SQL & No SQL: Relational vs Reality
 dileepkumar
dileepkumarDatabase
Before the database was born, data was stored manually in libraries, filing cabinets, paper records in journals etc. which made management and retrieval of data cumbersome. With the rise of computers in the 1960’s there was a growing need for an efficient way to manage, retrieve, update and store the data.
An electronic database…
A database is an organized collection of structured information or data, typically stored electronically in a computer system. It is designed to allow easy access, management, modification, and retrieval of data. Databases are usually managed by a database management system (DBMS), which interacts with users, applications, and the database itself to capture, store, and analyze data. Together, the data, DBMS, and associated applications form a database system
Source: What is a database
The First Steps..
The beginning of computers in the 60’s enabled the first computerized database with introduction of magnetic disks to store the data. Charles Bachman designed first database system, Integrated Data Store (IDS) using the Network model, the first general purpose DBMS in 1963.
Later IBM developed Information Management System (IMS) in 1967-1968 as part of project for the NASA’s Apollo Space Program using Hierarchical model.
Network vs Hierarchical…
Both network and hierarchical are types of Database Management Systems (DBMS)
Hierarchical model organizes data in a tree-like structure similar to a family tree or an organizational chart. Data is stored as records and each record is linked to others through parent-child relationships. There is a single root record at the top i.e., each child has only one parent whereas each parent can have multiple children. This creates a clear one-to-many relationships through out the database. To find the data, we start at the root record and follow the branches to the record you want to fetch.
Example for a hierarchical model:

Source: Hierarchical database model
Network model is an extension of hierarchical model. It organizes data in a web/graph like structure allowing each record to have multiple parents and child records supporting many-to-many relationships. There is no single root record in this model and data can be accessed through various entry points. For example, a student can enroll in multiple courses in a college, and a course can have many students and similarly college can offer multiple courses and so on…
Network model was widely used before relational model came into picture (which we will see later in the blog…). Example for a hierarchical model…
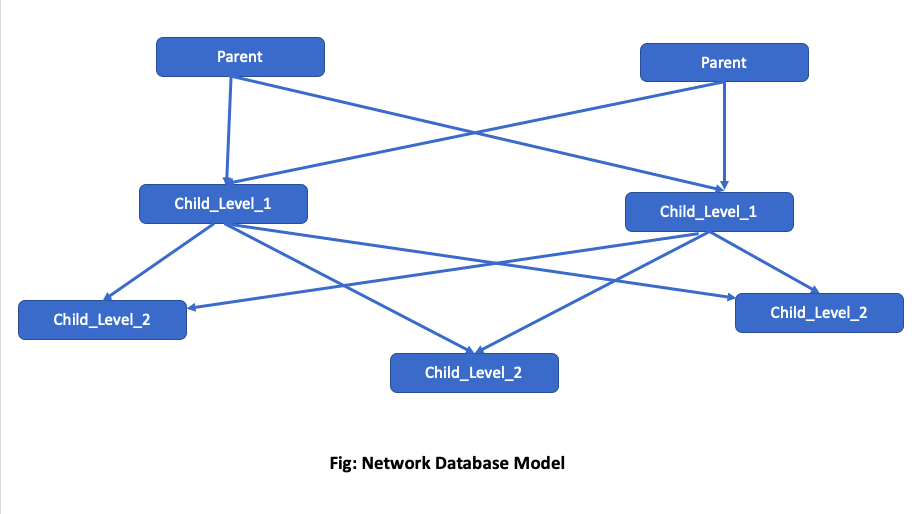
Source: Network database model
SQL - The Relational Revolution
In the 1970s, Edgar F. Codd at IBM introduced the relational database model, fundamentally changing how data was organized and accessed. Instead of navigating through links (like its predecessors Hierarchical, Network models), data was stored in tables, and relationships were managed through keys and set-based operations.
Codd's model separated data storage from applications and enabled querying through structured languages, making data access more flexible and efficient. IBM developed System R, a prototype relational database, in the mid-1970s based on Codd’s model. Donald D. Chamberlin and Raymond F. Boyce developed the language initially called SEQUEL (Structured English Query Language) to interact with IBM's System R relational database system.
Source: SQL - Wikipedia
Relational Model
SQL enables powerful, declarative queries that can retrieve, filter, and join data from multiple tables without concern for physical data paths. This makes querying faster, more flexible, and user-friendly.
Different SQL Databases
Oracle, MSSQL, MySQL, PostgreSQL, IBM DB6
NoSQL - The Web Revolution
With the internet boom in early 2000s, there was a challenge to handle huge amount of data, variety of data(images, videos, graphs etc.) and dynamically generated data. This unstructured data created challenges for relational databases to handle efficiently.
This led to the development of NoSQL (non Relational Databases) for distributed, flexible and scalable data storage.
Non Relational Models
NoSQL databases uses flexible data models like documents, key-values, graph, wide-column stores
Key-Value Model: Stores data as pairs of unique keys and associated values (Example: Redis).
Document Model: Stores data as documents (often in JSON or XML format), allowing for flexible, nested, and semi-structured data (Example: MongoDB).
Column (Wide-Column) Model: Organizes data into columns rather than rows, enabling efficient storage and retrieval for analytical queries and large datasets (Example: Cassandra).
