#1 - Demystifying AI
 Mishal Alexander
Mishal Alexander
INTRODUCTION
The word "AI" seems terrifying to some and mysterious to others at first glance. Movies like The Terminator series have implanted fear in the public, fostering skepticism or even hatred toward AI advancements. But fret not—AI is not as enigmatic as it seems. In fact:
AI = Data + Algorithm
That’s it!
AI is not here to "take away jobs" or "lead the world into destruction." This perception stems, in my opinion, from the mystery shrouding AI concepts. Therefore, it’s crucial to demystify AI to reduce fear and harness its potential for building useful solutions.
DATA SCIENCE VS GEN-AI
First, let’s distinguish data science from generative AI.
Data scientists are like airplane manufacturers—they build AI models by studying their inner workings and developing algorithms.
Generative AI developers are like pilots—they use pre-trained models without worrying about how they were trained.

An AI model is also referred to as ‘Language Models’. A language model has two phases:
Training phase (where data scientists build the model).
Inference phase (where generative AI developers use the model).
Just as pilots fly planes built by engineers, effectively using AI models built by data scientists is a skill in itself. In order to delve deeper into the AI model world, we’d need to demystify some terms specific to large language models.
JARGON TO BE DEMYSTIFIED
This article covers the following terms:
Transformer
Knowledge cutoff
Input query
Encoder & Decoder
Vectors & Embedding
Positional Encoding
Semantic meaning
Self & Multi-headed Attention
Softmax & Temperature
Tokenization
Vocab size
These concepts provide a solid foundation for your Generative AI journey.
TRANSFORMER
Trivia: Did you know GPT in "ChatGPT" stands for Generative Pre-trained Transformer?
A transformer is an AI language model that predicts the next word (or "token", as we’ll see later) in a user’s input. Think of it as a block of code that mathematically "guesses" the next word based on its training data. Examples include the models like GPT series from OpenAI, Gemma series from Google, Llama series from Meta, etc.

Google engineers introduced the concept of transformers back in 2017 via the paper "Attention Is All You Need" to enhance Google Translate. The diagram above (from the paper) illustrates how transformers work.
KNOWLEDGE CUTOFF
If you send a query to an LLM or Large Language Model (not ChatGPT, but to any model which powers ChatGPT) -
“What is the weather in Delhi today?”
it will return -
I can’t provide real weather updates.

This happens due to knowledge cutoff—the date up to which the AI’s training data extends. If an event occurs after this date, the model does not know about it.
Why is there a cutoff? LLM models are trained using a method called - ‘Back propagation’. It refers to running the model with a particular input until an expected output is returned. Back propagation is a costly and time consuming affair and therefore it cannot be trained with live data.
But then… how does ChatGPT fetch live data?
For instance, if you ask ChatGPT the same question, it returns the correct answer?

This is because the recent updates allow models to search externally (e.g., via API calls) and inject real-time context into responses - this is called context injection. We will cover how this is done but in a different article.
TOKENIZATION
Your input (or query) is converted into tokens through tokenization, where text is split into smaller, AI-processable pieces.
Example:
- "Hello World" — tokenization →
["Hello", "World"]
Since LLM models work with numbers, tokens are mapped to numerical representations. Tools like OpenAI’s tiktokenizer can be used to visualize this process (see diagram below).

VOCAB SIZE
Vocabulary size (vocab size) is the total unique tokens a model recognizes.
ChatGPT’s vocab size: 200,019 (as of writing).
Each token is represented by a vector (numerical array) of ~128,000 elements, called an embedding (explained later).
ENCODER-DECODER
Remember the Caesar Cipher? It shifts letters by a pre-determined fixed number called ‘shift’ (e.g., A→C, M→O). Julius Caesar used this to encode messages and securely communicate with his generals.
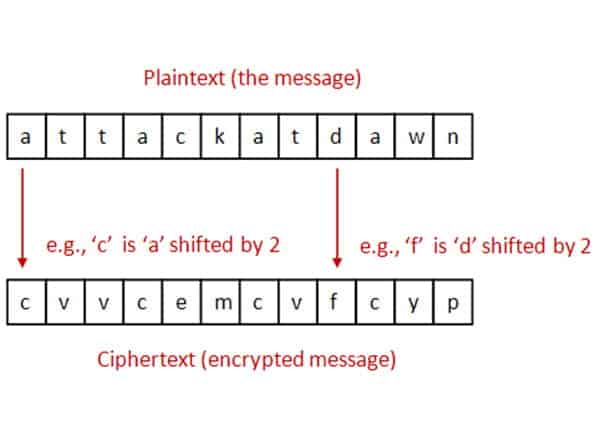
Let’s use the Caesar Cipher analogy to understand encoder and decoder.
Encoder: Converts input text into numerical vectors (like encoding a message).
Decoder: Converts vectors back into human-readable text (like decoding a cipher).
Each company uses its own "shift" (encoding method) for its models.
Still not sure? Well, let’s create a simple tokenizer class with just two methods - encode (to encode user inputs) and decode (to decode the encoded inputs) - in python to drive this learning home:
class Tokenizer:
def __init__(self):
# add alphabets that you want to encode and decode
self.alphabets = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ '
# mapping alphabets to numbers for encoder
self.char_to_index = {char: index + 1 for index, char in enumerate(self.alphabets)}
# mapping digits to alphabets for decoder
self.index_to_char = {index + 1: char for index, char in enumerate(self.alphabets)}
def encode(self, text):
tokens = []
# look for character in the encoder array
for char in text:
if char in self.char_to_index:
# collect the numbers for each characters
tokens.append(self.char_to_index[char])
# return the encoded numbers
return tokens
def decode(self, tokens):
text = ""
# look for number in the decoder array
for token in tokens:
if token in self.index_to_char:
# collect the characters for each numbers
text += self.index_to_char[token]
# return the decoded characters
return text
tokenizer = Tokenizer()
text = "Hello World"
encoded_text = tokenizer.encode(text)
print(f"Encoded: {encoded_text}") # Output: Encoded: [8, 5, 12, 12, 15, 23, 15, 18, 12, 4]
decoded_text = tokenizer.decode(encoded_text)
print(f"Decoded: {decoded_text}") # Output: Decoded: hello world
That's a basic tokenizer, and this is similar to how a real-world LLM model tokenizer functions.
VECTOR EMBEDDING
Vector is a mathematical concept. It is a numerical representation of data (text, images, etc.).

