A series breaking down each major neural network architecture.
 Aakashi Jaiswal
Aakashi Jaiswal
1. Neural Networks: The Basics
The Biological Neuron
What is it?
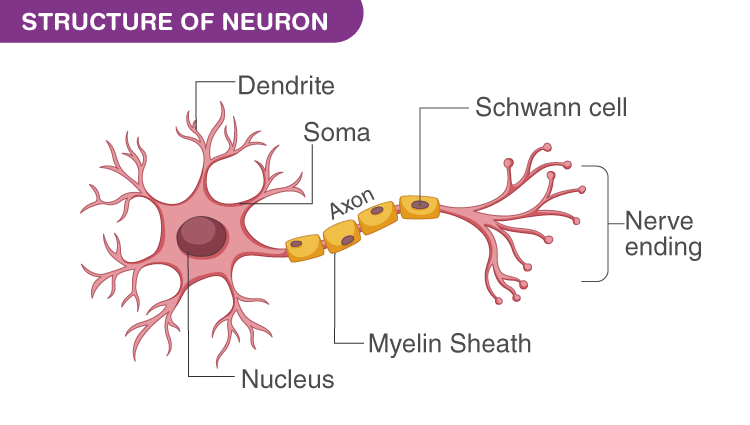
In our brain, a neuron is a cell that receives signals, processes them, and passes them on.
Why do we care?
Neural networks in computers are inspired by how these biological neurons work.
The Perceptron
What is it?
The perceptron is the simplest model of a neural network.
It takes some inputs, multiplies them by weights, adds them up, and passes the sum through an activation function to produce an output.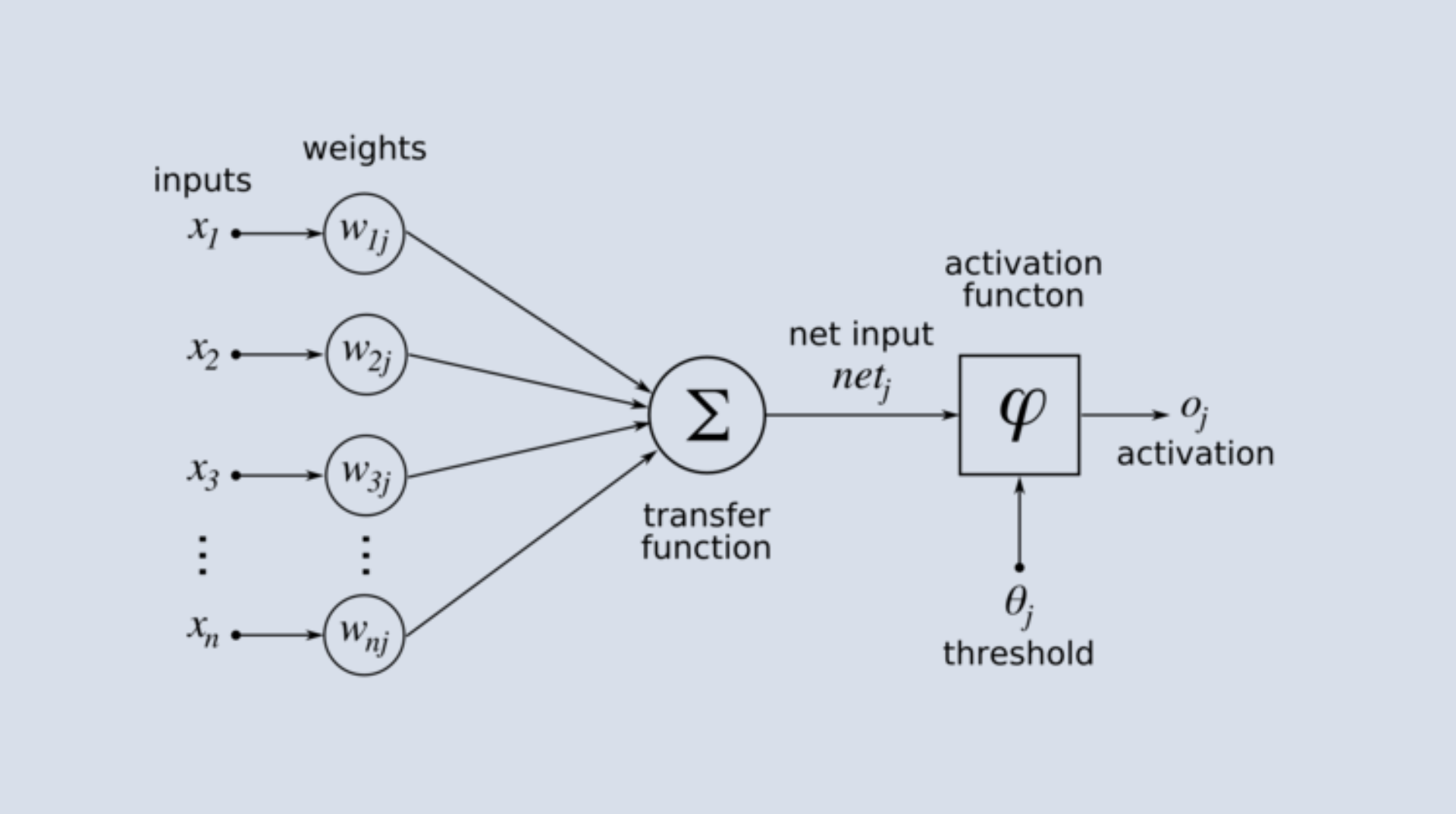
Why is it important?
It’s the building block for more complex neural networks.
Multilayer Feed-Forward Networks

What are they?
When you connect many perceptrons in layers (input layer, hidden layers, output layer), you get a multilayer neural network.Feed-forward?
Information moves in one direction-from input to output-without looping back.
2. Training Neural Networks
Backpropagation Learning
What is it?
A method for teaching the network.
The network makes a prediction, checks how wrong it was (using a loss function), and then adjusts its weights to improve.How?
It works by sending the error backward through the network, updating weights to reduce future errors.
3. Activation Functions
- Why do we need them?
They decide whether a neuron should be activated or not, introducing non-linearity so the network can learn complex patterns.
Types:
Linear:
Output = input. Simple but limited-can’t learn complex things.Sigmoid:
S-shaped curve, outputs between 0 and 1. Good for probabilities.Tanh:
Like sigmoid but outputs between -1 and 1. Often better for hidden layers.Hard Tanh:
Like tanh but with sharp cutoffs. Faster to compute.SoftMax:
Turns outputs into probabilities that add up to 1. Used for classification (e.g., picking the right label).Rectified Linear (ReLU):
Outputs zero if input is negative, otherwise outputs input. Fast and popular for deep networks.
4. Loss Functions
What are they?
They measure how far the network’s predictions are from the actual answers.
The goal is to minimize this loss.Types:
For Regression:
Predicting numbers (e.g., house prices). Common loss: Mean Squared Error.For Classification:
Picking categories (e.g., cat or dog). Common loss: Cross-Entropy Loss.For Reconstruction:
Rebuilding input data (e.g., in autoencoders). Common loss: Binary Cross-Entropy or Mean Squared Error.
5. Hyperparameters
- What are they?
Settings you choose before training the network (not learned from data).
Key Hyperparameters:
Learning Rate:
How big a step the network takes when updating weights. Too high = unstable, too low = slow learning.Regularization:
Techniques to prevent overfitting (the network memorizes instead of generalizing). Examples: L1/L2 regularization, dropout.Momentum:
Helps speed up learning and avoid getting stuck by remembering previous updates.Sparsity:
Encourages the network to use fewer neurons at a time, making it more efficient.
How It All Fits Together
Start with a neural network (inspired by the brain, built from perceptrons).
Feed data through the network (multilayer, feed-forward).
Activate neurons using activation functions to introduce complexity.
Measure how wrong the output is using a loss function.
