What about an open-source #BigTech style development ecosystem for Go?
 Emiliano Arcamone
Emiliano Arcamone
Futile Introduction
I had to take some time out from my career to take care of a family business and I thought it was a great opportunity to have fun coding an open-source project, moreover to avoid my fingers from oxidizing until this prolonged break finished.
So I thought.. wouldn’t it be cool to have a clone and forget development ecosystem, similar to those you might find in #BigTech companies, that would be flexible enough for lone freelancer wolves too, that we can clone and forget, just focus in adding our APIs handlers code and everything else around it will be magically handled for us?
In this article, I will be presenting this project I had been working for a while now, with this simple yet ambitious goal in mind.
So what is a #BigTech development ecosystem?
If you worked in one of these companies, you probably are already guessing what I mean with that, but just in case, let’s first dive over what I mean.
These companies tend to have hundreds of different teams, each one maintaining their own APIs, the integrity of their development cycle and the deployment process to production.
Now, having so many isolated teams developing and deploying APIs in the same ecosystem could potentially expose the whole ecosystem to unintended harmful actions from the developers, thus companies have entire teams working in things like standardization of processes, best practices and their enforcement, reusable frameworks and different layers of abstractions to safely sandbox developers to prevent them from performing unintended harm to the ecosystem.
So, as you can imagine, each company has their own tailored ecosystem to handle these processes, and it might be actually impossible to pretend to have an open-source project that could replace each of them, but there are for sure certain aspects they all share that we can attempt to have a -hopefully- decent integral alternative:
Integrity of the development cycle:
Usually enforced through a CI Pipeline that gets automatically triggered when a Pull Request is created for new feature branches, this process attempts to validate lots of different aspects to ensure the integrity of the code base, naming some common ones:
unit tests check and enforcement of minimum coverage thresholds
outdated dependencies, vulnerabilities and secrets code scan
code linting enforcement and maybe even the generation of cosmetic badges and evidence reports for each of these processes, just in case, for latter post-mortems and accountability.
Infrastructure and deployment isolation:
Depending on the size of the company, you might have direct access to the cloud platform console where your code is deployed with some strict policies to avoid unintended harm.
But normally, in #BigTech companies, you will have some type of layers to abstract developers from the infrastructure provisioning, setup and safe deployment strategies.
Some companies might even achieve this with beautiful home-made UI panels similar to those of cloud platforms, but tailored to their own ecosystems with their different layers of abstractions and services.
At the end of the day, developers simply release in their repositories a new version, which successfully passed the previously mentioned CI Pipeline, and then login in a panel where this new released version appears and a few clicks and minutes later, the new code is safely deployed to production, without them even maybe knowing the name of the underlying cloud platform, maybe more than one to guarantee up-time in those weird cloud total downtime events.
At the end of the day, developers are totally abstracted from load balances, number of instances, routing tables, security accesses and policies, infrastructure specs, etc. They just code, click and deploy.
Don’t reinvent the wheel
Even with the enforcement of the two previously mentioned processes, with hundreds of isolated teams coding APIs with same “chunks of actions”, it has no sense, at least from a performance, security and bugs avoidance point of view, to have each team develop their own chunks of code for the same repetitive actions, so we also tend to find in these companies frameworks at different levels to expedite the development process and enforcing the presence of specific normalized best practices and cross actions, naming some common ones:
ensuring APIs have a graceful shutdown process which the infrastructure isolation
process previously mentioned leverages for safe deployments without down-timereusable rest-clients with in-house cross metrics to quickly
pinpoint weird or unperforming API behaviors by cross SRE teamsreusable middlewares enforcing critical ecosystem
operations like APIs distributed Rate-Limiting, etc.
At the end of the day, developers will always end up cloning “modules” maintained by a cross core team that perform common tasks, some #BigTech companies might even achieve this with in-house command-line tools you run when creating a new API that will ask you some questions regarding your API requirements and create an entire scaffolding with the required dependencies cloned within it and pre-filled example files where the developer just needs to replace the sample code with their own code, and they are done.
In this case, developers might not even be aware of the name of the HTTP “Router” (I will never understand this name, for me a router is an obscure Cisco box no one wants to ever have to touch again once it’s up and running correctly) handling the incoming requests.
We can do better: stop coding, wizard it!
Some companies with the right talent and enough experience might go even a step further and develop an APIs UI wizard that can be able to develop entire APIs through a well-designed steps wizard which might require just at some specific points entering some custom small chunks of code to tailor some very specific logic.
*Ok, I get it.. can you now stop talking and finally describe the project?!?
*My bad, Argentinian, it’s a cultural trade-off we have :P
Wrapping everything up:
So, this project, at its core, aims at being able to deliver an open-source project, maybe more of a platform at some point.. to achieve these goals.