Embedding is the process of retrieving semantic meaning out of the tokenized used input using custom algorithms.

Example:
Input: "King is to Man as Queen is to ____."
The AI plots vectors for "King," "Man," and "Queen" in a 3-D space (see diagram).
By calculating distances, it predicts the next word: "Woman."
This is how embeddings capture relationships between words.
POSITIONAL ENCODING
Words can have different meanings based on position or order of the words in a sentence. Positional encoding ensures the model understands word order by assigning tokens based on position.
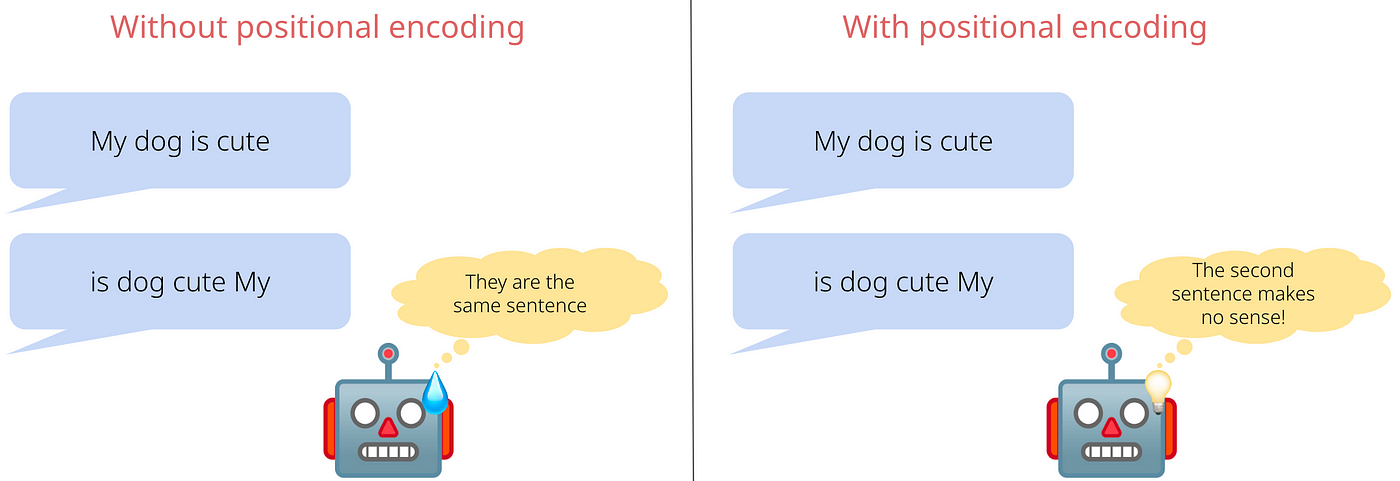
Tokens will be same for any number of occurrences of a word in a sentence - as tokens are constants - but based on order, they can have different meaning. Therefore based on the positioning of the word in a sentence same word can be assigned to different tokens in order to process it better.
SELF & MULTI HEADED ATTENTION
Self-attention in an LLM is an important concept used in natural language processing, that allows a model to focus on specific parts of a sentence or text while processing it. It refers to the mechanism by which the positional encoded vector embedded tokens can ‘talk to each other’ to re-adjust their embedding based on the inferred perspective of the tokens.
Self-attention lets a model focus on relevant parts of a sentence.
Single-head attention: One perspective.
Multi-head attention: Multiple perspectives analyzed in parallel.
This mechanism helps transformers refine embeddings based on context.
LINEAR & SOFTMAX FUNCTIONS
Linear function refers to the probablity of outputs generated by the model and Softmax function helps to pick one output based on the probablity generated by the linear function.
Linear function: Generates output probabilities.
Softmax function: Picks the final output.
Some models label this as "Temperature" or "Creativity":
High temperature = More randomness (creative outputs).
Low temperature = More predictable outputs.
This concept sounds a bit abstract. Let’s use an example to understand this better:
INPUT QUERY - “Hello”
Possible OUTPUTS -
| OUTPUTS | PROBABILITY |
| “Hi, how can I help you?” | 0.95 |
| “Hello there, what brings you here today?” | 0.03 |
| “Top of the morning to you! Its a beautiful day isn’t it?! So what can I do for you today?” | 0.02 |
If temperature is set as 1, it picks the highest-probability response (95%). Lowering temperature increases creativity by allowing lower-probability responses.
CONCLUSION
We’ve explored how GPT models process inputs through:
Tokenization
Vector Embedding
Positional Encoding
Self-Attention
Output Generation
By demystifying these terms, I hope AI feels more approachable and less intimidating.
REFERENCE
Subscribe to my newsletter
Read articles from Mishal Alexander directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mishal Alexander
Mishal Alexander
I'm passionate about continuous learning, keeping myself up to date with latest changes in the IT field. My interest is in the areas of Web Development (JavaScript/TypeScript), Blockchain and GenAI (focusing on creating and deploying memory aware AI-powered RAG applications using LangGraph, LangFuse, QdrantDB and Neo4J). I welcome professional connections to explore new ideas and collaborations.