JarGons Of GEN-AI
 Deepak Kumar Kar
Deepak Kumar Kar
Understanding the Tech Jargon, so-called techy fancy words, more easily!
In this World With unlimited possibilities and resources, it is harder to find the right content and the correct approach to everything
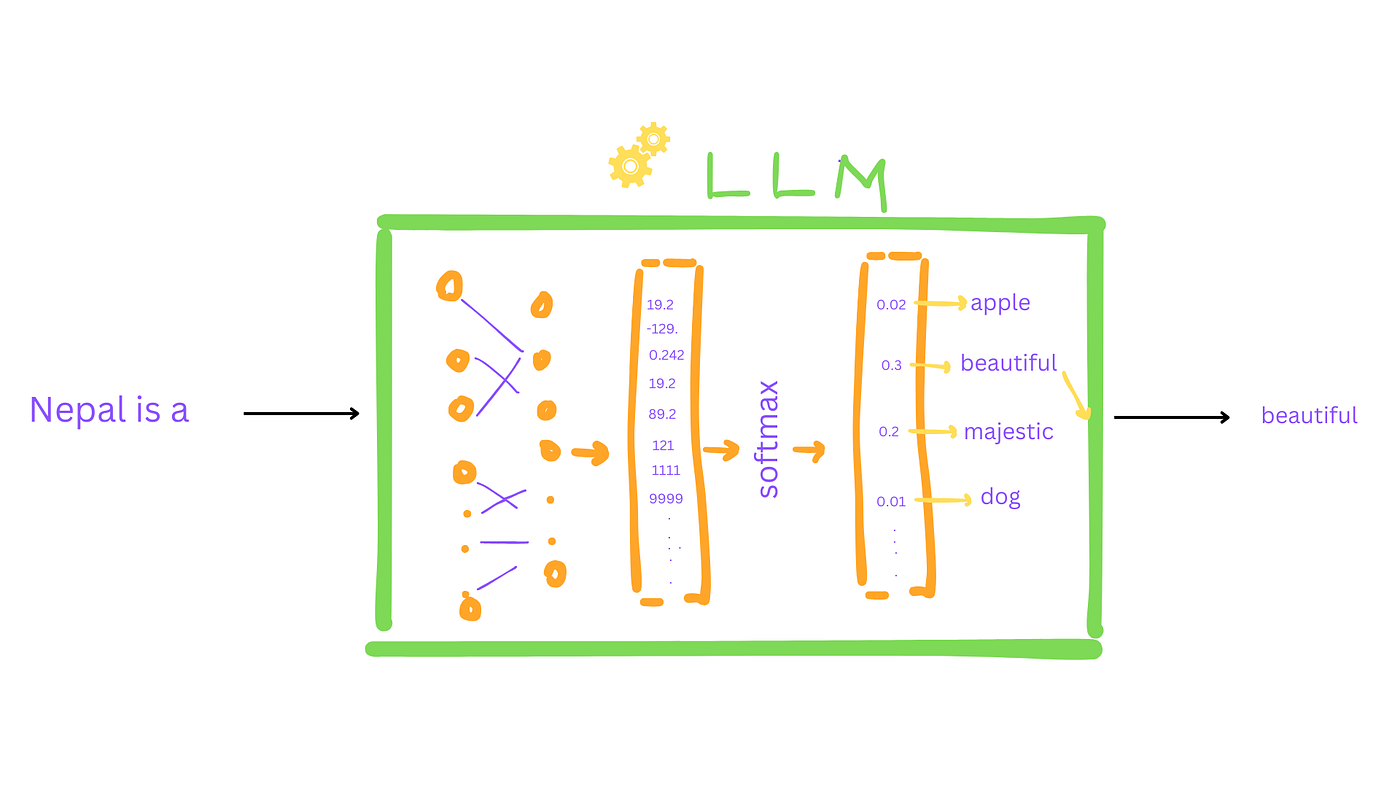
Transformer🤖🤖

1. Transformers
Transformers are a type of deep learning model introduced in 2017 (in the famous paper "Attention is All You Need"). Unlike older models like RNNs, transformers can process entire sequences of data all at once, making them faster and more powerful.