Train the network using backpropagation to reduce the loss.
Tune hyperparameters to get the best performance.
In summary:
You build a neural network (like a simplified brain), teach it using backpropagation, measure its performance with loss functions, make it smarter with activation functions, and fine-tune its behavior with hyperparameters. All these pieces work together to help the network learn from data and make predictions!
Here is a detailed yet simple explanation of the topics you asked about, presented in a connected flow to help you understand the fundamentals of neural networks and deep learning:
The Mathematical Building Blocks of Neural Networks
Neural networks are inspired by the human brain and consist of interconnected units called neurons or nodes. These networks process data and learn patterns to make decisions or predictions.
Fundamentals of Representations for Neural Networks
Data Representation: Neural networks work with data organized in structures called tensors. A tensor is like a multi-dimensional array (think of it as a table that can have many dimensions, not just rows and columns). For example, an image can be represented as a 3D tensor (height × width × color channels).
Tensors allow neural networks to handle complex data like images, audio, and text efficiently.
The Gears of Neural Networks: Tensor Operations
Neural networks perform mathematical operations on tensors, such as addition, multiplication, and transformations.
These operations combine inputs with weights (parameters that the network learns) to compute outputs.
Efficient tensor operations are crucial because they enable the network to process large amounts of data quickly, often using specialized hardware like GPUs.
The Engine of Neural Networks: Gradient-Based Optimization
Neural networks learn by adjusting their weights to minimize errors in predictions.
This learning happens through gradient-based optimization, mainly using an algorithm called backpropagation combined with gradient descent.
Backpropagation calculates how much each weight contributed to the error, and gradient descent updates the weights to reduce the error step-by-step.
This process is repeated many times until the network performs well on the task.
Introduction to Keras and TensorFlow
TensorFlow is a powerful, low-level framework developed by Google for building and training neural networks. It offers flexibility and control but can be complex for beginners.
Keras is a high-level API built on top of TensorFlow that simplifies neural network creation. It provides pre-built layers, activation functions, and optimizers, making it easier and faster to prototype models.
Keras is beginner-friendly and great for small to medium projects, while TensorFlow is suited for large-scale, complex applications.
Deep Learning
Deep learning is a subset of machine learning that uses deep neural networks - networks with many layers - to learn from large amounts of data. These networks can automatically discover intricate structures in data without manual feature engineering.
Common Architectural Principles of Deep Networks
Parameters: These are the weights and biases in the network that get adjusted during training.
Layers: Neural networks have multiple layers - input, hidden, and output layers. Deep networks have many hidden layers, allowing them to learn complex features.
Activation Functions: These functions decide whether a neuron should be activated or not. Common examples include ReLU (Rectified Linear Unit) and sigmoid. They introduce non-linearity, enabling the network to learn complex patterns.
Loss Functions: These measure how far the network’s predictions are from the actual results. The goal of training is to minimize this loss.
Optimization Algorithms: Methods like gradient descent that adjust the network’s parameters to reduce the loss.
Hyperparameters: Settings like learning rate, number of layers, and number of neurons per layer that are set before training and influence the network’s performance.
Building Blocks of Deep Networks
Restricted Boltzmann Machines (RBMs): These are simple neural networks used for unsupervised learning, often as building blocks for deeper networks.
Autoencoders: Networks designed to learn efficient representations of data by compressing inputs into a smaller representation and then reconstructing the original input.
Variational Autoencoders (VAEs): A type of autoencoder that learns probabilistic representations, useful for generating new data similar to the input data.
Unsupervised Pretrained Networks
Unsupervised pretrained networks are special types of neural networks that learn patterns in data without needing labeled examples (where you already know the answers). They are often used to learn good initializations for deep networks, making training easier and more effective.
Deep Belief Networks (DBNs): These are stacks of simpler networks (called Restricted Boltzmann Machines) trained one layer at a time. Each layer learns to represent the data in a more abstract way, capturing complex patterns.