Of course, as described previously, #BitTech companies have big in-house teams just to implement these platforms and this is (for now, wink wink, send message if interested in collaborating) a sole programmer project, so bare with me until I fully reach this goal.
Still, many of the components I will be releasing in the next days and weeks already have a decent level of robustness to full-fill each step of the process, though others are more at an MVP level or fully functional but only for specific flows or platforms.
Main Goal: Clone and forget!
At its core, I’m thinking about a project that can be re-utilized among different teams, meaning it can be tailored to their own needs, which they can clone whenever a new API needs to be developed, and they will simply only have to add their handlers code.
Everything else, until its code is deployed to production, will be abstracted and handled for them automatically, or in the worst case scenario, they might need to fill in some initial config parameters when the project is bootstrapped and perform some clicks.
So what does exactly this project handle?
Currently, the project is constituted by four self-contained project, each handling a different responsibility in the development cycle, which you can integrate individually in your existent projects to add their specific functionality in the development cycle, or you can clone the main one which its installation one-liner will integrate them all together in a new project with all the ecosystem functionality.
I will be releasing articles to present each component individually, though in the next sections, I will be describing them briefly so you can get the overall idea, and I will use this article to present the project in charge of handling the Continuous Integration & Delivery Pipeline, GWY.
Terraform: Infra and Deployment Abstraction
Infrastructure provisioning, scalability and deployment strategies, together with the underlying cloud platforms where our code is deployed, is usually abstracted from us in #BigTech development ecosystems, so..
We need to achieve this goal too.
The component in charge of this responsibility is called GTY,
with full infamous name Go Terraform Yourself!

I have a thing for this naming convention for tools that
automate stuff, my bad, though looks fun in pictures?)
So what is, Go Terraform Yourself?
From a client point of view, it’s just a small configuration file located in your repository somewhere, actually a very small Terraform module that only holds a configuration object, agnostic of platforms specs, that goes something like this:
locals {
##########################################################
# deploy action to execute and target cloud platforms #
# - actions: ["deploy", "rollback", "finish"] #
# - targets: ["aws"] #
# #
# NOTE: GCP will be supported in first official release #
##########################################################
action = "deploy"
target = ["aws", "gcp"]
########################################
# application deployment configuration #
########################################
application = {
# application identifier information
name = "team-app" # application name (you can use "company-team-app" convention)
env = "develop" # application environment (develop, production, etc)
tags = {} # application client specified tags for all provisioned app resources
# application run-time information
version = var.ver # application version (new deploy on remote mismatch)
image = "os:ubuntu(x86).with(docker)" # application image to deploy
instance_type = "small" # application container (defined in globals.container object)
instances = var.instances || 2 # application number of instances to distribute among AZs
# rename to bootstrap
user_data = <<-EOF
#!/bin/bash
${local.scripts.bootstrap} "${local.application.ver}"
EOF
# application networking information
ports = [
{ port: 80, protocol: "TCP" },
{ port: 8080, protocol: "TCP" },
]
# application deploy subnets (public or private)
subnets = "public"
}
##################################################
# deployed application traffic forwarding config #
##################################################
forwarding = {
#
# traffic weight distribution for new blue / green
# deployment pool. For example, 10 will route 10%
# of the traffic to the new deployed pool until you
# run the either a 'finish' or 'rollback' action,
# moving the remaining 90% to new pool (finish) or
# 100% back traffic to previous version (rollback).
#
# NOTE: If you want to attempt an "all in" deploy,
# you would simply use a weight of 100, and you can
# still issue a 'rollback' if something goes wrong.
#
# Additionally, GTY ensures new pool instances are
# ready to receive traffic before "attaching them"
# to the load balancer, so you shouldn't see down
# time in all-in deploys either.
weight = 40
#
# deployed application load balancer configuration
#
# In this section you can customize the forwarding
# rules of the load balancer GTY will create if
# requested to do so. Otherwise, if you already
# have an lb created and want GTY to attach the
# created application pools to it, you can set
# option "custom" and pass the lb ID in each cloud
# platform in the next cloud specific specs section.
#
load_balancer = {
# should GTY create new lb or use an existent one?
# available actions = ["create", "custom"]
action = "create"
