AI Hardware Series : Introduction (Part 1)
 LB
LBTable of contents
- Posts in this Series
- Table of Contents
- 1. Introduction
- 2. AI Systems
- 3. Hardware Provider Ecosystem
- 1.1 Emergence of Computer Architectures
- 1.1.1 What is Von Neumann bottleneck ?
- 1.1.2 SIMD (Single Instruction Multiple Data)
- 1.1.3 MIMD (Multiple Instruction, Multiple Data)
- 1.1.4 Systolic
- 1.2.1 Evolution of AI and Compute Needs
- Overview of AI Computation
- 1.2.2 Computations of Neural Network:
- 1.2.3 Computations of Transformer:
- 1.2.4 CNNs (vs) LLMs Computation Comparision
- 1.2.5 What Makes AI Workloads Unique?
- 1.2.6 Categories of AI Workloads
- 1.3 Key Metrics in AI Computation
- 2.1 Why Specialized Hardware Matters
- 2.2 Software-Hardware Co-Design
- 3. Hardware Ecosystem
- 3. 1 Data Center Chips
- 3.2 Mobile AI chip providers
- 3.3 Edge AI Chips

Posts in this Series
Introduction to AI Hardware (This Post)
CPU vs GPU vs TPU vs NPU
Memory (Caches, Main Memory (SRAM, DRAM) and Storage (Flash Memory)
DL Frameworks & Compilers
ASICs for AI (Groq, Cerebras, etc.)
Parallelism and Pipelining in AI Hardware
Interconnects and High-Speed Networking (ARM protocols, NVLink, PCIe, etc.)
Power, Thermal & Cost Considerations
Benchmarking AI Hardware (MLPerf, inference/training FLOPS)
Table of Contents
1. Introduction
1.1 Emergence of Computer Architectures
1.1.1 What is Von Neumann bottleneck ?
1.1.2 SIMD
1.1.3 MIMD
1.1.4 Systolic
1.2 Evolution of AI and Compute Needs
1.2.1 ML/DL/Gen AI
1.2.2 Computations of Neural Network
1.2.3 Computations of Transformer
1.2.4 CNNs (vs) LLMs Computational Needs
1.2.5 What makes AI workloads Unique ?
1.2.6 Types of AI workloads
1.3 Metrics to measure in AI Computation
2. AI Systems
2.1 Why Specialized Hardware Matters ?
2.1 Software-Hardware Co-Design
3. Hardware Provider Ecosystem
3.1 Data Center Chip
3.2 Mobile or On-Device AI chip
3.3 Edge AI chip
1.1 Emergence of Computer Architectures
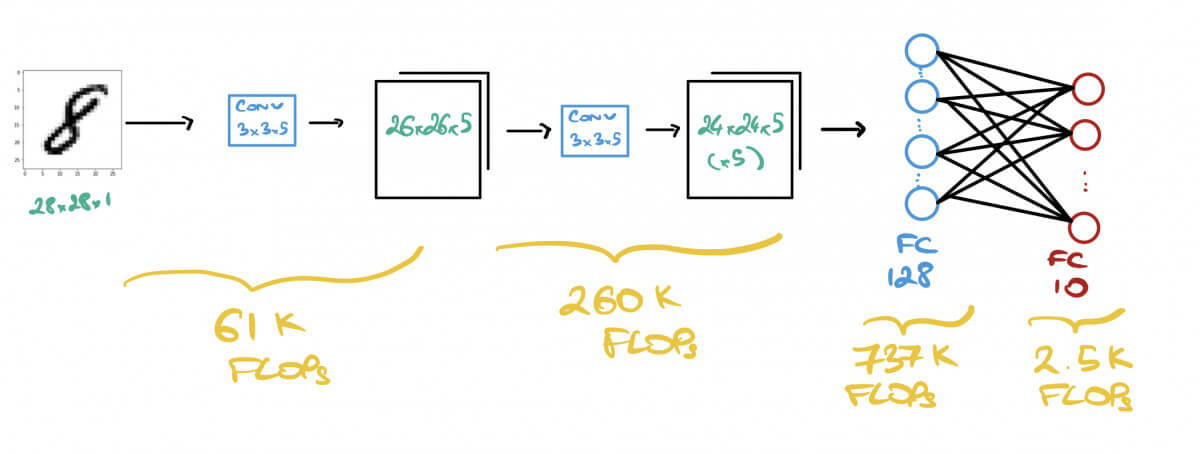
Traditional computing architectures, built around the Von Neumann model, face a bottleneck where data must constantly move between memory and processing units which is inefficient for AI workloads.
