5 Techniques for Building a Robust Data Pipeline Architecture
 Tuanhdotnet
Tuanhdotnet5 min read
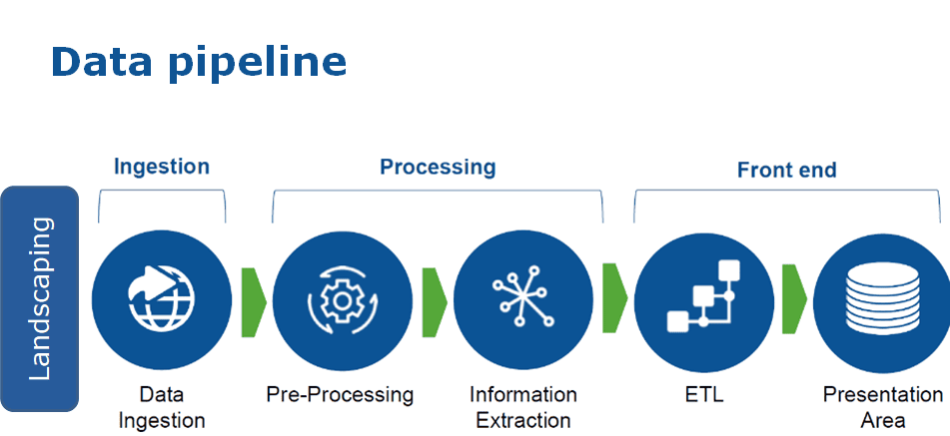
1. Key Components of a Data Pipeline Architecture
1.1 Data Sources
Data pipelines start with data sources, which might include databases, application APIs, log files, or third-party platforms. Selecting the right sources is crucial to ensure data relevancy. If you’re sourcing from an API, use a reliable client such as HttpClient in Java, which provides robust error handling and retries.
1.2 Data Ingestion Layer
The ingestion layer is where raw data flows into the pipeline. Tools like Apache Kafka or AWS Kinesis are popular choices for handling large-scale data. For example, with Kafka, you can set up multiple producers and consumers for real-time data ingestion:
// Kafka Producer Configuration
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my_topic", "key", "value"));
producer.close();
1.3 Data Transformation Layer
Data often requires cleaning and transformation before it becomes valuable. This might involve filtering null values, converting types, or standardizing formats. Using frameworks like Apache Spark for distributed data transformation is effective for large datasets. For instance:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Initialize Spark Session
spark = SparkSession.builder.appName("DataTransformation").getOrCreate()
# Load Data
data = spark.read.csv("data.csv", header=True)
# Transform Data
data_transformed = data.withColumn("new_col", col("existing_col") * 100)
data_transformed.show()
1.4 Data Storage Layer
Data storage solutions such as Amazon S3, Google BigQuery, or PostgreSQL are essential for storing processed data. Choose storage based on factors like cost, retrieval speed, and data structure. S3 is highly scalable for unstructured data storage, while BigQuery is better suited for structured data and large-scale analytics.
1.5 Data Analytics and Reporting
The analytics and reporting layer makes data accessible for decision-makers. Visualization tools such as Tableau or Looker can transform data into meaningful insights. This step may also involve data export to ML models or direct embedding into dashboards.
2. Data Quality and Validation Techniques
2.1 Validating Data During Ingestion
Validating data at the ingestion layer can prevent downstream errors. Implement validation checks on essential fields and ensure consistency in data format. Here’s a Java example for data validation:
import java.util.Arrays;
import java.util.List;
public class DataValidator {
public static void validate(List<String> data) throws Exception {
for (String field : data) {
if (field == null || field.isEmpty()) {
throw new Exception("Validation failed: field cannot be null or empty.");
}
}
}
public static void main(String[] args) {
try {
validate(Arrays.asList("data1", "data2", ""));
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.2 Using Schema Validation
Consider using schema validation with tools like Avro or Protocol Buffers, which allow you to define a data structure schema and validate against it. This helps maintain data consistency across different sources.
2.3 Data Quality Monitoring
Use a monitoring tool to track the quality of data flowing through the pipeline. Tools like Apache Griffin and Talend can automate data quality checks, providing alerts when anomalies are detected.
3. Error Handling and Logging
3.1 Building Resilient Pipelines with Retry Logic
Network issues and data source availability can cause transient errors. Implementing retry logic ensures that temporary failures don’t halt the pipeline. For example, using exponential backoff in Python:
import time
import requests
def fetch_data_with_retry(url, retries=5):
for i in range(retries):
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.exceptions.RequestException as e:
print(f"Attempt {i+1} failed. Retrying...")
time.sleep(2 ** i)
return None
3.2 Error Logging
Effective logging captures detailed error information, which helps debug issues. Use tools like Logstash or Elasticsearch for centralized logging. For example, with Log4j in Java:
<!-- Log4j configuration example -->
<Configuration>
<Appenders>
<File name="File" fileName="logs/pipeline.log">
<PatternLayout pattern="%d %p %C{1.} [%t] %m%n"/>
</File>
</Appenders>
<Loggers>
<Root level="error">
<AppenderRef ref="File"/>
</Root>
</Loggers>
</Configuration>
4. Ensuring Security and Compliance
4.1 Data Encryption
Encrypt data both in transit and at rest. Use TLS for data in transit and encryption services provided by cloud platforms for data at rest. Here’s an example of using Python’s cryptography library to encrypt sensitive data:
from cryptography.fernet import Fernet
# Generate and store a key
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# Encrypt data
plain_text = b"Sensitive data"
cipher_text = cipher_suite.encrypt(plain_text)
# Decrypt data
decrypted_text = cipher_suite.decrypt(cipher_text)
4.2 Access Control
Implement strict access controls, such as role-based access, to ensure only authorized users can access data. Use IAM policies for fine-grained access on platforms like AWS.
5. Real-Time Processing with Stream Processing
5.1 Stream Processing with Apache Kafka and Spark
Stream processing is essential for handling real-time data. With Kafka and Spark, you can build real-time analytics pipelines. Here’s an example of integrating Spark with Kafka:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
spark = SparkSession.builder
.appName("StreamProcessing")
.getOrCreate()
# Read from Kafka
df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test_topic")
.load()
# Process and write to console
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()
5.2 Batch Processing for Historical Data
For historical data analysis, use batch processing with tools like Apache Hive. This allows you to perform heavy analytical queries on large datasets without impacting real-time data flow.
6. Conclusion
Creating a robust data pipeline architecture is essential to handle the growing complexity and volume of data. By implementing best practices such as data validation, error handling, security measures, and the right processing techniques, you can build a resilient pipeline that ensures data quality and scalability. Feel free to leave a comment below if you have any questions or need further clarification on any of the techniques discussed.
Read more at : 5 Techniques for Building a Robust Data Pipeline Architecture
0
Subscribe to my newsletter
Read articles from Tuanhdotnet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tuanhdotnet
Tuanhdotnet
I am Tuanh.net. As of 2024, I have accumulated 8 years of experience in backend programming. I am delighted to connect and share my knowledge with everyone.