# load balancer traffic forwarding rules.
ports = [
{
port: 80,
protocol: "HTTP",
rules: [
{
priority = "bottom"
target_port = 80
host = ["*example.com"]
path = []
query = []
}
]
},
]
#
# lb response when inbound traffic doesn't
# match any of the existent forward rules,
#
# NOTE: ignored when using "custom" lb
#
not_found = {
content_type = "text/plain"
message_body = "404: Not Found"
status_code = "404"
}
}
}
infrastucture = {
##########################################################
# Amazon Web Services infrastructure config just in case #
# client doesn't want to rely on GTY machinery to create #
# all new infrastructure and wants to use existent one. #
# #
# For example, in this section client can specify target #
# VPC to perform deployments instead of GTY using the #
# account's default, specify an existent load balancer #
# ID when requested to use an existent one, etc #
##########################################################
aws = {
# vpc where to perform deployment, client can either
# pass the id of a specific one or use "default" one
vpc = "default"
# if you are requesting the usage of an
# existent load balancer, kindly fill lb
# and listener ids so GTY can transparently
# integrate deploys into your current config
load_balancer = {
arn = "lb_arn"
# When LB is not created by GTY, client needs to specify
# a security group attached to the existent LB that would
# allow instances to receive traffic from it. At some point
# I thought about performing its discovery, but even finding
# an attached one which outbound rules might match those of
# instances inbound traffic, still, there might be rules in
# the middle that prevents the traffic from reaching the
# instances, so, as its not that much of a headache, client
# needs to specify the lb security group that would allow
# GTY to set instances sg to accept traffic from it.
sg = "lb_security_group"
}
}
}
Together to this file somewhere in your project, there is a tree of directories with a lot of Terraform modules that perform a pretty decent amount of actions and discovery to automate the whole provisioning, scaling and safe (blue/green) deployment of your applications, which you will only be checking if you need to make some tailored changes.
If you pay attention to the file, you will realize the file, actually a Terraform module, is agnostic of the target deployment platform except for some cloud specifics we can’t work around:
target = ["aws", "gcp"]
Target tells GTY the target cloud platforms where you want your application to be deployed, bare with me, currently only AWS is supported, thought I’m already working in the integration of GCP.
The whole idea of the project is to be able to talk to it in a “higher level” agnostic “language” and it to take care of getting your application deployed without much knowledge, or any at all, of networking stuff or its best practices and configuration, no matter the target platform, no matter multi-cloud.
instances = 2 # application number of instances to distribute among AZs
subnets = "public" # application target subnets (public or private)
Each time you deploy an application using GTY, moreover the first deploy, it will perform a series of discoveries in your current infrastructure to safely meet the required criteria and, if it changed from the previous run, safely re-provision what it is required to do so.
For example, the first time you run GTY, it will discover the existent subnets, assessing if they are private or public inspecting the available routing tables, and depending on the specified “subnets” value (public or private), it will attempt the deployment on the corresponding ones.
Additionally, the specified number of instances deployed will be distributed among the available subnets meeting the criteria. For example, if you specify that you want three instances running your application and it assesses you have three different subnets, then one instance per subnet will be deployed. If you specify 5 instances, then it will deploy 2, 2 and 1.
GTY takes care transparently of instances availability zones distribution.
ports = [
{ port: 80, protocol: "TCP" },
{ port: 8080, protocol: "TCP" },
]
# ...
traffic = 40
If you noticed, you also have information regarding your application listening port, because GTY will also handle the entire configuration of your infrastructure to receive requests with the information provided in this file.
Focusing on the currently supported platform, AWS, the first time you run GTY, it will create (or re-use an existent one if you specify its ARN) a load balancer and two target groups (pools) for safe blue/green deployments, which will configure to receive the corresponding incoming traffic of your deployed application.
Two target groups are created to be able to quickly, transparently and without down-time perform subsequent deployments. The first time you perform a deployment, it will pick one of the created target groups, assign to it the specified number of instances distributed among the different AZs (subnets) and route 100% of the traffic to it.
# Supported Actions: ["deploy", "finish", "rollback"]
action = "deploy"
# ...
version = var.ver # ("1.0.0")
The next time you perform a deployment, it will transparently attempt the same action on the reserved target group and distribute the specified “weight” of traffic to it.
In the provided example it will route 40% of the incoming traffic to the new deployed version instances, and 60% will keep going to the previously deployed version. You can actually enforce, if you want, “all in” deploy strategies by setting the traffic weight option to “100”, making GTY route all incoming traffic to the new deployed target group (pool).
Additionally, something I noticed is not talked much around in papers describing how to implement blue/green deployments, there seems to be some twerks in AWS which if you are not careful and actually wait for the new instances to be really available to receive traffic, you might see temporary unsuccessful traffic routing to the new instances, which you don’t need to worry, GTY takes care of it for you, you won’t notice downtime with its deploys.
Even if you opt to forward 100% of the traffic on new deployments, which I wouldn’t unless you are working on a staging environment, the previous deployment pool will always be available until you either finish or rollback the last deploy. Actually, GTY will refuse to perform new deployments when there are two active pools running, you either rollback to previous version, or finish the last deployment.
But how does GTY differentiate between new deployments?
It simply checks the mismatch of the new deploy “version” parameter with the one currently deployed in the cloud, if it differs from the current active deploy (remember it will reject new deploys when there is currently two active pools running with different versions until you either finish or rollback), it will attempt a new deployment.
If it matches the current running remote version, it will assume the client is asking only for architecture provisioning, for example increasing or decreasing the number of running instances, which as stated before, will safely perform. If decreasing, it will first remove them from the running target group before terminating them, if increasing, it will attach them to the target group once they are ready to process traffic.
