How to Run DeepSeek-R1 Models Locally Using Ollama
 Lightning Developer
Lightning Developer
In today’s rapidly evolving AI ecosystem, the ability to run powerful language models locally offers a range of compelling benefits—enhanced data privacy, cost-efficiency, offline functionality, and greater control over the deployment environment. The DeepSeek-R1 family of open-source language models delivers robust reasoning, code generation, and problem-solving capabilities, rivaling proprietary solutions—all while running on your hardware.
This guide outlines how to deploy DeepSeek-R1 models locally using Ollama, a user-friendly framework for managing and running LLMs on personal systems. We also demonstrate how to optionally expose your local model as a web API using Pinggy, and explore graphical interaction through Open WebUI.
Key Advantages of Running DeepSeek-R1 Locally
Data Privacy: Your inputs and outputs remain entirely on your machine.
Cost-Free Operation: No API usage limits or monthly fees.
Offline Accessibility: Operate fully without an internet connection.
Flexible Model Sizing: Select from lightweight to high-capacity models based on your hardware.
Step-by-Step Installation Guide
Step 1: Install Ollama
Visit the Ollama download page.
Select the version compatible with your operating system (Windows, macOS, or Linux).
Follow the installation instructions for your platform.
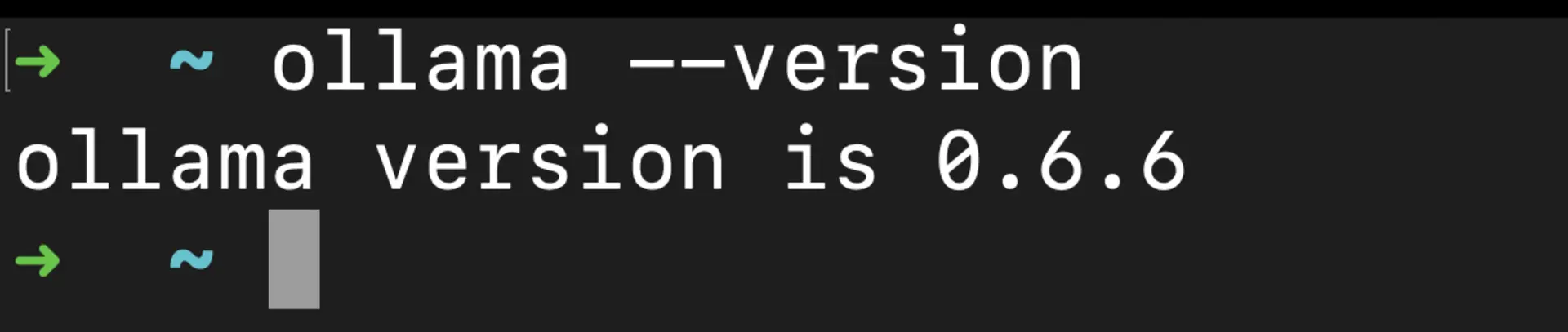
Confirm installation:
ollama --version
Step 2: Download a DeepSeek-R1 Model
Choose a model variant suited to your system's memory capacity:
| System Memory | Recommended Model | Command |
| ≤ 8GB | deepseek-r1:1.5b | ollama pull deepseek-r1:1.5b |
| ~16GB | deepseek-r1:7b | ollama pull deepseek-r1:7b |
| ≥ 32GB | deepseek-r1:8b/14b | ollama pull deepseek-r1:14b |

Check available models:
ollama list

Step 3: Run the Model
To launch a model in your terminal:
ollama run deepseek-r1:1.5b

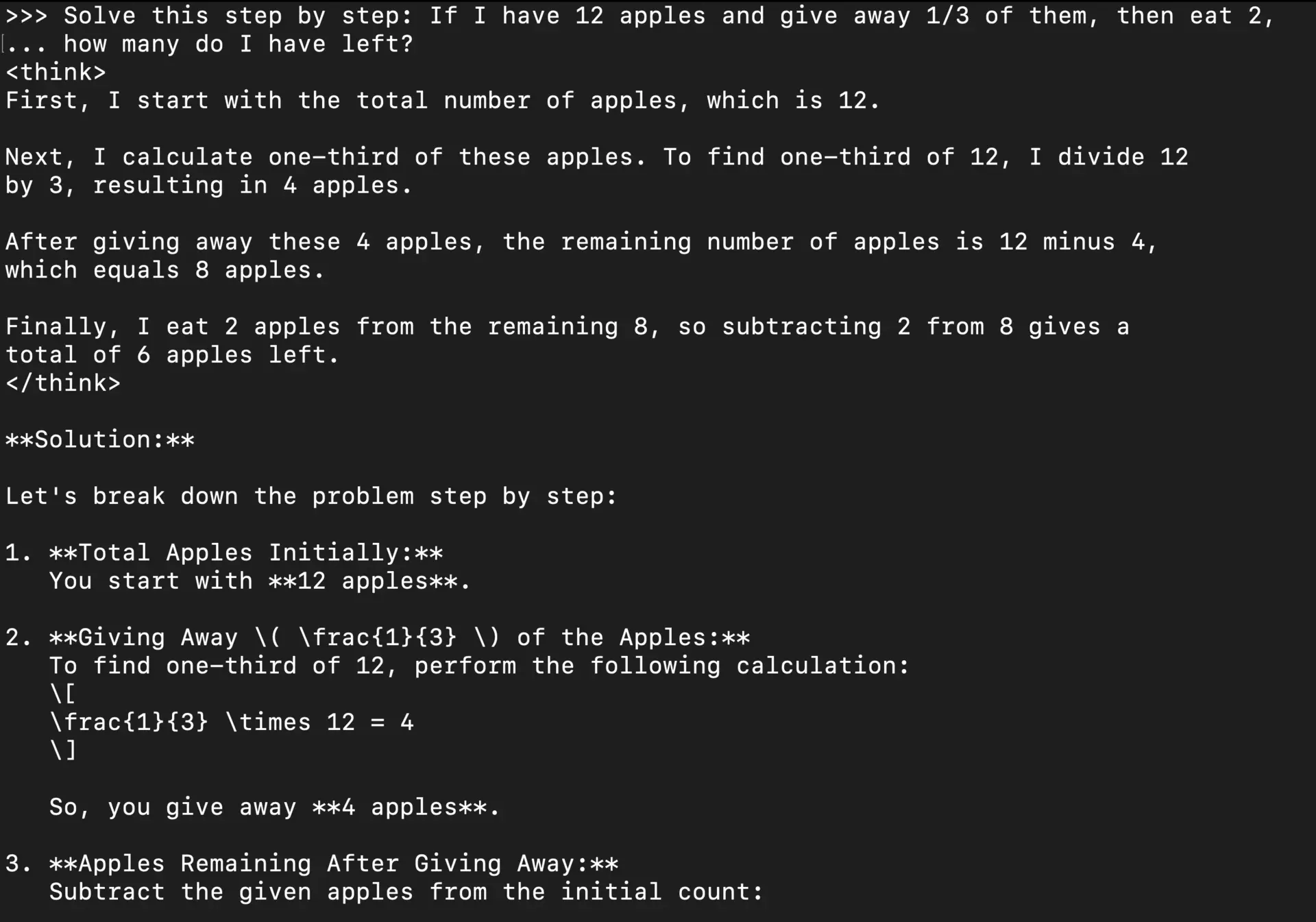
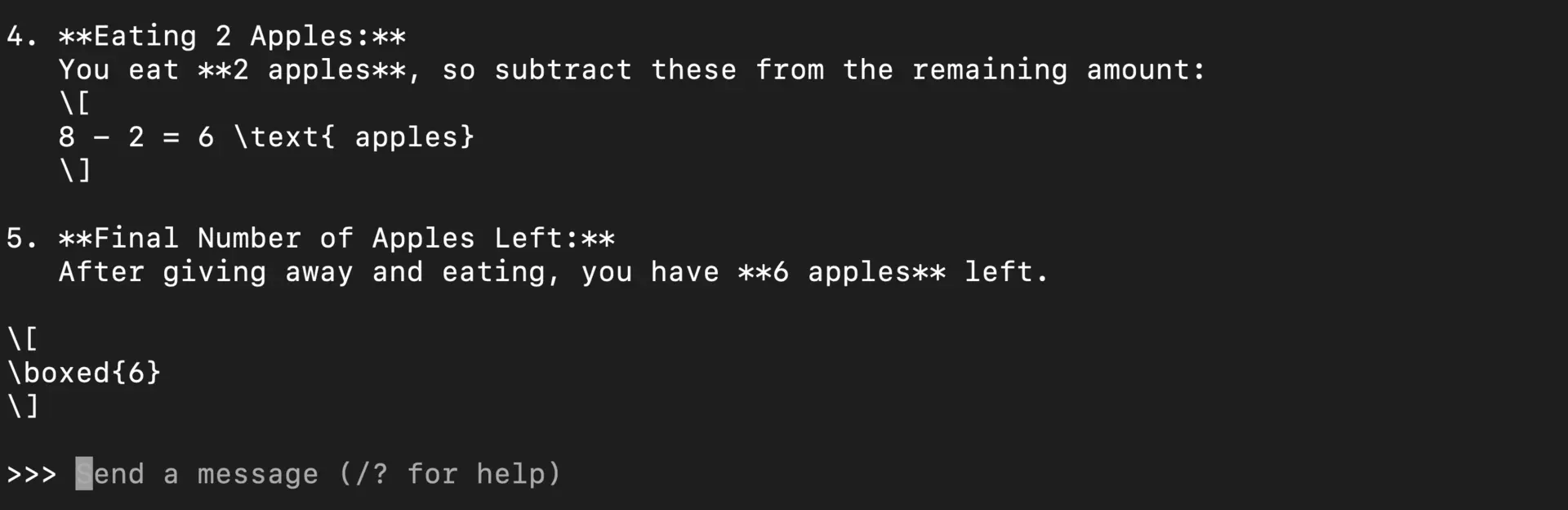
Try it with reasoning tasks:
User: Solve this step by step: If I have 12 apples and give away 1/3, then eat 2, how many are left?
Using DeepSeek-R1 via API
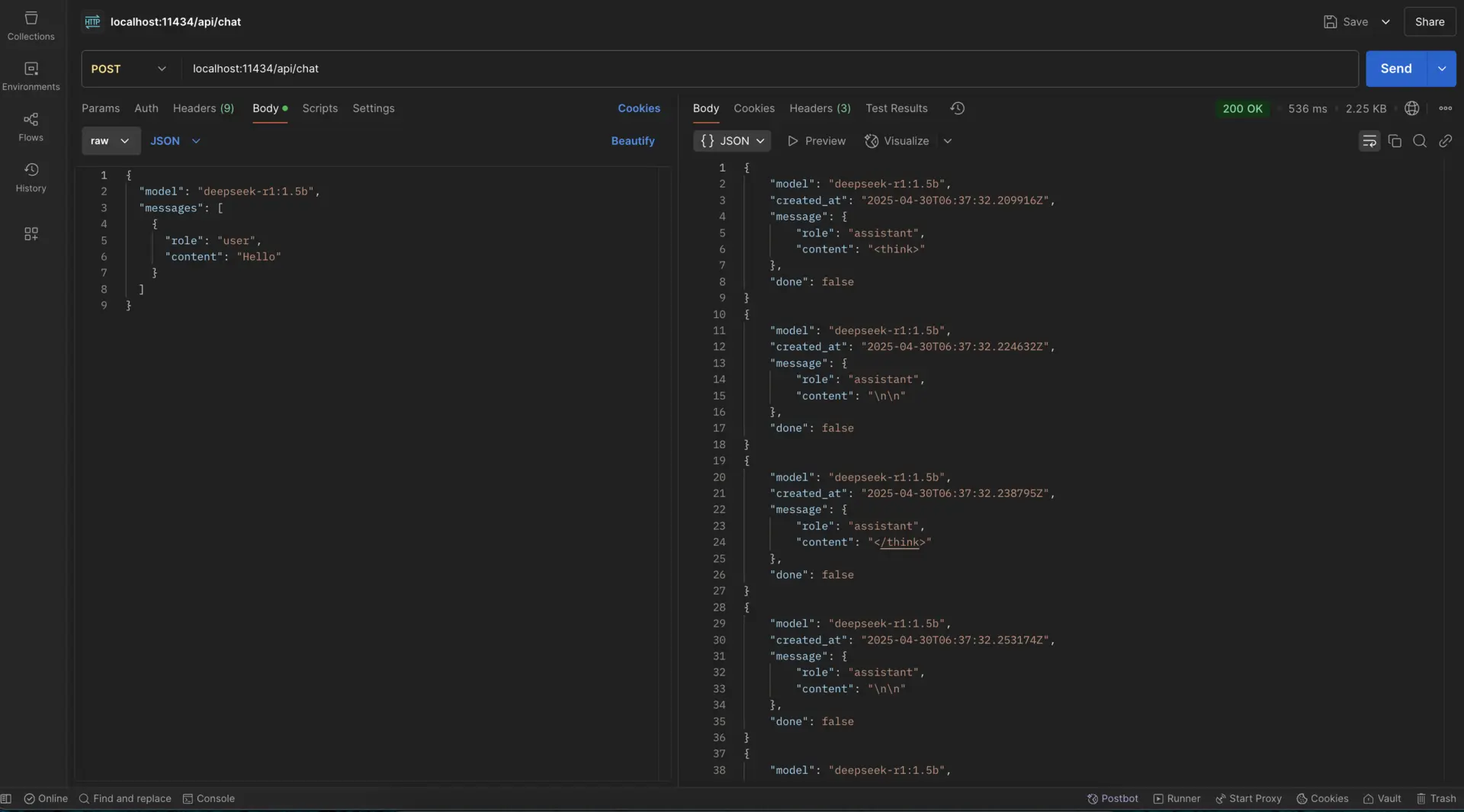
1. Start the Ollama server:
ollama serve
2. Make requests using curl:
curl --location 'http://localhost:11434/api/chat' \