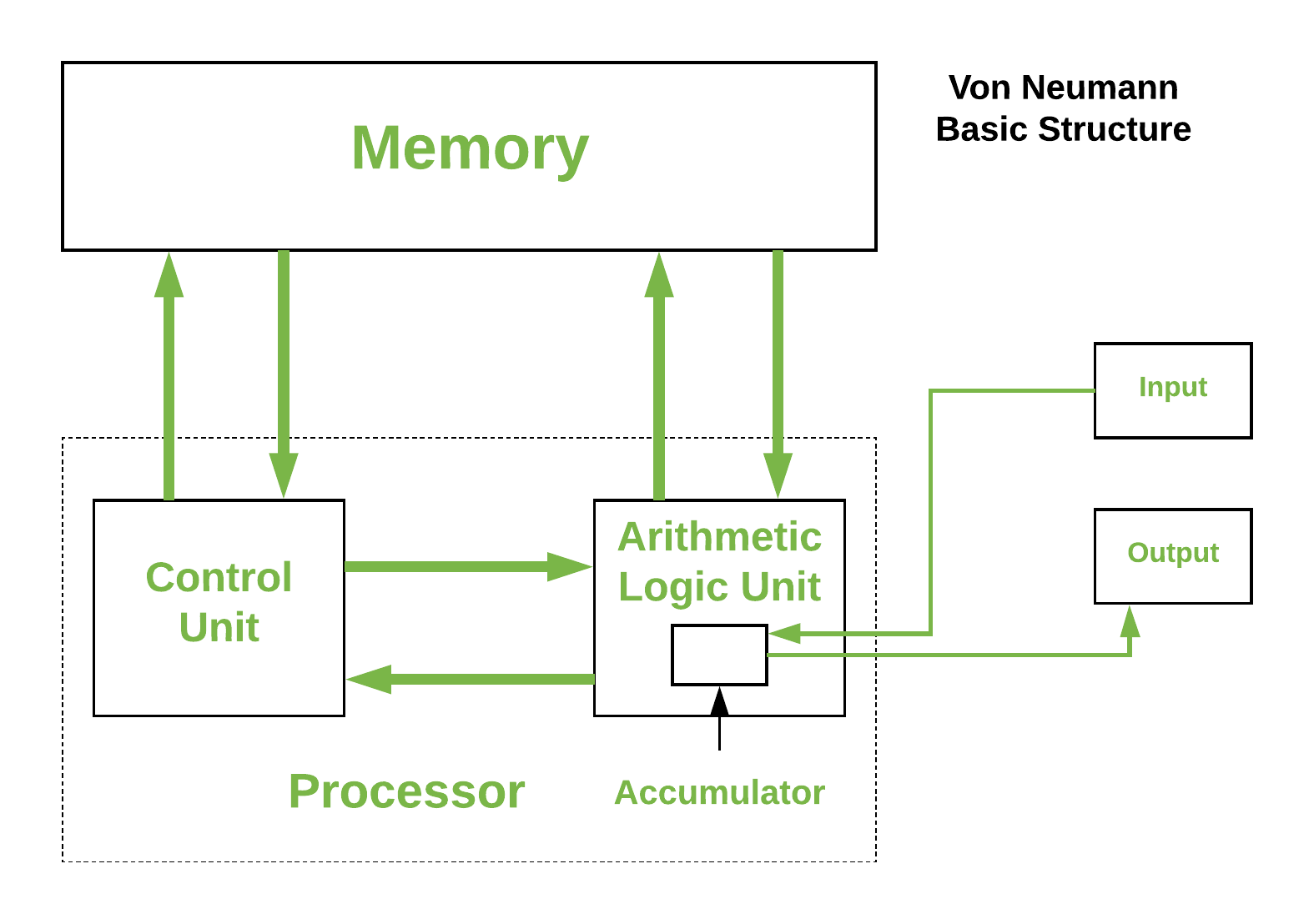
The structure described in the figure outlines the basic components of a computer system, particularly focusing on the memory and processor. Here’s a breakdown of the components:
Memory: This is where data and instructions are stored. It is a crucial part of the computer system that allows for the storage and retrieval of information.
Control Unit: This component manages the operations of the computer. It directs the flow of data between the CPU and other components.
Arithmetic Logic Unit (ALU): The ALU performs arithmetic and logical operations. It is responsible for calculations and decision-making processes.
Input: This refers to the devices or methods through which data is entered into the computer system.
Output: This refers to the devices or methods through which data is presented to the user or other systems.
Processor: The processor, or CPU, is the central component that carries out the instructions of a computer program. It includes the ALU and Control Unit.