Thus, GTY could also be integrated in in-house infra provisioning ecosystems to up/down scale current running applications instances, triggered by internal traffic metrics. When detected, these systems could simply clone the corresponding target application repo and just run GTY with the new required number of instances.
But how does GTY identify the remote running version?
GTY actually constructs and uploads to the target cloud platform, S3 in the case of AWS, its own state file just like Terraform maintains its own one, you can think about it as a business json state file on top of Terraform’s one, which contains information regarding the infrastructure discovery, each instances pool (security groups in case of AWS) “version” parameter at the time of deployment, subnets information, etc..
Actually, the most fun and challenging part of this project is approaching this technique, which is actually the one that allows it to work in this automatic and agnostic manner. There are some interesting techniques and approaches I implemented regarding this remote state file that will be described in detail when describing its internal design when I write the next article presenting this project in much more detail.
I leave you for now an (old) example GTY state json for AWS platforms that each deployed application gets generated and stored in each deployed platform which uses to assess transparently if it needs to provision infrastructure, attempt new deployments or finish / rollback an existent one:
{
"current": {
"application": {
"instance_type": "small",
"env": "develop",
"image": "ami-04b4f1a9cf54c11d0",
"instances": 3,
"instances_max": 10,
"name": "team-app",
"port": "8080",
"protocol": "HTTP",
"subnets": "public",
"tags": {},
"user_data": "IyEvYmluL2Jhc2gKZWNobyAiSGVsbG8sIFdvcmxkISEiID4gaW5kZXguaHRtbApweXRob24zIC1tIGh0dHAuc2VydmVyIDgwODAgJgo=",
"version": "1.0.0"
},
"infrastructure": {
"pools": [
{
"container": "t2.micro",
"image": "ami-04b4f1a9cf54c11d0",
"instances": {
"subnet-0623673c43bb109b5": 1,
"subnet-0678766c6e5936970": 1,
"subnet-093108f570e6c8ecc": 1
},
"instances_max": 10,
"traffic": 100,
"user_data": "IyEvYmluL2Jhc2gKZWNobyAiSGVsbG8sIFdvcmxkISEiID4gaW5kZXguaHRtbApweXRob24zIC1tIGh0dHAuc2VydmVyIDgwODAgJgo=",
"version": "1.0.0"
},
{
"container": "",
"image": "",
"instances": {},
"instances_max": 0,
"traffic": 0,
"user_data": "",
"version": ""
}
],
"productive_pool": 0,
"region": "us-east-1",
"subnet_instances": {
"subnet-0623673c43bb109b5": 1,
"subnet-0678766c6e5936970": 1,
"subnet-093108f570e6c8ecc": 1
},
"subnet_private": {
"subnet-02f8a4e33ba689f99": "us-east-1e",
"subnet-044b70efb468abc5a": "us-east-1a",
"subnet-0ff289eb2db6d0bb6": "us-east-1b"
},
"subnet_public": {
"subnet-0623673c43bb109b5": "us-east-1f",
"subnet-0678766c6e5936970": "us-east-1d",
"subnet-093108f570e6c8ecc": "us-east-1c"
},
"tags": {
"gty": "app:develop",
"gty_app": "app",
"gty_env": "develop",
"gty_hash": "YXBwOmRldmVsb3A="
},
"vpc": "vpc-0ba65d45d247c896d",
"vpc_arn": "arn:aws:ec2:us-east-1:825765421857:vpc/vpc-0ba65d45d247c896d"
}
},
"previous": {
"application": {
"container": "small",
"env": "develop",
"image": "ami-04b4f1a9cf54c11d0",
"instances": 1,
"instances_max": 10,
"name": "app",
"port": "8080",
"protocol": "HTTP",
"subnets": "public",
"tags": {},
"user_data": "IyEvYmluL2Jhc2gKZWNobyAiSGVsbG8sIFdvcmxkISEiID4gaW5kZXguaHRtbApweXRob24zIC1tIGh0dHAuc2VydmVyIDgwODAgJgo=",
"version": "0.0.1"
},
"infrastructure": {
"pools": [
{
"container": "t2.micro",
"image": "ami-04b4f1a9cf54c11d0",
"instances": {
"subnet-0623673c43bb109b5": 1,
"subnet-0678766c6e5936970": 1,
"subnet-093108f570e6c8ecc": 1
},
"instances_max": 10,
"traffic": 60,
"user_data": "IyEvYmluL2Jhc2gKZWNobyAiSGVsbG8sIFdvcmxkISEiID4gaW5kZXguaHRtbApweXRob24zIC1tIGh0dHAuc2VydmVyIDgwODAgJgo=",
"version": "1.0.4"
},
{
"container": "t2.micro",
"image": "ami-04b4f1a9cf54c11d0",
"instances": {
"subnet-0623673c43bb109b5": 1,
"subnet-0678766c6e5936970": 0,
"subnet-093108f570e6c8ecc": 0
},
"instances_max": 10,
"traffic": 40,
"user_data": "IyEvYmluL2Jhc2gKZWNobyAiSGVsbG8sIFdvcmxkISEiID4gaW5kZXguaHRtbApweXRob24zIC1tIGh0dHAuc2VydmVyIDgwODAgJgo=",
"version": "1.0.5"
}
],
"productive_pool": 0,
"region": "us-east-1",
"subnet_instances": {
"subnet-0623673c43bb109b5": 1,
"subnet-0678766c6e5936970": 0,
"subnet-093108f570e6c8ecc": 0
},
"subnet_private": {
"subnet-02f8a4e33ba689f99": "us-east-1e",
"subnet-044b70efb468abc5a": "us-east-1a",
"subnet-0ff289eb2db6d0bb6": "us-east-1b"
},
"subnet_public": {
"subnet-0623673c43bb109b5": "us-east-1f",
"subnet-0678766c6e5936970": "us-east-1d",
"subnet-093108f570e6c8ecc": "us-east-1c"
},
"tags": {
"gty": "app:develop",