Generative Adversarial Networks (GANs): GANs consist of two networks competing against each other: a generator that creates fake data and a discriminator that tries to tell real data from fake. Through this competition, GANs learn to generate realistic data, like images or music, without needing labeled examples.
Convolutional Neural Networks (CNNs)
![A space and time efficient convolutional neural network for age group estimation from facial images [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2023/cs-1395/1/fig-1-2x.jpg)
CNNs are a type of neural network especially good at understanding images and visual data. They are inspired by how our brains process visual information.
Biological Inspiration & Intuition: CNNs mimic the way animals’ visual systems work, focusing on small parts of an image at a time and combining that information.
CNN Architecture Overview: A CNN is made up of several types of layers stacked together, each with a specific job.
Input Layers: These receive the raw data, like an image’s pixel values.
Convolutional Layers: These layers use small filters to scan across the input and pick out important features, like edges or patterns.
Pooling Layers: These layers reduce the size of the data, keeping only the most important information, which helps the network focus and speeds up processing.
Fully Connected Layers: Towards the end, these layers combine all the features learned so far to make a final decision, like recognizing a cat in a photo.
Other Applications of CNNs: Besides images, CNNs can be used for video analysis, speech recognition, and even analyzing time-series data.
Recurrent Neural Networks (RNNs)
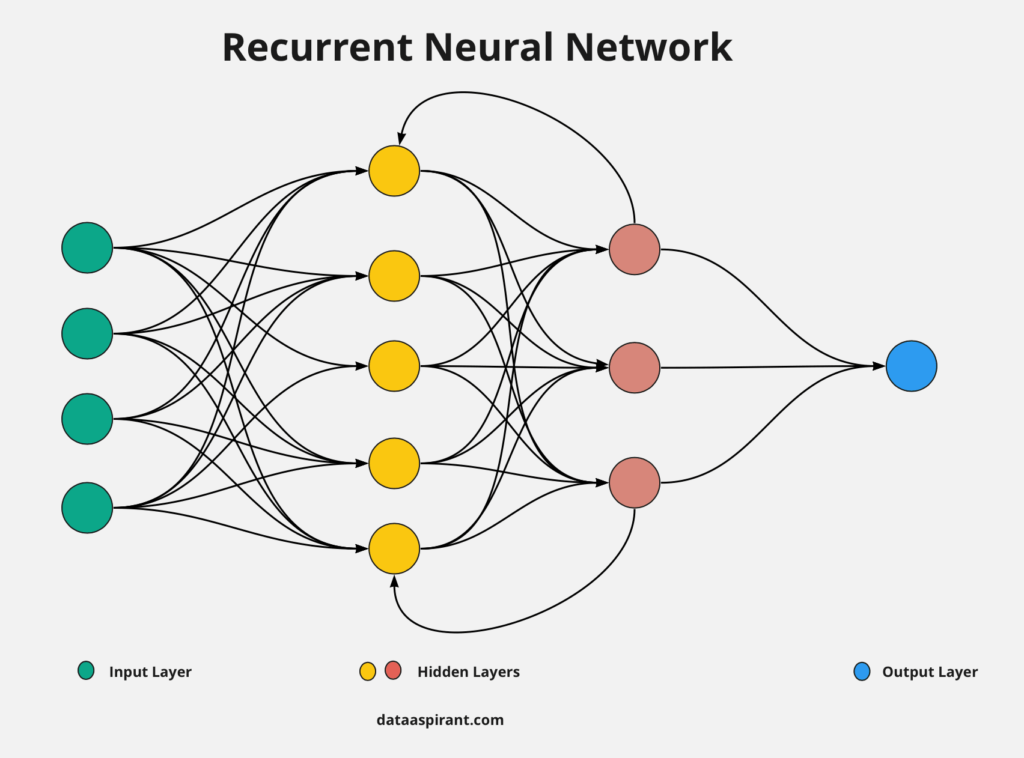
RNNs are designed to handle data that comes in sequences, like sentences, time-series, or audio. They can remember previous inputs, making them great for tasks where order matters.