Key Characteristics of Transformers:
Self-Attention Mechanism:-
- Self-attention mechanism is the process when tokens can understand each other's semantic meanings and arrange them with each other and make the vector embedding meaningful like the original sentence
Versatility:-
- Transformers are not limited to language tasks; they can be applied to any problem involving sequential data, including tasks like image recognition and time-series forecasting.
Parallelisation:-
- Unlike traditional RNNs (Recurrent Neural Networks), which process data sequentially, Transformers can process multiple words at once, making them faster and more efficient.
2. Encoder and Decoder
A transformer typically has two main parts:
Encoder: the process or function that converts raw text into a sequence of numerical tokens with the text's real meaning and often integers or other numerical representations.

The encoder contains a multi-head attention layer.
Decoder:-
The process of converting a sequence of numerical IDs (often called token IDs) back into human-readable text
Decoder is comprised of a self-attention layer and a feed-forward network, like an encoder
The decoder contains a multi-head attention masking layer.

3. Vectors
A numerical representation of data, like text or images, that the model can process and understand. This allows the model to perform mathematical operations on language.
These are also called embeddings as they capture the semantic meaning of the data, allowing LLMs to identify similarities and relationships between different pieces of information
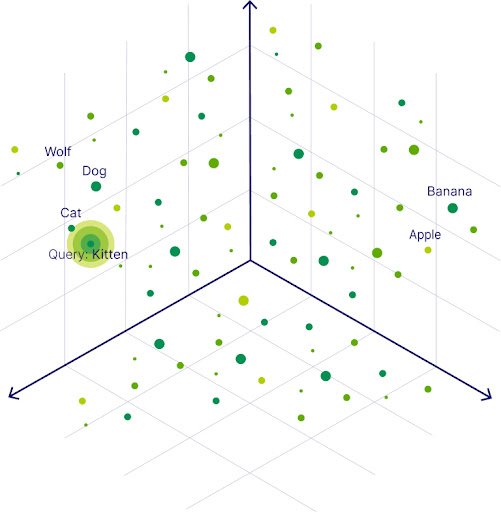
4. Embeddings
Embeddings are the process of converting words into vectors in a way that captures their meaning. For example, the words "king" and "queen" will have similar embeddings because they are related.
Embeddings encode the relationships between different words and phrases, enabling the model to perform tasks like text classification, sentiment analysis, and semantic search
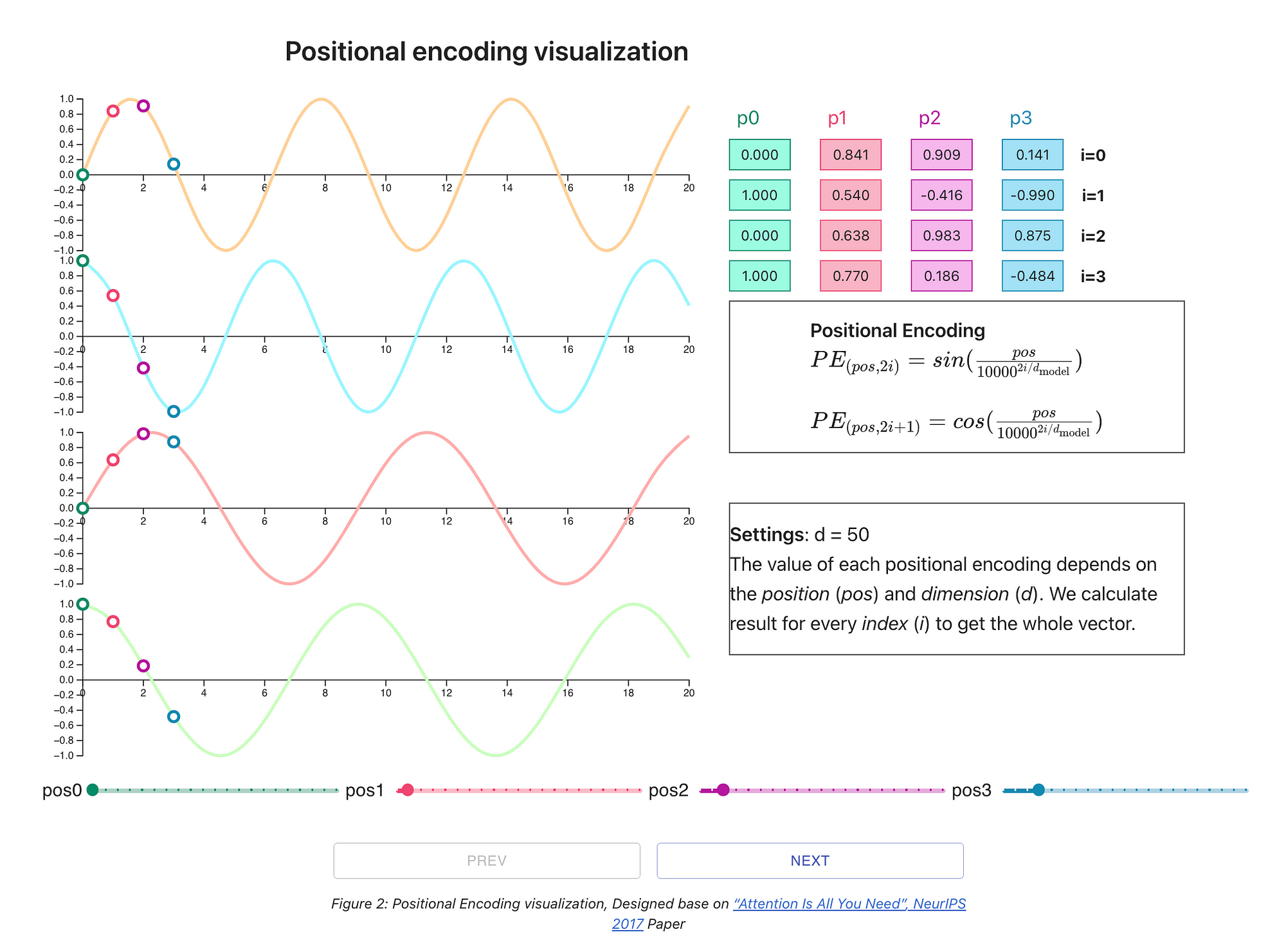
5. Positional Encoding
