Reciprocal Rank Fusion
 Nitesh Singh
Nitesh Singh
As discussed in the previous article, Multi-Query Retrieval, reciprocal rank fusion is an extension of multi-query Retrieval. Where a multi-query retrieval does a union of the relevant documents in which the relevance of a particular document cannot be measured, reciprocal rank fusion solves this issue by providing a ranking for each document.
What is RRF?
Reciprocal rank fusion (RRF) is a reranking algorithm that gives a reciprocal rank to documents in multiple sources, then combines those ranks and documents into one final reranked list using the following formula.
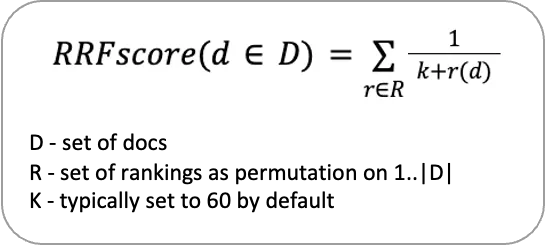
Each retriever provides its ranking of relevant documents, and finally, a unified ranking is produced based on the RRF scores.
Do you know when to use RRF?
Reciprocal Rank Fusion excels in the following scenarios.
Complex user queries.
Dealing with large datasets
Avoiding biases in search results.
Situations requiring in-depth information.
In simple terms, RRF is ideal when there is a need to go beyond the surface-level information provided by a standard RAG model, ensuring a more comprehensive response to complex queries.
Working
The process of reciprocal rank fusion is similar to that of Multi-Query Retrieval, just the union of the relevant documents is replaced by a rank fusion.
Generating the user prompt.
Generation of multiple queries using LLM and user prompt.
Retrieval of relevant documents for each query.
Rank fusion of relevant documents.
The final output will be generated by LLM using relevant documents and a user prompt.

Code Implementation
Python, Langchain, Qdrant, and OpenAI were used for the code.
The function of rank fusion distinguishes reciprocal rank fusion and multi-query retrieval, using the formula RRF_score = ∑ (1 / (k + rank + 1)), ranking is given to all the documents, here rank + 1 is used instead of rank as enumerate starts with 0, where as the ranking should begin with 1. Finally, a list of documents with their corresponding score is returned.
def rank_fusion(self, documents, k=60):
relevant_chunks = []
doc_ranks = {}
for sublist in documents:
for rank, doc in enumerate(sublist):
doc_str=dumps(doc)
doc_ranks[doc_str] = doc_ranks.get(doc_str, 0) + 1 / (k + rank + 1)
for doc_str, score in doc_ranks.items():
relevant_chunks.append([loads(doc_str), score])
relevant_chunks.sort(key=lambda x: x[1], reverse=True)
return relevant_chunks
The multi query prompt is reused in this approach as well, to generate five different question for the user query.
self.multi_query_prompt="""
You are an AI language model assistant.
Your task is create five versions of the user's question to fetch documents from a vector database.
By offering multiple perspectives on the user's question, your goal is to assist the user in overcoming some of the restrictions of distance-based similarity search.
Give these alternative questions, each on a new line.
Question: {question}
Output:
"""
A retrieval chain is made using multi_query_prompt_template, llm (OpenAI GPT model), StrOuputParser to convert llm output to string format, a lambda function to list all the questions, a retriever to retrieve relevant documents from the Qdrant vector store, and finally, rank fusion is performed.
retrieval_chain = (
multi_query_prompt_template
| llm
| StrOutputParser()
| (lambda x: [i for i in x.split("\n") if x!=''])
| retriever.map()
| self.rank_fusion
)
The retrieval chain is invoked, and all the documents and scores are returned.
relevant_docs = retrieval_chain.invoke(
{"question": user_prompt}
)
return relevant_docs
Here is the complete code for retrieval using Reciprocal Rank Fusion
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.load import loads, dumps
class Reciprocal_Rank_fusion:
def __init__(self) -> None:
self.multi_query_prompt="""
You are an AI language model assistant.
Your task is create five versions of the user's question to fetch documents from a vector database.
By offering multiple perspectives on the user's question, your goal is to assist the user in overcoming some of the restrictions of distance-based similarity search.
Give these alternative questions, each on a new line.
Question: {question}
Output:
"""
def rank_fusion(self, documents, k=60):
relevant_chunks = []
doc_ranks = {}
for sublist in documents:
for rank, doc in enumerate(sublist):
doc_str=dumps(doc)
doc_ranks[doc_str] = doc_ranks.get(doc_str, 0) + 1 / (k + rank + 1)
for doc_str, score in doc_ranks.items():
relevant_chunks.append([loads(doc_str), score])
relevant_chunks.sort(key=lambda x: x[1], reverse=True)
return relevant_chunks
def get_revlevant_docs(self, llm, retriever, user_prompt):
multi_query_prompt_template = ChatPromptTemplate.from_template(self.multi_query_prompt)
retrieval_chain = (
multi_query_prompt_template
| llm
| StrOutputParser()
| (lambda x: [i for i in x.split("\n") if x!=''])
| retriever.map()
| self.rank_fusion
)
relevant_docs = retrieval_chain.invoke(
{"question": user_prompt}
)
return relevant_docs
Output
Following is the output for the user prompt: “What is fs module?”
The fs module in Node.js is a built-in core module that provides functions to interact with the file system. It allows you to perform operations such as reading, writing, updating, and deleting files on your system.
For example, you can use the fs module to write a message to a file like this:
```javascript
const fs = require('fs');
fs.writeFileSync('notes.txt', 'I live in Philadelphia');
```
In this script, the fs module is loaded using require, and the writeFileSync function is used to write the text "I live in Philadelphia" to a file named notes.txt. After running this script, you'll find a new notes.txt file in your directory with that content.
Conclusion
In this article, we learnt about Reciprocal Rank Fusion, its use case, and working along with code implementation. You can get all the code on my GitHub.
There is always a trade-off. Compared to a standard RAG, it takes more time to execute but provides in-depth knowledge and helps resolve complex queries.
Subscribe to my newsletter
Read articles from Nitesh Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by