Modeling the Time Dimension: RNNs process one piece of data at a time and keep track of what they’ve seen before, which is essential for understanding sequences.
3D Volumetric Input: Sometimes, RNNs are used with data that has more than two dimensions, like videos (which have width, height, and time).
Why Not Markov Models?: Markov models only remember the immediate past, but RNNs can remember longer histories, making them more powerful for complex sequences.
General RNN Architecture: RNNs have loops in their structure, allowing information to pass from one step to the next.
LSTM Networks: Long Short-Term Memory (LSTM) networks are a special kind of RNN that can remember information for even longer periods, solving the problem of forgetting important details over time.
Domain-Specific Applications and Blended Networks: RNNs are used in language translation, speech recognition, and more. Sometimes, they are combined with other network types to handle complex tasks.
Recursive Neural Networks

Recursive neural networks are a bit different-they work on data that has a hierarchical or tree-like structure, such as sentences broken down into phrases and words.
Network Architecture: Recursive networks apply the same set of weights repeatedly, combining smaller parts into bigger structures, like building up meaning from words to sentences.
Varieties of Recursive Neural Networks: There are different types, depending on the data and the problem, but all share the idea of working recursively through a structure.
Applications of Recursive Neural Networks: They are especially useful in natural language processing, such as understanding the grammatical structure of sentences or analyzing sentiment in text.
ntroduction to Deep Learning for Computer Vision
Computer vision is a field where computers are trained to interpret and understand images and videos. Deep learning has revolutionized this area using neural networks, especially Convolutional Neural Networks (ConvNets or CNNs).
Introduction to ConvNets
ConvNets (Convolutional Neural Networks) are a special type of neural network designed to process and analyze visual data like images.
They use layers that automatically detect patterns such as edges, shapes, and textures in images, making them excellent for tasks like recognizing objects or faces.
Training a ConvNet from Scratch on a Small Dataset
Training from Scratch: This means building and teaching a neural network using your own images, starting with random weights.
You feed the network many labeled images (for example, pictures of cats and dogs), and it gradually learns to distinguish between them by adjusting its internal settings (weights).
With a small dataset, the network may learn basic patterns, but it might not be as accurate as models trained on huge datasets.
Leveraging a Pretrained Model
Pretrained Model: Instead of starting from zero, you can use a model that has already been trained on a large dataset (like ImageNet, which has millions of images).
You then fine-tune this model for your specific task. This is much faster and often leads to better results, especially when you have limited data.
Object Detection with OpenCV
OpenCV is a popular open-source library for computer vision tasks.
It provides tools to detect and recognize objects in images and videos, such as finding faces in a photo or identifying moving cars in a video.
Real-time Object Detection with YOLOv8 (You Only Look Once)
YOLOv8 is a state-of-the-art algorithm for detecting multiple objects in images or videos very quickly.
"You Only Look Once" means the algorithm processes the whole image in one go, making it extremely fast and suitable for real-time applications like surveillance, robotics, or self-driving cars.
Deep Learning for Timeseries
Timeseries data is information collected over time, like stock prices, weather measurements, or heartbeats.
Different Kinds of Timeseries Tasks
Forecasting: Predicting future values based on past data (e.g., predicting tomorrow’s temperature).
Classification: Categorizing sequences (e.g., detecting if a heartbeat is normal or abnormal).
Anomaly Detection: Spotting unusual patterns (e.g., identifying equipment failure from sensor data).
Implementation of Temperature-Forecasting
This is a practical example of timeseries forecasting.
You collect past temperature readings and use a deep learning model (often a type of Recurrent Neural Network) to predict future temperatures.
The model learns patterns and trends from historical data to make accurate predictions.
Deep Learning for Text: Natural Language Processing (NLP)
NLP is a branch of AI focused on teaching computers to understand, interpret, and generate human language.
Preparing Text Data
Why preparation is needed: Raw text is messy. Computers can’t directly understand words-they need numbers.