"gty_app": "app",
"gty_env": "develop",
"gty_hash": "YXBwOmRldmVsb3A="
},
"vpc": "vpc-0ba65d45d247c896d",
"vpc_arn": "arn:aws:ec2:us-east-1:825765421857:vpc/vpc-0ba65d45d247c896d"
}
},
"state": {
"bucket": "gty.repository",
"name": "state_app_develop.json",
"path": "gty.repository/state_app_develop.json"
}
}
Why are you saving this information remotely?
Because remember, this is just one component with its own responsibility in a much bigger ecosystem. Another component, the CI/CD Pipeline I will be presenting in the next section, leverages it so you can have -with one click- your new released version deployed to production, or automatically if you decide to trigger the deployment workflow on merges to the master branch.
When triggered, this workflow will run GTY over it, setting the described “version” parameter with the value extracted from a release branch or the latest tag assigned in the master branch, and the rest of the current running application infra will be assessed from its remote business file, just like you should be doing with Terraform native state file.
When running the upscaling / down-scaling workflow (or others), it will do the same exact work, but will additionally set the “instances” parameter.
As you can note, by having this information stored remotely, your GTY file (Terraform) in your repositories won’t require to be updated at all, you will only configure it once, when the project is created to full-fill its overall initial requirements and after that, you will focus on just running GTY (terraform apply) with the new desired inline higher level new parameter changes and GTY will take care of the rest transparently, making it very easy to maintain and hook in CI Pipelines or external schemes.
Finally! What about the running instances?
image = "os:ubuntu(x86).with(docker)" # application image to deploy in container
instance_type = "small" # application container (defined in globals.container object)
bootstrap = <<-EOF
#!/bin/bash
"${local.application.ver}"
EOF
As you can notice, this chunk is also platform-agnostic, you just specify the container requirements, in this case “small” size (just a table matching “agnostic types to cloud specific IDs”, though I’m already working on a module that uses a more rich identifier convention that allows you to specify the instance hardware specs like CPU and memory, and GTY will automatically pick the best match for it in each target cloud platform).
The shown example picks a linux-based AWS AMI with Docker installed and runs GTY bootstrapping script, which by default simply pulls from each target platform repository your app image which is supposed to be uploaded previously by other means, with the corresponding version tag.
The script calls two pre / post pull scripts, empty by default, clients can edit to inject their own custom commands in the process.
The project I will be presenting in the next section, the CI/CD component with infamous name Go Workflow Yourself, will take care of performing the apps Docker image push and tag in cloud registries, more on this later.
So, to (finally!) end this component description..
What I just showed you is a minimal config, cloud-agnostic and multi-cloud Terraform tool that takes care of the infrastructure provisioning, configuration, scaling and safe deployment with different strategies of your releases, with just a few required initial configuration parameters and forget.
Which the CI/CD component described in the next section will leverage for you to not even be aware of its existence, you will just run a manual workflow from within your application GitHub Actions section to perform a deployment, or automate its triggering automatically when a new release is merged to the master branch.
I consider the current status of this project as an MVP, though you might put it at a much mature level. It currently supports the initial provisioning of the whole infrastructure (load balancer, listeners, target and security groups, routing / traffic rules and ECR instances distribution among availability zones) and secure deployment of release images already stored in ECR using “all-in” or “blue-green” deployments with rollback support for AWS platform.
One of the main strengths of this component is actually one that was not actually cited so far, but you might have still realized it. Except for one or two very specific actions that can’t be done through Terraform and requires using externally cloud CLIs, every task performed by GTY is done through Terraform resources, meaning you won’t have a difficult learning curve like you might have with other similar projects to “hack it”.