Accumulator: This is a register in the CPU that stores intermediate results of arithmetic and logic operations.
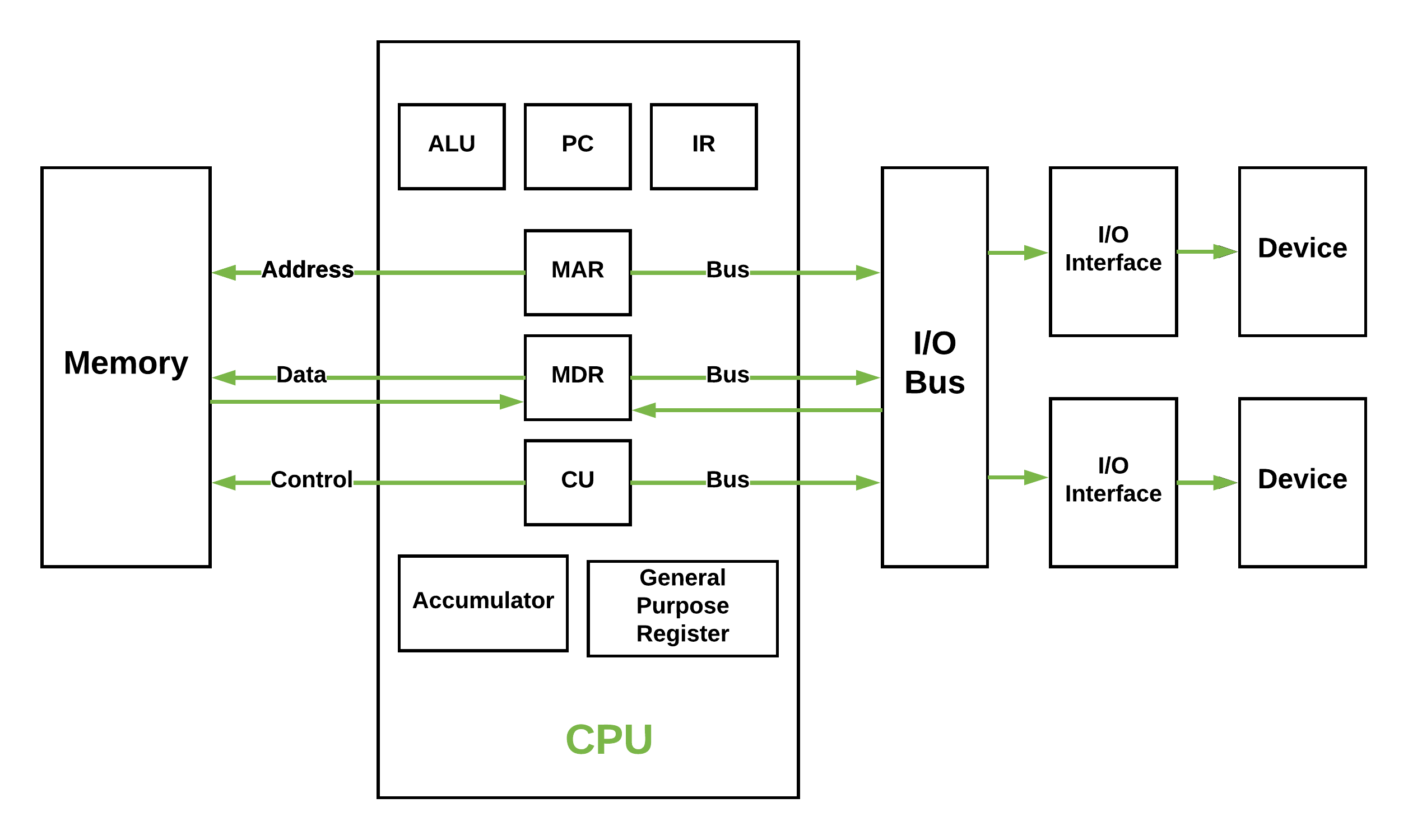
1.1.1 What is Von Neumann bottleneck ?
After many experiments scientists did to enhance performance they cannot get away from the fact that instructions can only be done one at a time and can only be carried out sequentially as you see above.
To address the bottlenecks in traditional architecture, AI systems adopt more parallel and specialized architectures:
1.1.2 SIMD (Single Instruction Multiple Data)
is a specialized type of computer architecture in which the processors perform all calculations on a series of data at one time. This architecture is ideal for those applications that involve the same operation to be done on large sets such as multimedia and scientific simulations. The SIMD can be done on different types of hardware such as; the CPU with simultaneous multiple data hardware such as the Intel SSE or the AVX and the GPU hardware.