Common steps: Cleaning the text (removing punctuation, lowercasing), removing stop words (common words like “the”, “is”), and converting words into numbers using techniques like tokenization (splitting text into words or subwords).
Two Approaches for Representing Groups of Words
Sets:
Treat words as a “bag,” ignoring the order.
Example: “cat sat mat” and “mat sat cat” are seen as the same.
Used in simple models like Bag-of-Words.
Sequences:
Keep the order of words, which is essential for meaning.
Example: “dog bites man” vs. “man bites dog” have different meanings.
Used in modern NLP models that need to understand context.
The Transformer Architecture
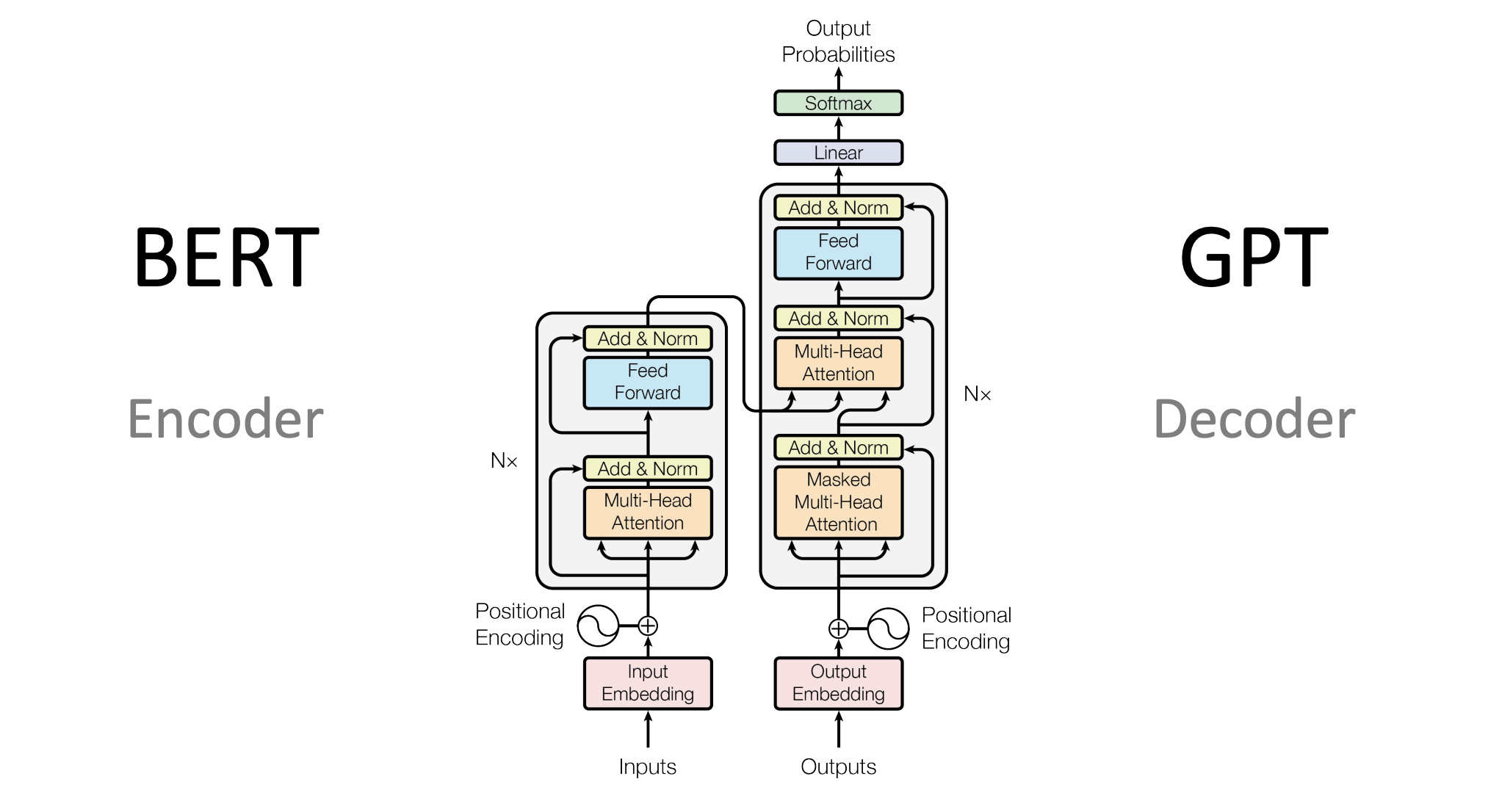
What it is: A powerful model introduced in 2017 that has revolutionized NLP.