You just find the resource you want to tailor some detail, and you edit it, and will be tailored only to your own application repository if you happen to be in a #BigTech ecosystem environment.
For example, GTY first official release will actually include auto rollback / finish of deployments based on new deploy inbound traffic errors, adding this feature, which in some projects might be a major code update and milestone, was actually, just a one day of work feature branch. Many features that might sound complex like this, after its overall core was finished, were added very easy, meaning GTY could also be seen as a “Terraform deployment framework” to leverage in order to deploy your own in-house development platform.
This component will be opened in the next week or two as a beta version, gaining “official release” status once the same functionality is supported for GCP platforms, which will allow me to have a better understanding of the required cloud-agnostic configuration options to support entirely different cloud platforms. Thus, the “beta version” config file might be subject to changes from beta to official release.
GitHub Actions: CI/CD Pipeline
So we already have, more or less, at least reaching there, the whole infrastructure provisioning and deployment abstracted from us, at the best of our possibilities, mimicking a #BigTech development ecosystem, at least a command line-one, with Go Terraform Yourself!
But we are missing another very important pillar of these ecosystems, the Continuous Integration and Delivery Pipeline. So, in this article, I will be presenting you the component in charge of this responsibility..
Go Workflow Yourself!

The project in charge of this responsibility, which you can also clone and integrate in your current Go APIs individually without the need to use the whole ecosystem, is called GWY.
What is GWY main idea?
GWY leverages GitHub wonderful ecosystem, together of course with the use of different great open source projects listed in its documentation, to detect different issues in your code base, to attempt to guarantee the integrity of your development cycle implementing a fully-fledged Continuous Integration and Delivery Workflow using GitHub Actions ecosystem.
Follow the instructions for its installation in its documentation, but the main idea is just to clone the project in your application repository and next time you open a Pull Request,
It will perform the following actions for you:
unit tests and coverage check
hardcoded secrets scan
vulnerabilities scan
outdated dependencies scan
gofmt, linting and bugs scan
automatic generation and update of badges
generation of artifacts evidence with all the above
You can check here a full GWY report.
**Note:** To view the full workflow report, including the Job Summary
section, please ensure you’re logged into GitHub. Anonymous users may
only see annotations and artifacts sections in report.
Additionally, when possible and if configured to do so (enabled by default), it will attempt to automatically fix found issues, by creating a new Pull Request with the required fixes to the branch triggering the issues.

Even though you will be most certainty relying in its main CI Pipeline (which by default trigger upon each Pull Request creation, but you can configure like any other Workflow to trigger with whatever event you want),
GWY also allows you to run its main CI Pipeline and all its individual action workflows manually over any desired target branch, just in case your current development environment is not ready to go “all-in embargo” if certain criteria is not met, allowing you to just scan your branches manually whenever you want. Still, you can trigger GWY on every pull request and configure a bool config option to allow the PRs merges even if GWY finds issues in your code (by default this option is disabled).
Running Workflows manually allow you to additionally change any of the configured parameters. For example, by default GWY will check your application “go.mod” Go version to set up the workflows to perform its checks, though you can specify any desired Go version when you run them manually, for example to test the compatibility of your code with new Go versions.

GWY will trigger (after each merge to master or main branches) a workflow that will automatically generate a lot of different badges you can embed in your documentation, with different styles, sizes and colors for you to choose:
License (detects different popular licenses presence)
Downloads (project current downloads count)
Issues (project current listed issues)
Release Date (project last master commit date)
Contributors (project number of contributors)
Project Stars
Go Version (project’s go.mod Go version)
“Powered by GWY” :P
You can check all the generated badges here.
**Note:** To view the full workflow report, including the Job Summary
section, please ensure you’re logged into GitHub. Anonymous users may
only see annotations and artifacts sections in report.
The workflow uses Shields.io service to generate its badges, and it can save the generated badges in an orphan branch in your project so you can embed them in your documentation, getting your documentation updated automatically after each new release. You can also schedule a daily job to run the workflow, updating automatically all your count badges like “Downloads” or “Stars”.

There is also a lot of work around GWY to present cool looking clickable reports, evidence artifacts, etc. so you can quickly assess from within the CI report each noticed issue, taking you directly to the code triggering it.
You can check a report and generated artifacts here.
**Note:** To view the full workflow report, including the Job Summary
section, please ensure you’re logged into GitHub. Anonymous users may
only see annotations and artifacts sections in report.
Additionally, each Workflow report will attach evidence artifact Markdowns with the displayed report in GitHub together with each issued command entire output so you can easily debug any issue without having to browse the entire workflow debug output which sometimes might get messy (we all have been there :P).