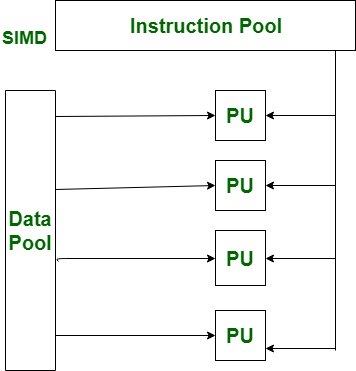
1.1.3 MIMD (Multiple Instruction, Multiple Data)
is a type of parallel processing where in many processors handle various instructions on various data at the same time. This architecture allows for a great degree of adaptability and the system can be used for a wide range of applications, from realistic modeling to multi-threaded program. MIMD systems find more application in the current multi-core processors and distributed computational platforms.

1.1.4 Systolic
Systolic Arrays used in TPUs, minimize memory movement by passing data rhythmically between processors—great for matrix multiplications.
In a systolic array, there are a large number of identical simple processors or processing elements(PEs) that are arranged in a well-organized structure such as a linear or two-dimensional array. Each processing element is connected with the other PEs and has limited private storage.
Systolic Array Applications
| Application | Example |
| Digital Signal Processing | Image and Video processing, speech recognition, data compression |
| Neural Networks | Convolutional Neural Networks, Recurrent Neural Networks, Deep Belief Networks |
| Cryptography | Symmetric Key Encryption, Hash Functions |
| Computer Vision | Object detection and recognition, Facial Recognition, Video analytics |
1.2.1 Evolution of AI and Compute Needs

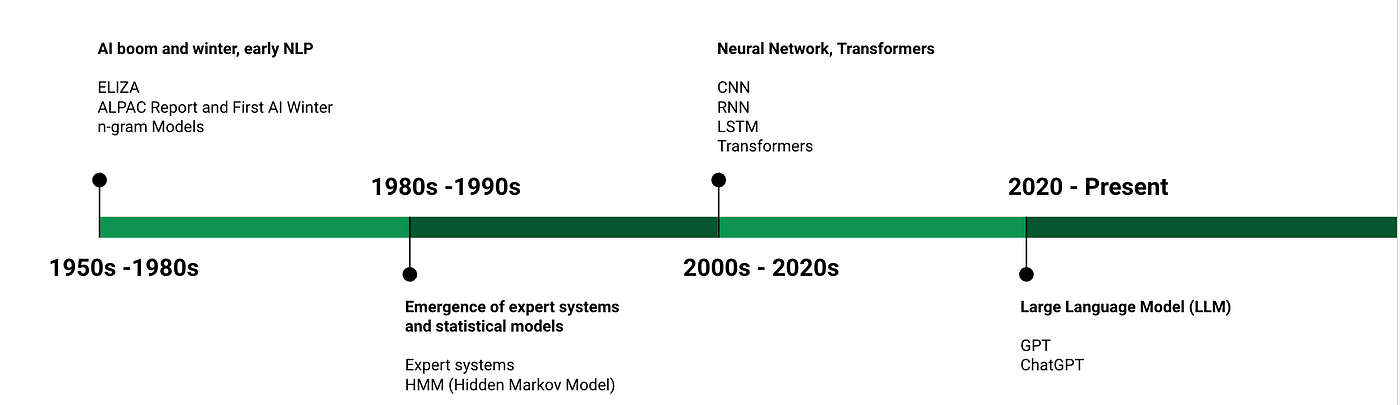
In the above picture we can see the fundamental differences of ML, DL and Gen AI and how AI as a field evolved over years.
ML - train a machine to solve specific problem (mainly predictive analysis to predict future based on past inputs)
DL - using neural network to solve an AI problem (vision and speech models revolutions started from here because DL models can be used to synthesize for feature level understanding and extraction)
Gen AI - the era of machines reaching human intelligence (enabled creativity through pattern recognition and since the gen ai can take input of multiple data types the applications has become enormous and almost every industry is empowered)
Overview of AI Computation
AI computation refers to the processing tasks required to train and run artificial intelligence models—especially DL models like convolutional neural networks, and GenAI models such as transformers, large language models (LLMs). These tasks are data- and compute-intensive, often requiring specialized hardware and software optimizations to perform efficiently.
To understand the NNs and transformer working and computations please refer to below videos:
1.2.2 Computations of Neural Network:
1.2.3 Computations of Transformer:
If you’ve watched the above videos, you probably have a good grasp of what I mean by “parameters” in the context of AI models.
If not, no worries — let’s break it down.
