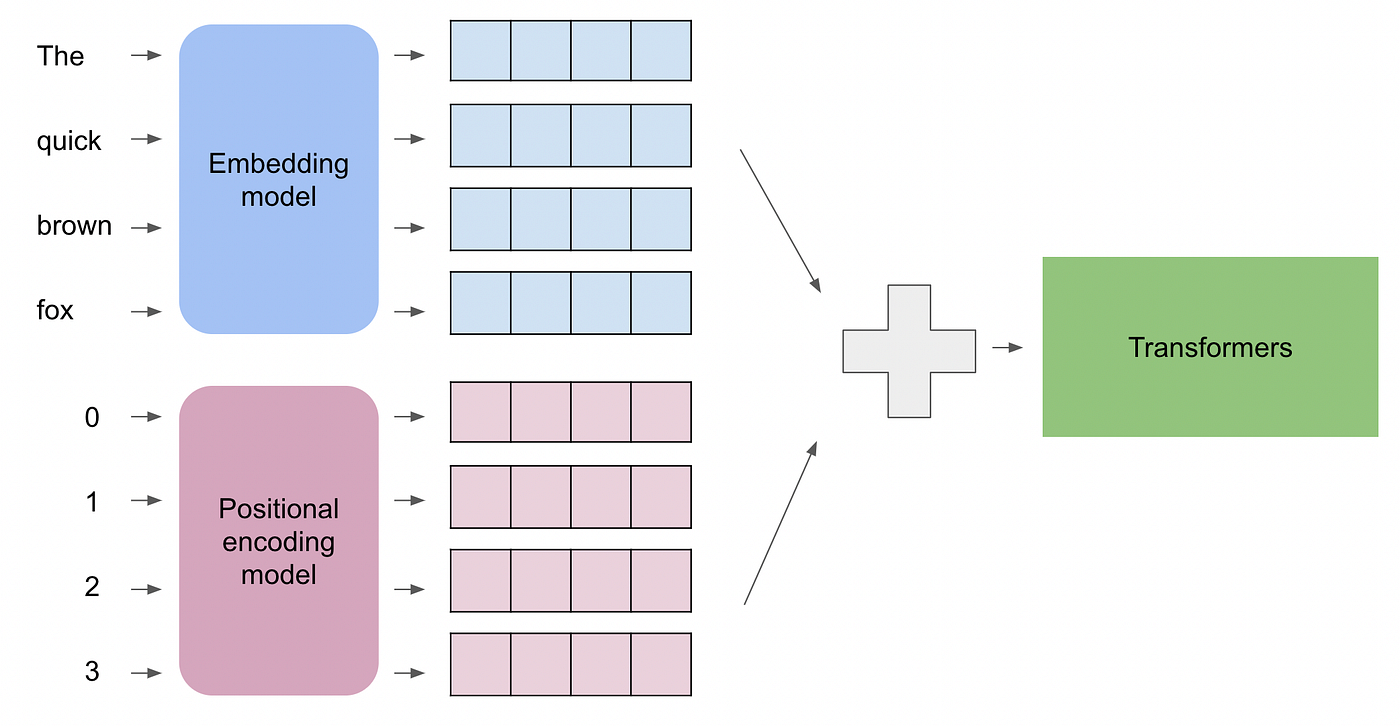
Here we have embedding model for vector representation (blue rectangle) and Positional encoder producing a unique vector for each position (pink rectangles). The size of the positional encoding vectors matches that of the word embeddings, allowing them to be combined md send them to Transformers
Transformers
Attention :The Model’s Superpower
Attention is the core idea that transformed how models understand language.Instead of processing words one at a time (like older models), Single-head Attention lets the model look at the entire sentence at once and decide which words are important when understanding a specific word.
For example, in "The animal didn't cross the street because it was too tired", self-attention helps the model understand that "it" refers to "animal", not "street".
Multi-Head Attention is simply running the attention mechanism multiple times in parallel with different learned perspectives. This allows the model to capture various types of relationships (e.g., subject-verb, adjective-noun) simultaneously.
Softmax : Turning Scores into Probabilities
Once the model has figured out which word to generate next, it ends up with raw scores (called logits) for every word in the vocabulary.
Enter Softmax — a function that takes these scores and turns them into probabilities.
Imagine the model is choosing the next word and assigns these logits:
apple: 4.2,banana: 2.1,car: -1.5
Softmax will convert those into something like:apple: 85%, banana: 14%, car: 1%
Now the model can confidently pick “apple” as the next word, because it has the highest probability.
Softmax is often used at the very last step of the model — it’s what makes the final decision interpretable.
Conclusion

So next time you type a prompt, think of what really happens: it’s not magic, but math. Each word becomes numbers, and those numbers “talk” to each other using attention. Together they decide the best next word—just like a team working together. That teamwork is what makes ChatGPT write stories, answer questions, and even help with code. And as these models get even better, they’ll keep surprising us with what they can create.
Subscribe to my newsletter
Read articles from Rishikesh K V directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by