Graph Model: Represents data as nodes and edges, focusing on relationships between entities. This model excels in use cases like social networks or recommendation systems where connections are central (Example: Neo4j)
Source: What is noSQL Database
Different NoSQL Databases
MongoDB, Redis, Apache etc.
An example of SQL vs NoSQL
A generic example (Warehouse vs Supermarket) to understand SQL vs NoSQL
Warehouse = SQL Database
In a warehouse, everything is stored in a very organized way.
All items are stacked in fixed rows and sections—boxes of the same type are always kept together.
To add a new type of item, you must rearrange or create a new section for it, following the warehouse strict storage rules.
If you need to find something, you look at the inventory list, and you’ll know exactly where it is because everything has a fixed place.
This is like an SQL database:
Data is stored in structured tables (like the organized shelves).
Everything follows a fixed format (schema).
It’s easy to find and manage items if you know the rules, but changing the structure is difficult
Supermarket = NoSQL Database
In a supermarket, items are displayed in many ways: some on shelves, some in baskets, some in promotional stands.
New products can be added anywhere. Sometimes you’ll find a new snack on a special rack or a new section appears overnight.
There’s a lot of flexibility in how things are arranged, and different items can have different types of information (some have labels, some have offers).
You might need to look around a bit more, but it’s easy for the store to adapt and change what it offers.
This is like a NoSQL database:
Data can be stored in different formats and structures (like the flexible displays).
There’s no strict rule for how things must be arranged (schema-less).
It’s easy to add new types of data or change how things are stored, making it great for fast-changing needs
SQL vs NoSQL
| Feature | SQL Databases | NoSQL Databases |
| Data Model | Relational (tables). Stores data in structured tables with rows and columns. This format enforces a predefined schema, ensuring data consistency and integrity | Non-relational (document, key-value, graph, wide-column). They allow for dynamic or schema-less data storage, making them suitable for unstructured or rapidly changing data |
| Schema | Fixed and predefined. Any change in schema would require downtime. | Dynamic and flexible. Developers can change data structure on the fly without any downtime. |
| Scalability | Vertical i.e., SSD, RAM and CPU needs to be increased. | Horizontal i.e., you can add more servers and nodes to handle loads. |
| Transactions | ACID compliant (Atomicity, Consistency, Isolation, Durability), ensuring reliable and consistent transactions when on single node. SQL databases when distributed over multiple nodes, are also support CAP theorem. | CAP theorem(Consistency, Availability, Partition tolerance), some ACID support |
| Query Language | SQL | Varies (JSON, XML, proprietary APIs) |
| Best For | Structured data, complex queries | Unstructured data, scalability, agility |
| Examples | MySQL, PostgreSQL | MongoDB, Cassandra, Redis, Neo4j |
ACID vs CAP
ACID and CAP are foundational concepts in database and distributed systems, but they address different challenges and use "consistency" in distinct ways.
ACID Properties
Atomicity: Each transaction is treated as a single, indivisible unit. Either all operations within the transaction are completed successfully, or none are; if any part fails, the entire transaction is rolled back, leaving the database unchanged
Consistency: Transactions must bring the database from one valid state to another, maintaining all predefined rules and constraints. This ensures that only valid data is written to the database.
Isolation: Concurrent transactions are isolated from each other, so the operations of one transaction do not interfere with those of another. This prevents issues like dirty reads or lost updates when multiple users access the database simultaneously.
Durability: Once a transaction is committed, its results are permanent, even in the event of a system crash or power failure. The changes made by the transaction survive any subsequent failures
It is a set of properties designed for traditional, single-node databases to ensure reliable transactions.
Source: ACID Properties - Wiki
CAP Theorem
CAP stands for Consistency, Availability, Partition Tolerance.
As per CAP Theorem, In a distributed system, when there’s a network problem, you must choose between being always up-to-date (consistency) and always responsive (availability).
Consistency (C): Every read receives the most recent write or an error. This means all nodes in the system reflect the same data at any given moment—if you write data to one node, it must be instantly replicated to all others before the write is considered successful
Availability (A): Every request (read or write) receives a non-error response, even if some nodes are down. The system always processes requests and returns a result, though it may not be the most up-to-date.
Partition Tolerance (P): The system continues to operate despite arbitrary network partitions, meaning it can handle communication failures or message loss between nodes without shutting down.
In a distributed node system, network failures between nodes are inevitable. So one should choose on what is their priority. Below are different choices which one can make.
CP Systems: Prioritize Consistency and Partition Tolerance. During a partition, some requests may be denied to ensure data consistency (e.g., traditional relational databases).
AP Systems: Prioritize Availability and Partition Tolerance. The system remains responsive, but some data may be inconsistent (e.g., many NoSQL databases).
CA Systems: Prioritize Consistency and Availability, but cannot handle network partitions—rarely practical in distributed environments.
The CAP theorem is a guiding principle for designing distributed systems, forcing architects to make trade-offs based on application needs and expected network conditions. No distributed system can fully achieve all three guarantees at the same time
Source: cap-theorem
Summary
When you need your data to be structured and require strong consistency and involves complex queries, use SQL database.
However, when you need scalability, flexibility to handle various data formats like unstructured/ semi structured data and dynamically changing data use NoSQL Database. NoSQL addresses the demands of modern, data-diverse, and scalable applications.
Subscribe to my newsletter
Read articles from dileepkumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by