In simple terms, parameters are the internal variables that a model learns during training — they define the model’s knowledge. Think of them as the knobs and weights the model adjusts to make better predictions. The more parameters, the more capacity a model has to learn complex patterns, though more isn’t always better.
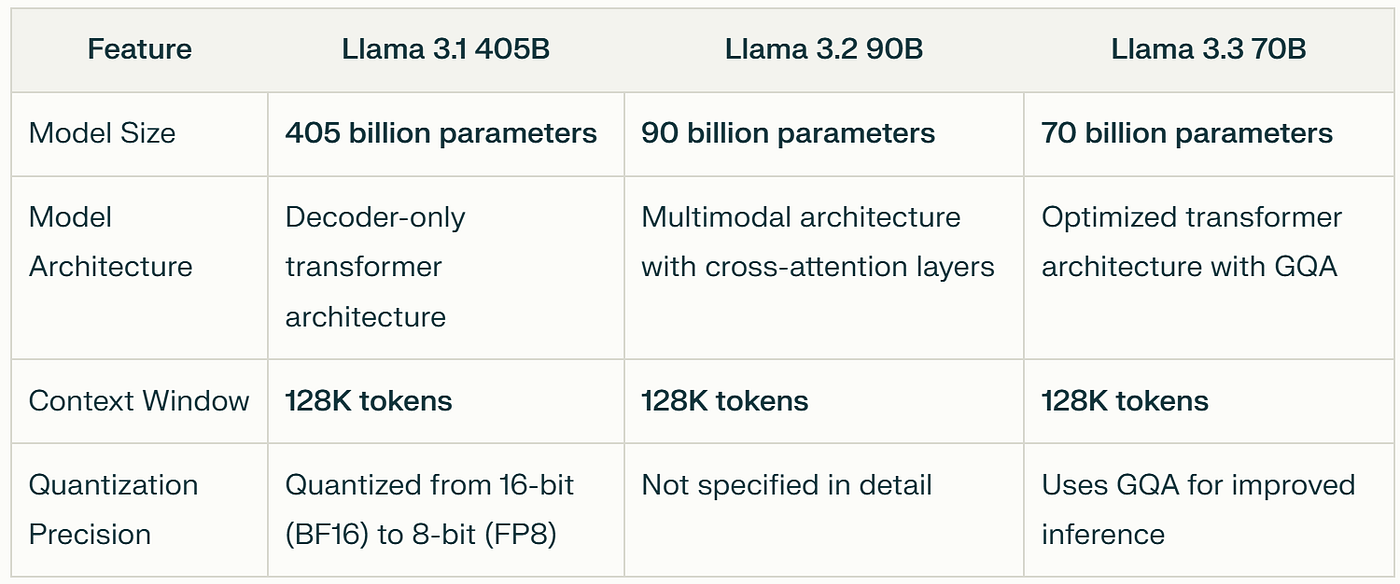
1.2.4 CNNs (vs) LLMs Computation Comparision
Early models like CNNs for vision tasks demanded high parallelism for convolutional operations, which GPUs handled efficiently.

Modern LLMs like GPT and LLaMA require trillions of parameters, petaflop-scale compute, and sophisticated parallelism strategies (model, tensor, and pipeline parallelism), marking a clear departure from the compute patterns of earlier AI workloads.
1.2.5 What Makes AI Workloads Unique?
AI workloads stand apart from traditional compute tasks due to their reliance on massive matrix multiplications and tensor operations, which require high degrees of parallelism and compute density. These tasks often push both memory and computational limits, with some models being memory-bound (like recommendation systems) and others compute-bound (like large vision transformers).
- Matrix multiplications & tensor ops
1.2.6 Categories of AI Workloads
- Memory Intensive and Compute Intensive
Workloads can generally be categorized into training where models learn from data—and inference, where they make real-time or batch predictions. The diversity of use cases, from natural language processing (NLP) and computer vision to recommendation engines, introduces varying demands on latency, throughput, and resource usage. Training typically emphasizes throughput and scale, while inference often requires low-latency performance, especially in real-time applications like voice assistants or fraud detection.
AI workloads are distinct due to their reliance on matrix multiplications and tensor operations, demanding high parallelism and extensive compute-memory coordination. These workloads typically fall into two broad categories:
Training vs Inference
Training is compute-intensive, involving large-scale data, backpropagation, and model updates.
Inference is latency-sensitive, requiring quick predictions with pre-trained models.
Domain-Specific Applications
Natural Language Processing (NLP): Processes sequential data like text or speech, often needing large transformer models.
Computer Vision: Works with images/videos, typically using CNNs and vision transformers.