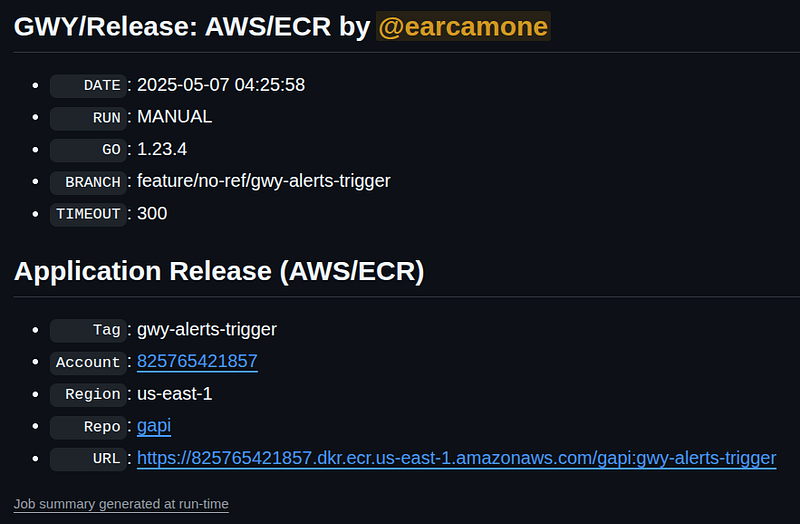
Additionally, there is a Workflow which is configured to run manually, thought you will be able to make it trigger whenever you merge a new release to master in next release, that will build your application using its Dockerfile expected to be located at the project’s root and upload it to AWS/ECR.
You can check a release workflow here.
**Note:** To view the full workflow report, including the Job Summary
section, please ensure you’re logged into GitHub. Anonymous users may
only see annotations and artifacts sections in report.
Next release, after I open the previously mentioned project (Go Terraform Yourself), will include a Workflow to perform blue/green deployments and all GTY actions with just a click from within your application repository GitHub Actions section, simply leveraging GTY, turning this project in a multi-cloud platform Continuous Delivery Pipeline too.
Even though I’m envisioning (it’s fun, why not?) in a not that near future a platform that implements a tailored UI panel like the ones developed in-house in #BigTech companies, for now, the project simply aims at turning GitHub as this panel.
Too much chit-chat! and the Go APIs?
Good point tech compatriot, when you are right, you are right :P
There are two components that handle this responsibility, and both, just like the others, can be used independently and integrated in your projects without needing to use the whole ecosystem, though this one, the one I’m about to describe, is the one that tights them all together.
This one is probably something you must be already imagining, though the other, might be a pretty decent new idea around for back-end development, a sort of React for the back.. thought it has nothing to do with what might come first to mind, server-side rendering of the front.
Like React, if you allow me to reduce such a wonderful project to a simple definition of course, it’s just a new idiomatic way of thinking our back-end APIs, with an interesting declarative syntax (basically a framework with some -hopefully- well thought throw abstractions and mechanisms to connect them all together) that allows you to easily model all the higher level actions the majority of our back-end APIs do in a declarative way, leveraging interestingly some Go built-in functionality like meta-tags.
So let’s start with the simple and easy to understand component,
GAPY (See if you can guess this one, Go.. Go API.. Go API Your.. :P).
Go API Yourself!
GAPY is just, or yet, another clone-and-forget Go API scaffolding with some custom middlewares and simple layers / abstractions over a Chi Router which attempts, like the other components, to allow you to “automate” its responsibility so you just focus on your API handlers code.
Aiming at being reusable among different teams, lone freelancer wolves or even the ease of development of a huge monolithic API with hundreds of routes which might be maintained by different isolated teams.
Following are some of the features it attempts to solve for you, nothing that much fancy in this project I might add, though it might become with time, it is just the component that tights the whole ecosystem together, meaning this is the component you will be cloning when creating new APIs if you want to use the entire ecosystem and not use some of its components individually (like GWY or GTY) in your existent projects.
Centralized error handling scheme:
It implements an error handling middleware with some helper functions which you can use to fail fast in your handlers, thought it has the ability to detect if you are using the feature or not, allowing you to keep using your current handlers error code and gradually upgrade to it.
Additionally, it allows you to register different callback functions that the scheme will call when it returns from your handlers’ with an error, at the end of the middlewares call chain, so you can inspect errors and trigger desired metrics and/or alter the default built-in error response.
At the end of the day, it aims at allowing you to have some nice looking small chunks of code on each “failing fast” handlers return block, allowing you to give control to a central error handling scheme at the end of the request chain where you can centralized build all your different error responses, triggering corresponding metrics, attaching required context to them, etc.
Here is a sample snippet:
if err := json.NewDecoder(r.Body).Decode(&book); err != nil {
errorscheme.WithError(r,
errorscheme.NewAppError(http.StatusBadRequest, "invalid request body", err),
)
return
}
Note that “NewAppError” function is just a built-in factory function that builds an object following GAPY error interface which you can extend to attach any desired context information and because you can, and actually should, register your own functions to handle the construction of error responses, you can do whatever you need when you are given back control in these functions, like throwing metrics.
