DBT : Transforming Modern Data Workflows
 Pushkar Dandekar
Pushkar DandekarIn today's data-driven landscape, organizations are constantly seeking more efficient ways to transform raw data into actionable insights. One tool that has gained significant traction among data professionals is DBT (Data Build Tool). As someone who recently completed specialized training in this technology, I'd like to share insights about what DBT is, why it matters, and how it's changing the data engineering landscape.

What is DBT?
DBT is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouses by writing SQL select statements. Unlike traditional ETL tools that require learning proprietary languages or interfaces, DBT leverages SQL—a language most data professionals already know—and adds the power of software engineering best practices to data transformation workflows.
At its core, DBT is a transformation tool that sits between your raw data in the data warehouse and your business intelligence tools. It allows teams to build modular, version-controlled, and tested data transformation pipelines using nothing but SQL.
The Shift from ETL to ELT (and Where DBT Fits)
To understand DBT's significance, we need to recognize the industry's shift from ETL (Extract, Transform, Load) to ELT (Extract, Load, Transform) workflows.
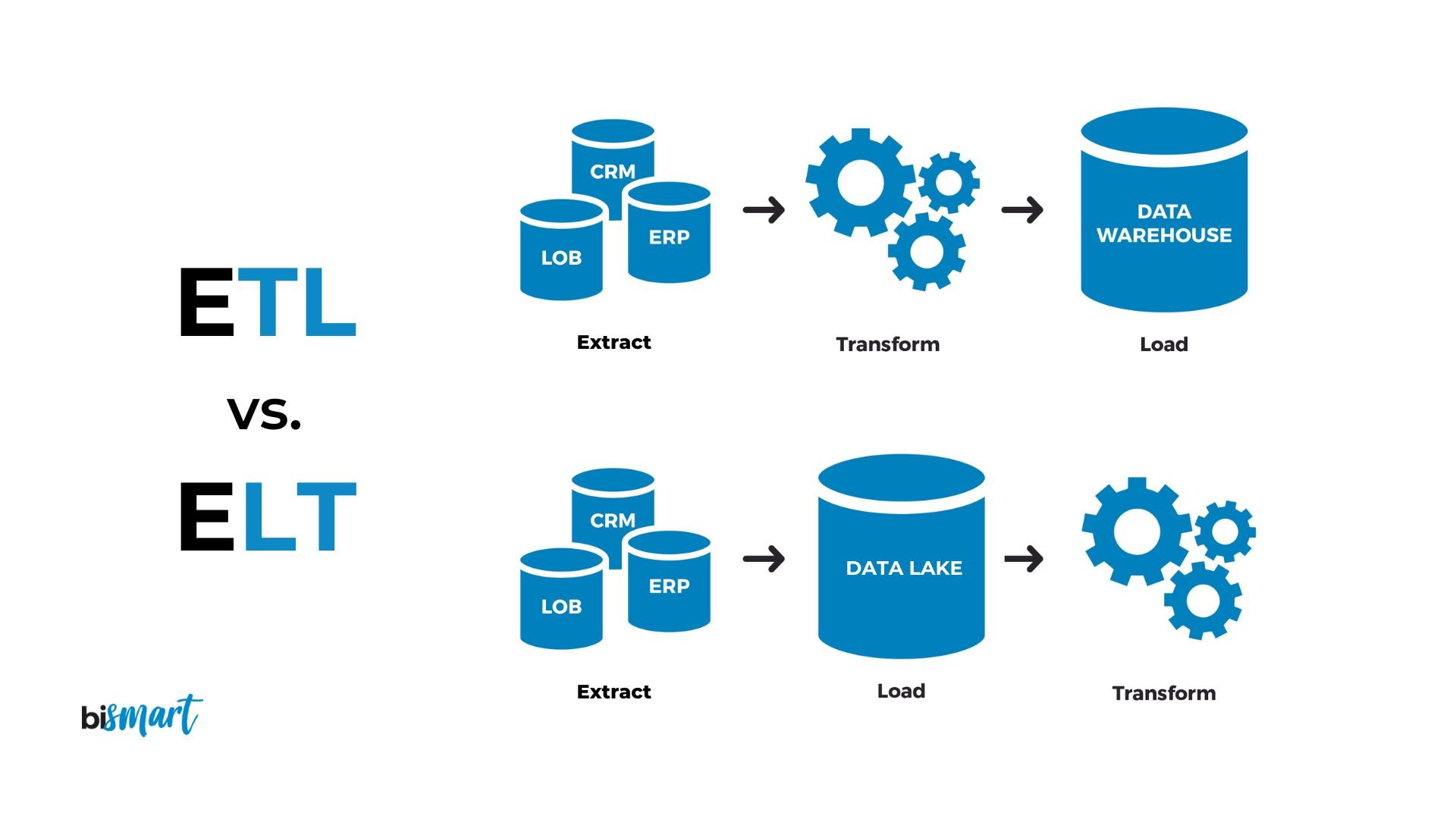
Traditional ETL
In the ETL approach:
Data transformation occurs prior to loading it into the destination system
This process requires separate servers and middleware infrastructure
It's suited for legacy systems and smaller data volumes
Pre-validated data means fewer downstream errors
However, it offers limited flexibility
Modern ELT
The ELT approach, which DBT facilitates, works differently:
Raw data is loaded first, enabling multiple transformation versions from the same source
It leverages modern DWH computing power for transformations
It scales effectively with big data volumes
Source data lives alongside transformed views, improving data integrity
It's more cost-effective by eliminating separate transformation infrastructure
Where DBT Comes Into Picture
DBT thrives in the ELT paradigm by focusing exclusively on the transformation layer. Unlike traditional tools that handle the entire data pipeline, DBT specializes in what happens after your raw data reaches the warehouse.
DBT transforms raw data from your data warehouse into analytics-ready datasets by executing SQL transformations in a specific order, creating a modular and version-controlled transformation layer between your raw data and BI tools.

Key Issues DBT Resolves
Data transformation has historically been plagued by several challenges that DBT effectively addresses:
Lack of testing and documentation: Traditional data transformation processes often lack proper testing frameworks and comprehensive documentation, leading to reliability issues and knowledge gaps.