Recommendation Systems: Operate on structured data, relying heavily on embeddings and memory access.
Processing Modes
Real-Time: Used in applications like autonomous vehicles and chatbots — low-latency critical.
Batch Processing: Suitable for offline training or analytics where throughput matters more than speed.
1.3 Key Metrics in AI Computation
Training Metrics
FLOPS (Floating Point Operations Per Second):
Measures raw computational power. TeraFLOPS (10¹²), PetaFLOPS (10¹⁵), and ExaFLOPS (10¹⁸) indicate how many operations a system can perform per second — crucial for large-scale model training.
High FLOPS in neural network computation means the system can perform a large number of floating-point operations per second, enabling faster training and inference of complex models.
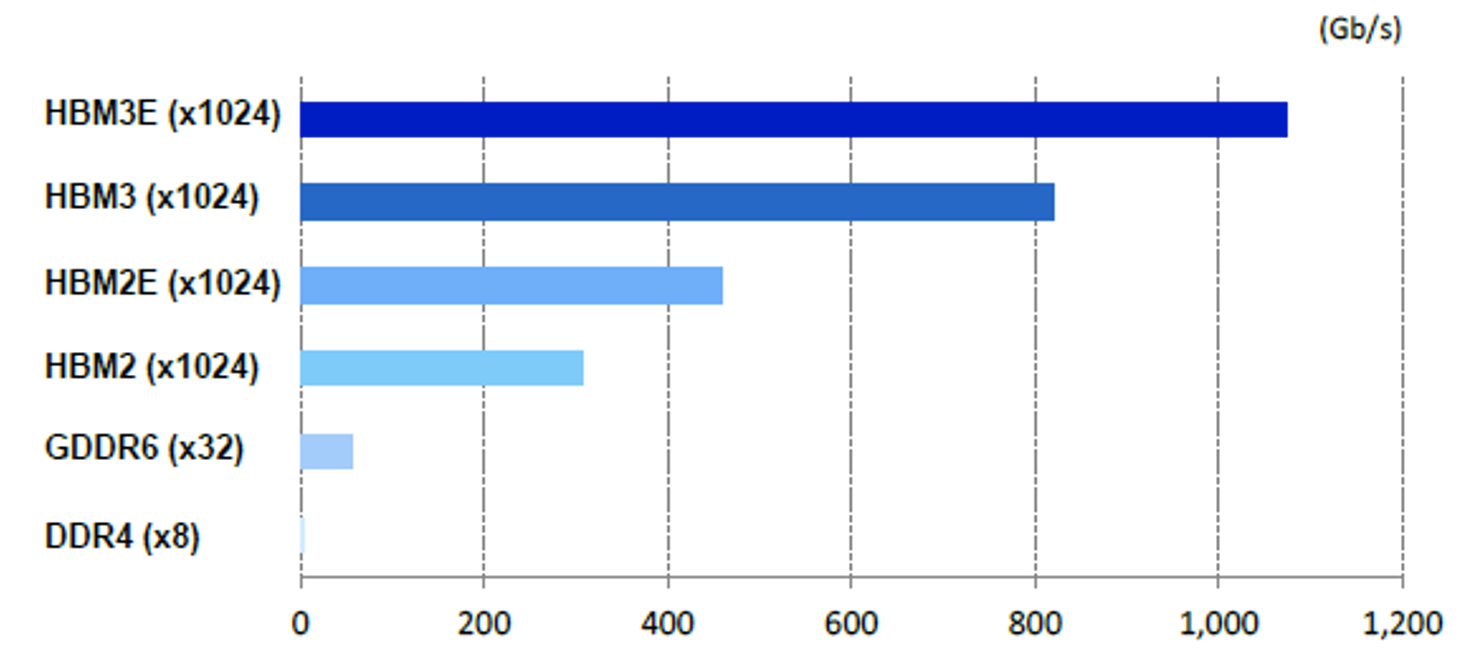
Memory Bandwidth (Gbps) :
Refers to the speed at which data can be transferred between memory and compute units. AI workloads, especially LLMs, are memory-hungry, and high bandwidth is essential to prevent bottlenecks.
- High memory bandwidth in neural network computation means data (like weights and activations) can be transferred quickly between memory and processors, preventing bottlenecks and maximizing compute efficiency.
Inference Metrics
Latency (ms) :
- How fast a single input (like an image or sentence) passes through the network and produces an output — critical for real-time tasks like chatbots or autonomous driving.
Throughput (data/sec) :
- How many inputs (e.g., images, tokens) the network can process per second — important for training large models or handling bulk inference.
Energy Efficiency (power consumed):
- How much power is used to run the model — affects battery life on edge devices and operational cost in data centers.