Distributed or per-instance Rate Limiting:
Either local (in-memory per instance) or distributed, you can enable at bootstrapping a built-in Rate-Limiter middleware with different built-in policies (Per IP, Per End-Point, etc.) or you can build your own custom one very easily with the current scheme implementation (Policies are just a callback that receive the request information and return a key string, the existent policies are just parametrisable constructor functions that build a Policy callback function).
When configuring this middleware, its first parameter (Policy is the second) is an abstraction implementing a Key/Value store interface, the project has built-in one using an in-memory KVS (Rate Limiting per instance) and another for Redis, allowing you to easily support distributed Rate Limiting using Redis clusters.
The Redis scheme attaches a LUA script you will need to load in your Redis cluster, as the middleware utilizes a custom Redis operation to perform increments and handling of TTLs in one operation to increase performance and avoid “networking race conditions”.
Graceful API Shutdown:
It’s not that uncommon to see well coded APIs forget to handle this, which requires just a small chunk of code actually, but can make a huge difference in your client’s experience, more over when integrated with the blue/green deployments performed by GTY.
Just in case you are not aware of, HTTP Routers, the applications handling the received HTTP Requests like Chi, have an option to gracefully shutdown, meaning to stop handling new requests but giving time for the current ones being processed to end.
Usually it’s just a function you call with a timeout, which will exit either when all active HTTP requests had been processed or the specified TO is reached.
It is not that uncommon to see APIs not using this functionality, which simply entitles hooking with a small chunk of code to operating system signals received when a process is finished, so you can call this Router function and allow the router gracefully terminate all active requests, instead of getting your application abruptly terminated, together with the client connections.
So there is a scheme implemented to handle this, together with the capability of registering functions of your choosing that will be called when this signal is detected, so you can perform whatever additional actions you might need, for example throwing some custom metrics noting API process termination or similar.
Dependencies Injection:
There is always this discussion, if you actually do dependencies injection in your applications which you should, on where you should locate and proxy your dependencies inside your code to be accessible when required without much of a head-ache.
GAPY has a built-in “abstraction” which is intended to be used to attach your services injections (or similar) in your APIs for easy access, trying to make the code not get messy if you happen to have one of those APIs mentioned with hundreds of handlers maintained by different teams where each handler might be using different service modules.
Docker multi-staging build with auto-versioning:
GAPY is delivered with a simple multi-staging build Dockerfile which has a very silly functionality but that is very useful, moreover if you ever forgot to change the API version in your application code when deploying it.
Maybe you don’t even bother to have the current API version in your code, or it’s injected in an environment variable for its access by your deployment ecosystem, though this technique might be prone to errors or inconsistencies.
Anyway, it’s always good to attach in your logs at some point the current API running version in case you have to troubleshoot an event, didn’t we all have a weird event arise and had simply to do with an incorrect version re-deployment?
So, the Dockerfile will actually attempt to set the corresponding API version using -LDFLAGS compiler option in the corresponding config module, so the binary has always the right version within it.
The version is actually expected to be passed upon build by the caller issuing the Docker build, which if you are using “GWY Release” workflow, does transparently for you. It will pass the parsed version if releasing a release branch, the latest available tag if releasing master branch or will pass the entire branch name if releasing a feature branch.
If no version is passed upon image build, it will simply use “develop” as it is assuming the API is being run in a workstation by a developer testing something, instead of a configured CI Pipeline passing the corresponding version to it.
Isolated handlers and services scaffolding design:
Not much to write about this, GAPI just tries to have a scaffolding with a tree that would not get messy if different teams are maintaining a same API with hundreds of routes and their own services, trying to “isolate” things in such a way where each team adding its code would not trigger complex conflicts upon code merges from different teams in the same code base.
Sticking all together:
At the end of the day, thought it might get bigger with time to support new feature requests, GAPY is just a simple reusable HTTP API scaffolding with some basic helper schemes, that sticks all projects together to get the entire ecosystem going.
You can, if you want, just clone GAPY instead of using the installation script that integrates all other projects of the ecosystem together, but you would then be loosing all the fun and, if that would be your case usage, you might want then to code your own tailored GAPY like project.
The main idea behind GAPI is to be the go-to project to access the whole ecosystem described in this article, sticking all together the different described projects to get a full-fledged, clone-and-forget, development ecosystem that you can simply focus in just adding your handlers code and almost everything around it, from its CI/CD Pipeline, to your infrastructure provisioning, scaling and safe deployments, are handled for you easily with just a few clicks from within your repository GitHub’s Actions section.
OK! I get it! But what about the React for Go back-end APIs? Where it is?!?!
Smashing the way we think our APIs for fun and profit

Will be continued, stay tuned :)
Subscribe to my newsletter
Read articles from Emiliano Arcamone directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by