How it works: Uses a mechanism called “attention” to focus on important words in a sentence, regardless of their position.
Why it matters: Transformers can understand context and relationships between words better than older models. They are the backbone of models like GPT (used by ChatGPT) and BERT.
Generative Deep Learning
This area is about creating new content-text, images, or even music-using deep learning models.
Text Generation
What it is: Teaching a model to write new text, such as stories, poems, or even code.
How it works: The model learns patterns from lots of text and generates new sentences that sound natural.
Neural Style Transfer
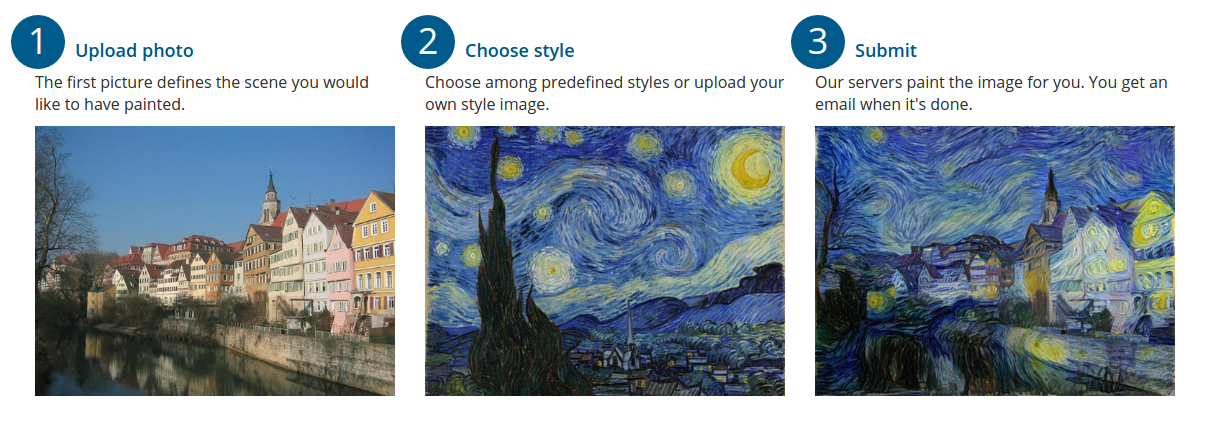
What it is: Combining the content of one image with the style of another.
Example: Making a photo of your dog look like it was painted by Van Gogh.
How it works: A neural network separates and recombines content and style from different images.
Generating Images with Variational Autoencoders (VAEs)
What it is: VAEs are special neural networks that can learn to compress data (like images) and then generate new, similar images.
How it works: The network learns the key features of the training images and can create new images by sampling from this learned representation.
Generative Adversarial Networks (GANs)
What it is: GANs are made of two networks-a generator and a discriminator-that compete with each other.
How it works: The generator tries to create fake images that look real, while the discriminator tries to tell real from fake. Over time, the generator gets so good that it can produce very realistic images.
Applications: GANs are used for creating art, generating realistic faces, and even making deepfakes.
Subscribe to my newsletter
Read articles from Aakashi Jaiswal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aakashi Jaiswal
Aakashi Jaiswal
Coder | Winter of Blockchain 2024❄️ | Web-Developer | App-Developer | UI/UX | DSA | GSSoc 2024| Freelancer | Building a Startup | Helping People learn Technology | Dancer | MERN stack developer