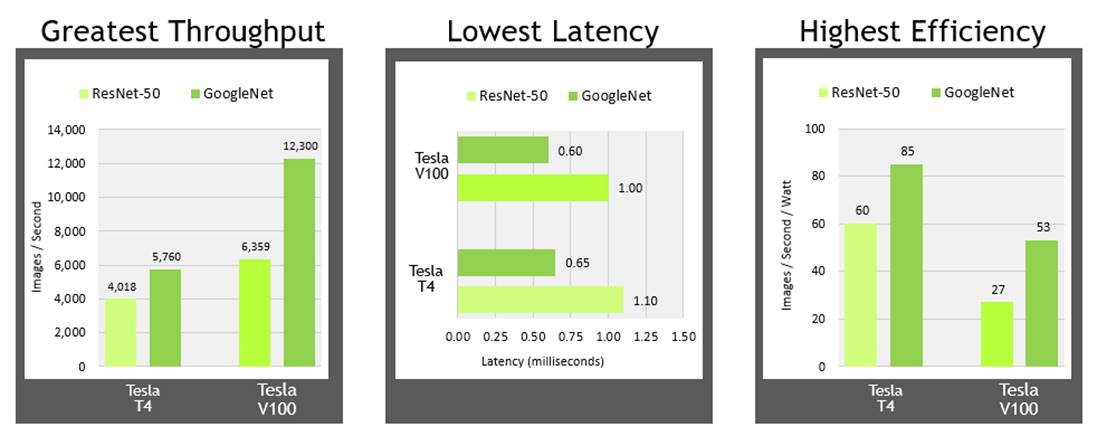
2.1 Why Specialized Hardware Matters
Efficiency vs Flexibility Trade-off
AI workloads are highly parallel and math-intensive, especially during training phases. Specialized hardware like GPUs, TPUs, and custom ASICs are designed to handle matrix multiplications and tensor operations with high throughput, leading to better performance and energy efficiency. However, this efficiency comes at the cost of flexibility. General-purpose CPUs, though slower for AI-specific tasks, can handle a broader range of operations. Choosing between general-purpose and specialized hardware depends on the task: real-time inference at the edge might favor smaller accelerators, while large-scale training benefits from powerful but less flexible chips.
Scaling Laws and Cost Implications:
Modern AI models—from CNNs to LLMs—scale with more data, larger parameter sizes, and deeper architectures. According to AI scaling laws, performance tends to improve predictably with increased compute, but this also leads to rapidly rising costs in terms of compute time, power consumption, and hardware investment. Training massive models like GPT-4 or LLama 3 requires infrastructure that can handle exaflop-scale workloads and high memory bandwidth—making cost-effective scaling a core concern for researchers and industry.
Push Toward Domain-Specific Accelerators
To meet the demands of ever-growing models, the industry is moving toward domain-specific accelerators. These include Google’s TPUs, Graphcore’s IPUs, and other AI-focused ASICs, which are architected specifically for neural network operations. By optimizing hardware around the unique dataflows and compute patterns of AI, these chips achieve significant gains in throughput and energy efficiency. As the AI ecosystem matures, co-designing models and hardware together—rather than treating them as separate layers—will be crucial for sustaining progress.
2.2 Software-Hardware Co-Design
1. AI Models (Software Side)
Model Architecture Design: CNNs, RNNs, Transformers, etc.
Model Optimization Techniques:
Pruning: Remove unnecessary weights
Quantization: Lower precision (e.g., FP32 → INT8)
Knowledge Distillation: Train a smaller model using a large one
Training & Inference Pipelines: The end-to-end data flow from input to prediction
2. AI Frameworks
TensorFlow, PyTorch, JAX: Allow developers to define models
Graph Compilers & Runtimes:
XLA, TVM, TensorRT, ONNX Runtime
Optimize model graphs for hardware-specific instructions
Operator Libraries:
- Highly optimized backend functions (e.g., cuDNN for NVIDIA)
3. Hardware Accelerators
GPUs (NVIDIA), TPUs (Google), NPUs, FPGAs, ASICs
Compute Units: Tensor cores, matrix units, systolic arrays
Memory Hierarchy: On-chip cache, HBM, SRAM vs DRAM
Interconnects: NVLink, PCIe, etc.
