Building Domain-Specific AI with RAG: using Amazon Q, Bedrock, and LangChain
 Maitry Patel
Maitry PatelAs organizations adopt Large Language Models(LLMs), one challenge keeps surfacing: how do you make them useful with your data?
Most LLMs are trained on the internet, but internal documents, healthcare records, compliance policies, or financial reports are not publicly available. This is where Retrieval-Augmented Generation(RAG) comes into play.
In this post, we will walk through how to build a domain specific AI assistant using Amazon Q, Amazon Bedrock, LangChain, and your own structured/unstructured data.
Why Traditional LLMs Fall Short?
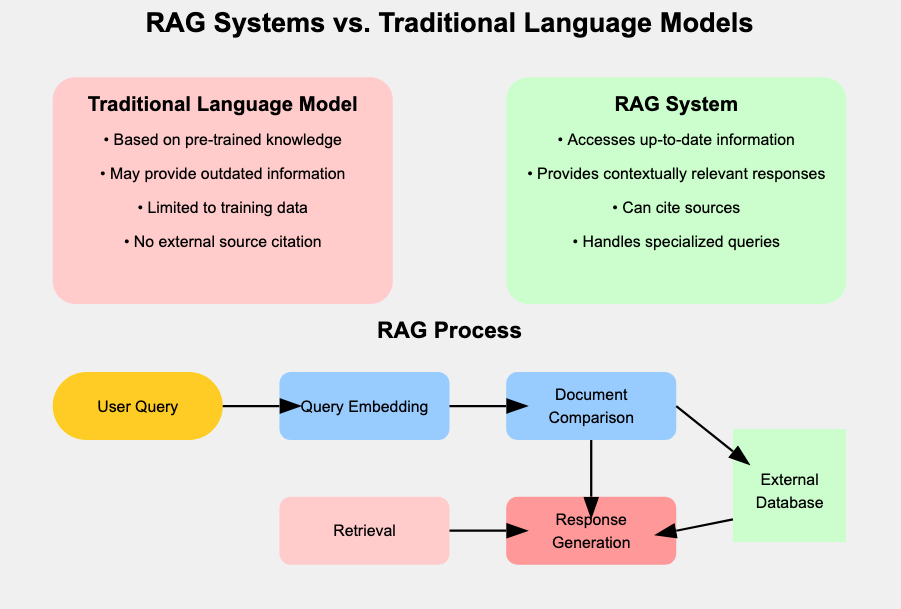
LLMs are incredibly powerful, but they don’t always have the most current or relevant information—especially for domain-specific fields like healthcare.

"Trying to answer without citations like…"
This is where Retrieval-Augmented Generation (RAG) comes in. RAG combines language models with external search or knowledge bases to provide accurate, up-to-date, and domain-specific answers.
Introduction to Rag
Retrieval-Augmented Generation (RAG) is a powerful method that enhances LLMs by giving them access to external knowledge(which may be outdated or generic), RAG retrieves relevant documents and then feeds them into the LLM for context-aware response generation.
Why use RAG for domain-specific ML?
Reduce hallucinations
Provides traceable, explainable outputs
Customizes LLMs without fine-tuning

“Why go slow, when RAG can speed things up?”
Core Components of the RAG Stack
To make RAG work in an enterprise-grade setup, you will use a few AWS-native and open-source tools:
Amazon Q: Offers secure, enterprise-aware conversational AI. It can access internal content like wikis, SharePoint, codebases, and more using built-in connections.
Amazon Bedrock: Gives access to foundation models like Anthropic Claude, Mistral, Amazon Titan, and others—all serverless, API-based, and secure.
LangChain: A framework that allows you to orchestrate complex RAG flows including retrieval, context injection, and chain logic.
Vector Stores: Use Amazon OpenSearch, S3, or Amazon Kendra to store your document embeddings for efficient semantic search.
Working with Your Own Data
The key to an effective RAG system is feeding the model the right data. Here’s how you do it:
Step 1: Chunking
split large documents(PDFs, HTML, CSVs) into semantically meaningful chunks. This improves retrieval granularity.

Step 2: Embedding
Generate vector embeddings for each chunk using
Amazon Titan Embeddings (via Bedrock)
SageMaker Embedding Models
Open-source models (e.g., sentence-transformers)
Step 3: Indexing
Store the embeddings in a vector database (e.g, OpenSearch, FAISS, or Pinecone). Add metadata tags like document type, date, or access level.
Step 4: Retrieval and Generation
When a user asks a question:
LangChain fetches relevant chunks via similarity search.
Amazon Q or Bedrock model receives the context.
The model generates a grounded, informed answer.
RAG Workflow Example: Healthcare Assistant
Let’s say you want to build an AI assistant for hospital staff to ask questions about clinical guidelines or treatment policies.
Upload: Internal hospital policy PDFs to Amazon S3.
Embed: Use Bedrock Titan to create document vectors.
Store: Save embeddings in Amazon OpenSearch.
Query: LangChain retrieves top matches for each user query.
Generate: Bedrock model (e.g., Claude) generates a response grounded in hospital protocols.

Once the user’s question is validated, it’s passed to LangChain, which transforms it into a structured format, identifies the appropriate tools, and orchestrates the retrieval from data sources like S3, OpenSearch, or Kendra.

Query transformation mode: ACTIVATED.
With this transformation, LangChain ensures the query is not just understood, but optimized for intelligent retrieval and grounding.
Security and Optimization
Security
Use Amazon Q’s role-based access control (RBAC) to ensure users only see the content they are authorized to.
Encrypt data at rest (S3, OpenSearch) and in transit.
Apply Amazon CloudWatch to log and audit requests.

Amazon Q, every time someone without clearance tries to access patient data.
Optimization Tips
Reranking: Improve retrieval accuracy with relevance scoring or filters.
Hybrid search: Combine keyword + vector search.
Metadata Filters: Narrow document scope using tags like department or policy type.
Reduce Hallucinations: Limit LLM response to only retrieved content (using LangChain’s stuffing, map-reduce, or refine methods).
Conclusion and Next Steps:
RAG lets you supercharge domain-specific ML apps by combining the power of LLMs with your enterprise data. Whether it’s healthcare, legal, finance, or education, a RAG-based assistant can drastically improve productivity and decision-making.
QuickStart Checklist:
Use Amazon Q to access and secure enterprise content
Generate embeddings using Amazon Bedrock
Store vectors in OpenSearch or Kendra
Build RAG pipelines with LangChain
Test and optimize for accuracy, security, and latency

“Still waiting for your LLM to give you current healthcare insights…”
Ready to build your own?
Try combining Amazon Q + LangChain to create a custom AI assistant for your domain today.
Subscribe to my newsletter
Read articles from Maitry Patel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by