Transformers don’t understand word order by default. Positional encoding adds information about the position of each word in the sentence, helping the model understand grammar and structure.
It provides each token with a positional context to track each token's positional sequence
6. Semantic Meaning
Semantic meaning refers to the actual meaning behind words and sentences. Transformers learn to understand this by examining how words relate to each other in context.
7. Self-Attention
Self-attention mechanism is the process when tokens can understand each other's semantic meanings and arrange them with each other and make the vector embedding meaningful like the original sentence
Working of Self-Attention: Self-attention provides a dynamic approach to generating words by adjusting the representation of each word based on the surrounding words, effectively creating contextual embeddings.
Self-Attention has 3 components:-
Queries (Q)
Keys (K)
3. Values (V)
Example: In the sentence “The cat sat on the mat,” self-attention helps the model know that “the mat” is what “sat” is referring to.

8. Softmax
Copysoftmax(x_i) = exp(x_i) / sum(exp(x_j)) for j = 1, ..., KIt is a normalised exponential function, a mathematical function that converts a vector of real numbers into a probability distribution
Softmax is a function that helps the model make decisions. It takes a list of numbers and turns them into probabilities that add up to 1. This helps the model choose the most likely word in a sentence.
How Does Softmax Work?
The softmax function works by taking an input vector and performing two main operations:
Exponentiation: It applies the exponential function (e^x) to each element in the input vector. This step ensures all values are positive and amplifies differences between elements.
Normalisation: It divides each exponentiated value by the sum of all exponentiated values. This step ensures the output sums to 1, creating a valid probability distribution.
The result is a vector where each element represents the probability of belonging to a particular class, with all probabilities summing to 1.