Repetitive stored procedure code: Before DBT, many organizations relied on stored procedures that were difficult to maintain and required constant rewriting.
Hard-to-understand transformation code: Complex transformations were often obscured in proprietary systems or buried in difficult-to-understand code.
DBT resolves these issues by enabling SQL-based work on data pipelines using software engineering best practices:
DBT is SQL first: It compiles SQL code and sends it to your data warehouse to run
It enforces data documentation
It implements software engineering best practices including testing, version control, and documentation
It manages data lineage and dependency management
DBT code is stored in git providers for proper versioning
Advantages of DBT
The advantages of incorporating DBT into your data stack are numerous:
SQL-centric approach: DBT allows data teams to work with SQL, a language they already know, rather than forcing them to learn proprietary languages or interfaces.
Modularity: Models in DBT can be built on top of each other, creating a clean, maintainable, and modular codebase.
Testing capabilities: DBT includes built-in testing functionality to ensure data quality and consistency throughout your transformations.
Documentation: DBT generates documentation automatically from your models, making it easier for team members to understand the data structure.
Version control: All transformations are code-based and can be version-controlled, allowing for better collaboration and change tracking.
Data lineage: DBT provides visualization of your data models and their relationships, giving you clear visibility into how data flows through your system.
DBT Product Options
There are two main DBT product options available:
DBT Core
Open source
Focuses on developing, testing, and documentation
Python packages
Command-line interface
DBT Cloud
Cloud platform with web IDE
Runs dbt core
Offers complex features for CI/CD, SLAC environments, notifications, etc.
Final Thoughts
As data volumes continue to grow and organizations increasingly rely on data-driven decision making, tools like DBT are becoming essential components of the modern data stack. By bringing software engineering practices to data transformations, DBT helps teams produce more reliable, maintainable, and collaborative data pipelines.
The shift from ETL to ELT represents more than just a change in workflow—it's a fundamental rethinking of how we approach data transformation. DBT sits at the heart of this transformation, empowering data teams to work more efficiently and effectively.
Whether you're a data analyst looking to adopt more engineering best practices or a data engineer seeking to standardize your transformation layer, DBT offers a compelling solution that bridges the gap between raw data and actionable insights.
Subscribe to my newsletter
Read articles from Pushkar Dandekar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by