4. Compiler and Scheduler Layer
Translates framework graphs to hardware-friendly code
Handles:
Kernel fusion
Instruction-level scheduling
Memory management
Parallelism (data/model pipeline)
5. Performance & Energy Optimization
Tuning model for hardware limits:
- FLOPS, memory bandwidth, latency
Thermal and energy constraints
Hardware-aware training: Training models directly under hardware constraints
6. Feedback Loop (Co-Design)
Real-world profiling of model performance on silicon
Adjust model and software stack based on hardware bottlenecks
Iterate design for optimal balance of speed, accuracy, cost, and efficiency
What is a Framework (in AI)?
AI framework is a software library that simplifies the development, training, and deployment of machine learning models by providing pre-built components like layers, loss functions, and optimizers. It abstracts away complex mathematical operations, handles automatic differentiation (crucial for backpropagation), and efficiently interfaces with hardware like GPUs and TPUs.
- Frameworks such as PyTorch, TensorFlow, and JAX help developers focus on model architecture and problem-solving rather than low-level code, making them essential tools in both research and production environments.
What is a Compiler (in AI)?
A compiler is a tool that translates high-level code (like Python with TensorFlow or PyTorch) into low-level instructions that a machine (like a GPU or TPU) can understand and execute efficiently.
In AI, specialized compilers are:
XLA (Accelerated Linear Algebra) for TensorFlow
TVM (open-source deep learning compiler stack)
TensorRT for NVIDIA GPUs
In short, compilers in AI speed up and adapt your model to run better on specific hardware.
3. Hardware Ecosystem

3. 1 Data Center Chips
| Vendor | Category | Selected AI chip* |
| NVIDIA | Leading producer | Blackwell Ultra |
| AMD | Leading producer | MI400 |
| Intel | Leading producer | Gaudi 3 |
| AWS | Public cloud & chip producer | Trainium3 |
| Alphabet | Public cloud & chip producer | Ironwood |
| Alibaba | Public cloud & chip producer | ACCEL** |
| IBM | Public cloud & chip producer | NorthPole |
| Huawei | Public cloud & chip producer | Ascend 920 |
| Groq | Public AI cloud & chip producer | LPU Inference Engine |
| SambaNova Systems | Public AI cloud & chip producer | SN40L |
| Microsoft Azure | Public AI cloud & chip producer | Maia 100 |
| Untether AI | Public AI chip producer | speedAI240 |
| Apple | Chip producer | M4 |
| Meta | Chip producer | MTIA v2 |
| Cerebras | AI startup | WFE-3 |
| d-Matrix | AI startup | Corsair |
| Rebellions | AI startup | Rebel |
| Tenstorrent | AI startup | Wormhole |
| _etched | AI startup | Sohu |
| Extropic | AI startup | |
| OpenAI | Upcoming producer | TBD |
| Graphcore | Other producers | Bow IPU |
| Myhtic | Other producers | M2000 |
3.2 Mobile AI chip providers
Last Updated at 12-23-2024
| Vendor | Selected Chips* | Used in |
| Apple | A18 Pro, A18 | iPhone 16 Pro, iPhone 16 |
| Huawei | Kirin 9000S | Huawei Mate 60 series |
| MediaTek | Dimensity 9400, Dimensity 9300 Plus | Oppo Find X8, Vivo X200 series, Samsung Galaxy Tab S10 Plus, Tab S10 Ultra |
| Qualcomm | Snapdragon 8 Elite (Gen 4), Snapdragon 8 Gen 3 | Samsung Galaxy S25 Ultra, Xiaomi 14, OnePlus 12, Samsung Galaxy S24 series |
| Samsung | Exynos 2400, Exynos 2400e | Exynos 2400, Exynos 2400e |
3.3 Edge AI Chips
The demand for low-latency processing has driven innovation in edge AI chips. These chips’ processors are designed to perform AI computations locally on devices rather than relying on cloud-based solutions:
Last Updated at 04-21-2025
| Chip | Performance (TOPS)* | Power Consumption | Applications |
| NVIDIA Jetson Orin | 275 | 10-60W | Robotics, Autonomous Systems |
| Google Edge TPU | 4 | 2W | IoT, Embedded Systems |
| Intel Movidius Myriad X | 4 | 5W | Drones, Cameras, AR Devices |
| Hailo-8 | 26 | 2.5-3W | Smart Cameras, Automotive |
| Qualcomm Cloud AI 100 Pro | 400 | Varies | Mobile AI, Autonomous Vehicles |
Subscribe to my newsletter
Read articles from LB directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
LB
LB
Lekhana is a T-shaped Product Manager with roots in AI/ML and a flair for creativity. From building products and leveraging latest technology, she focuses on solving problems and delivering user-centric experiences that bring impact and drive measurable results. In the past 3+ years, she wore multiple hats as an ML solutions engineer, consultant and a PM helping companies in digital transformation, security challenges and growth.