--header 'Content-Type: application/json' \
--data '{
"model": "deepseek-r1:1.5b",
"messages": [{"role": "user", "content": "Hello"}]
}'
You can also integrate the API into Node.js by cloning the RunOllamaApi repository, installing dependencies, and running your script with:
node main.js
Graphical Interface with Open WebUI
If you prefer a user-friendly GUI, install Open WebUI, which offers a ChatGPT-like experience.
Installation via Docker:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Access the interface at http://localhost:3000. Select your DeepSeek model and begin chatting, uploading files, and organizing conversations.
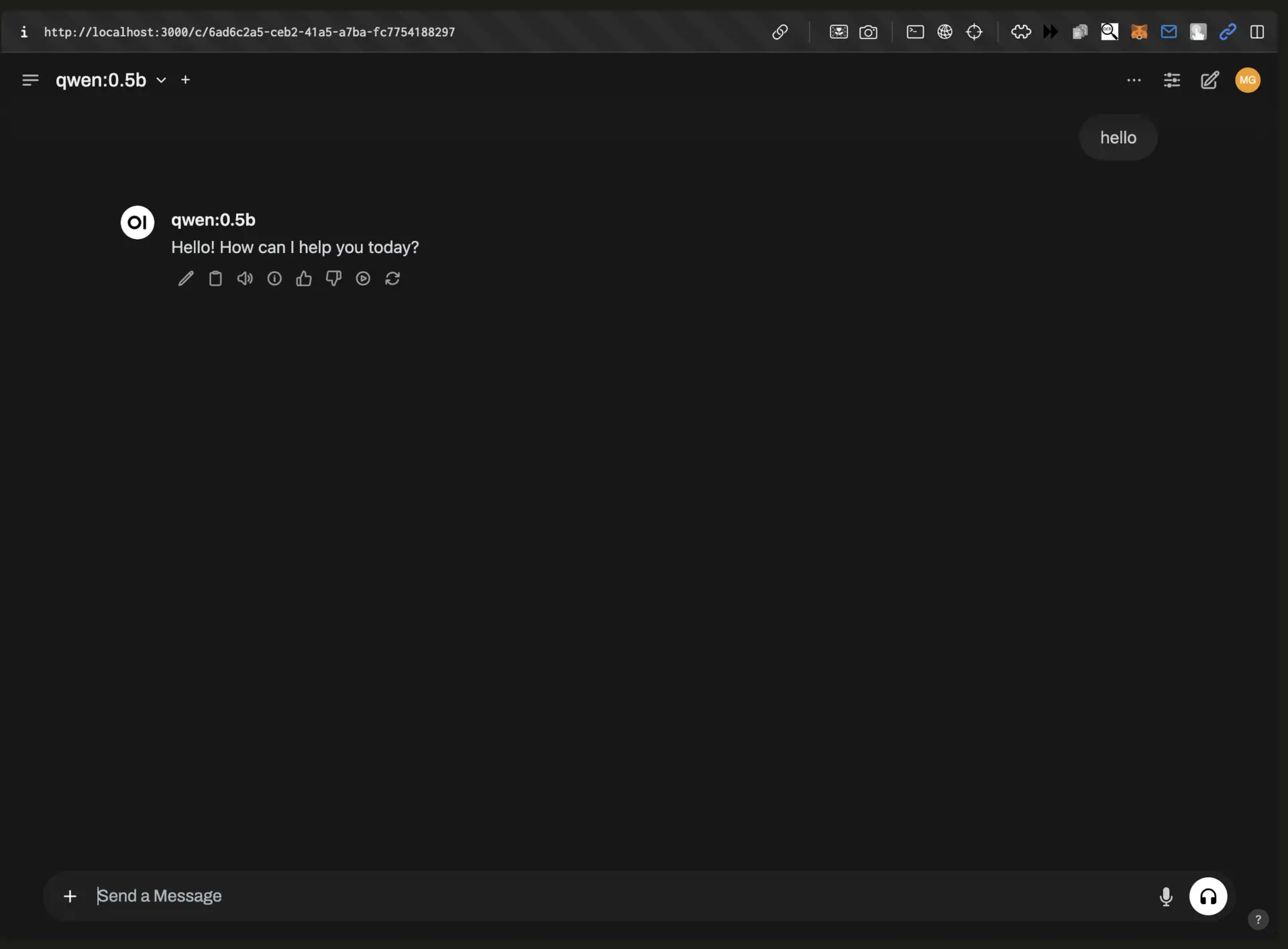
Key Features:
Multi-modal input (text + images)
Session and chat history
Preset prompts and system instructions