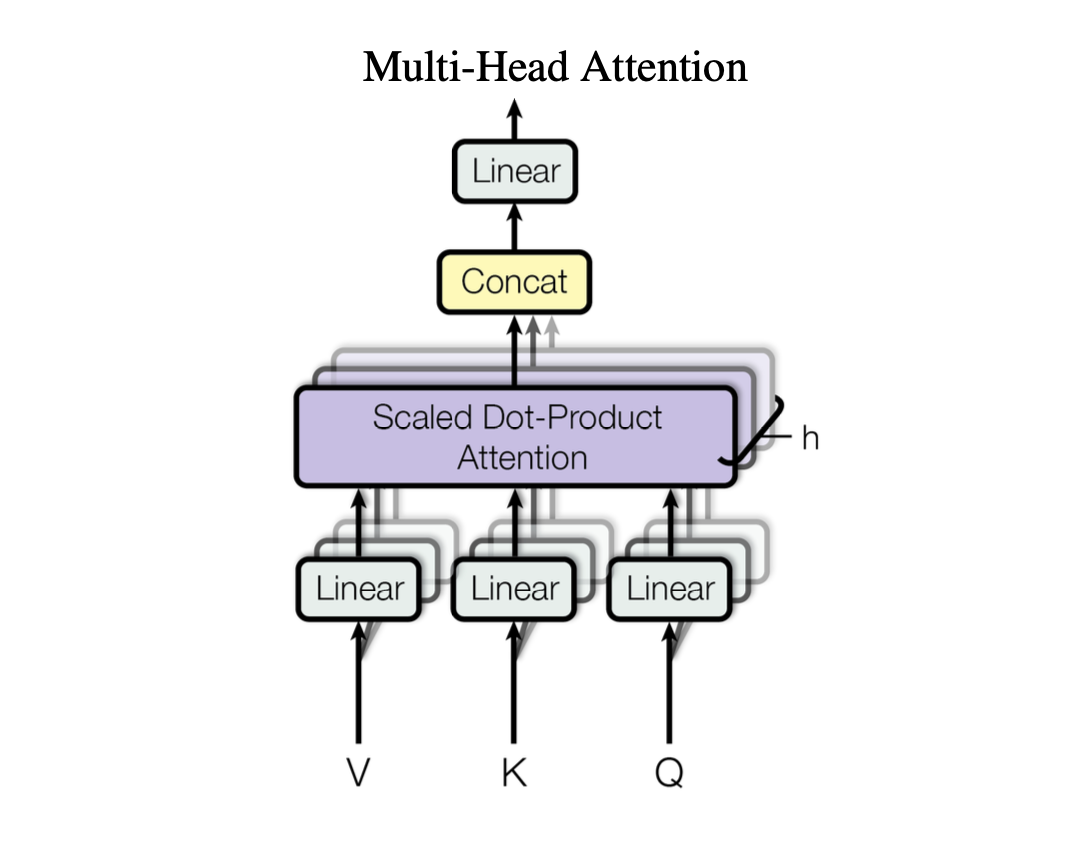
9. Multi-Head Attention
Multi-Head Attention is an advanced extension of the Self-Attention.
It enhances the model’s ability to focus on different parts of an input sequence simultaneously.
It involves repeating self-attention multiple times, with each repetition having different linear projections of the input data to allow the model to attend different aspects of sequence in parallel to make final output robust and contextually rich.
10. Temperature (Temp)
Temperature controls the randomness of the output. A lower temp (e.g., 0.2) makes the model more predictable. A higher temp (e.g., 1.0 or more) makes it more creative or random.
It ranges from 0 to 2.

11. Knowledge Cutoff:
The last date of information used to train the model.
AI models like Chatgpt are trained up to a certain date. They don’t know anything beyond that point unless updated. This is called the knowledge cutoff.

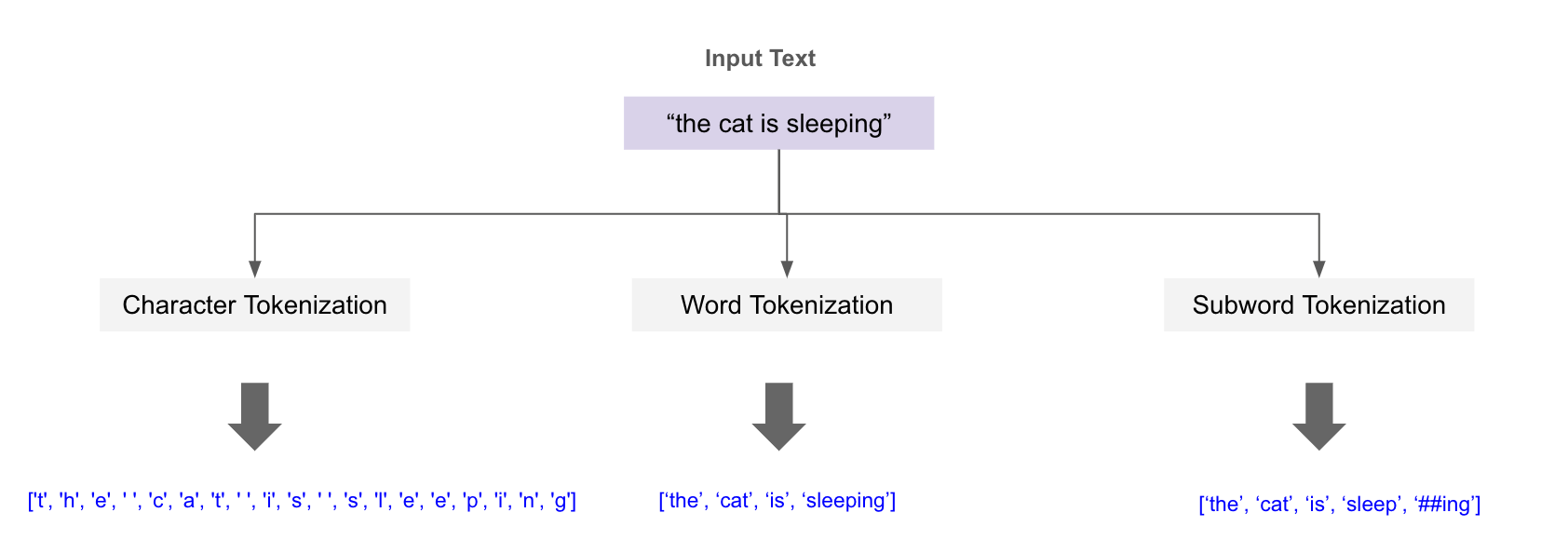
12. Tokenisation:
Is breaking down text into smaller units, or tokens, which can be individual words, parts of words, or even whole phrases
Before feeding text into a transformer, it's broken down into small pieces called tokens. These can be words, subwords, or even characters. The model processes these tokens, not raw text.
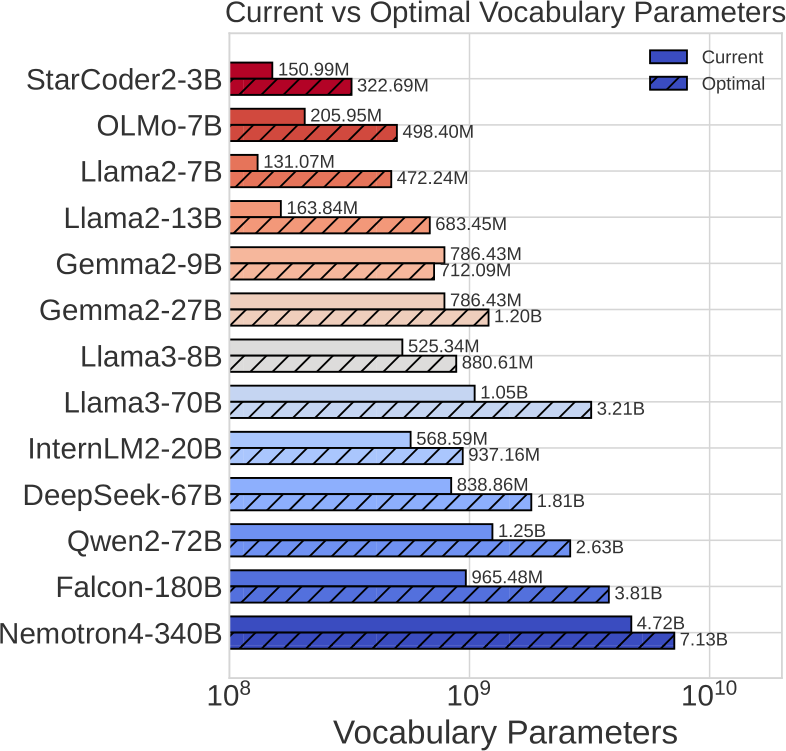
13. Vocab Size:
Vocabulary size in the context of LLMs refers to the total number of unique words, or tokens, that the model can recognise and use
A larger vocab size means the model can handle more words, but it also requires more memory.
Subscribe to my newsletter
Read articles from Deepak Kumar Kar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Deepak Kumar Kar
Deepak Kumar Kar
I'm a tech-savvy enthusiast passionate about innovation and emerging technologies. I love connecting with like-minded people through conferences, hackathons, and collaborative projects. Always eager to exchange ideas, explore creative solutions, and help shape the future through meaningful tech conversations.