Mobile compatibility
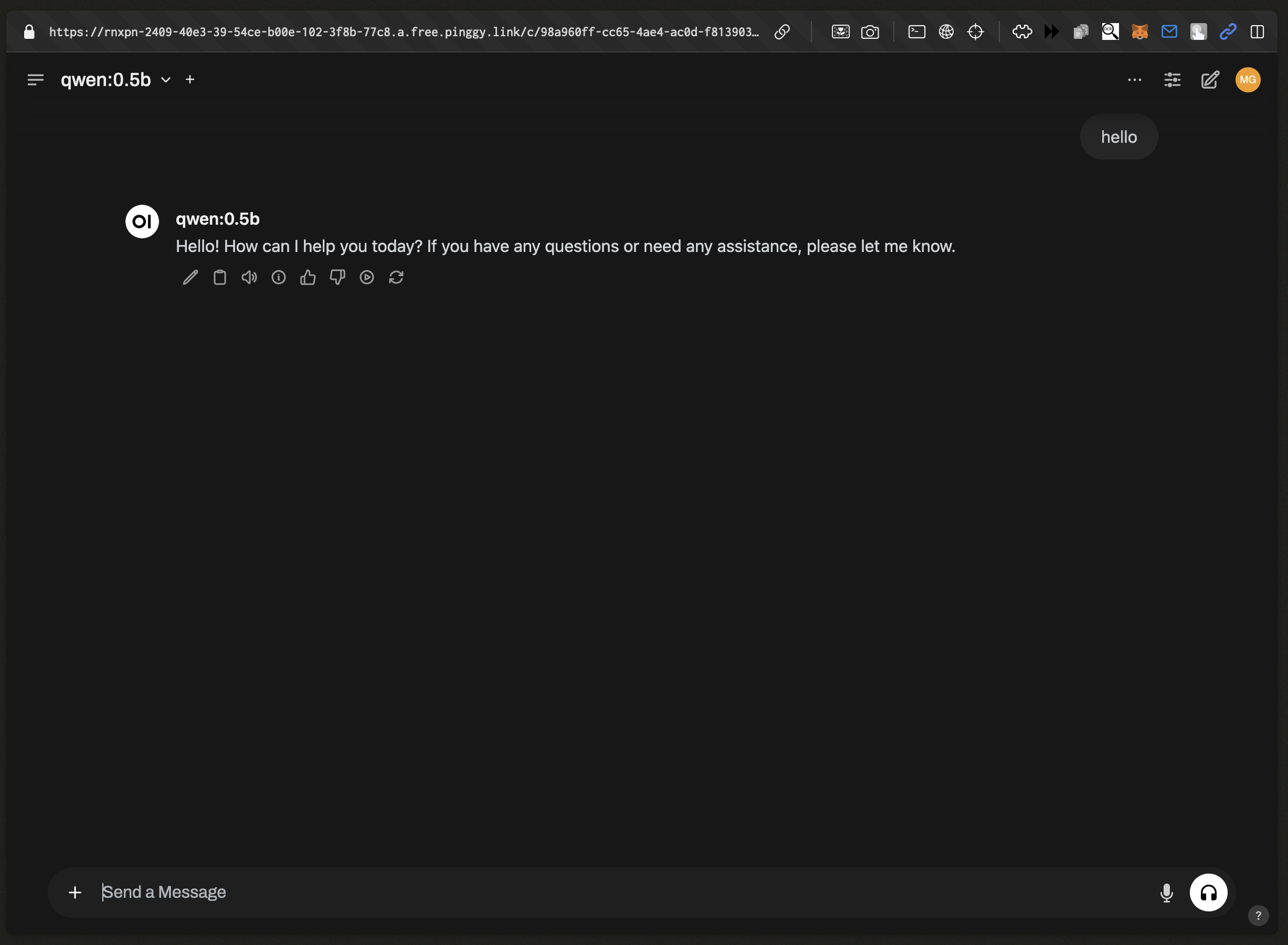
Sharing Access with Pinggy (Optional)
Pinggy allows you to expose your local Ollama API over the internet.
Steps:
- Ensure the Ollama server is running:
ollama serve

- Create a public tunnel using Pinggy:
ssh -p 443 -R0:localhost:11434 -t qr@a.pinggy.io "u:Host:localhost:11434"

You’ll receive a URL such as https://abc123.pinggy.link, which can be used to access your API remotely.
Verify Remote API:
curl https://abc123.pinggy.link/api/tags

Performance Optimization Tips
- Use quantized models to reduce memory footprint:
ollama run deepseek-r1:1.5b-q4_K_M
- Tweak parameters for more dynamic responses:
ollama run deepseek-r1:1.5b --temperature 0.7 --top_p 0.9
- For slow performance, reduce context size:
ollama run deepseek-r1:1.5b --num_ctx 1024
About DeepSeek-R1 Models
DeepSeek-R1 is a suite of open-source language models available under the permissive MIT License—ideal for both research and commercial use.
Architecture Overview:
Qwen-based Models: 1.5B, 7B, 14B, 32B
LLaMA-based Models: 8B, 70B
Conclusion
Running DeepSeek-R1 locally via Ollama provides a seamless, secure, and high-performance LLM experience. Whether you're a developer, researcher, or enthusiast, you can now harness cutting-edge AI capabilities on your machine, without compromising on privacy or control.
Get Started Now:
ollama pull deepseek-r1:1.5b && ollama run deepseek-r1:1.5b
References
Subscribe to my newsletter
Read articles from Lightning Developer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by