eBPF, the Silent Kernel Revolution: Empowering Modern Cloud Native Ecosystem
 Yash RV
Yash RV
“The Linux kernel is not just software. It's a living, growing, mutating ecosystem.”
— Greg Kroah-Hartman, Linux Kernel Maintainer
It's evident that, the bigger the system, the harder it is to manage. Complexity doesn’t just grow, it stacks exponentially. In a codebase like the Linux kernel, even the smallest shift demands precision, because it isn’t just a matter of few edits and PRs. One wrong line, and the ripple spreads, through subsystems, across dependencies, into edge cases that no one’s touched in years. We’re not tweaking some UI script that decides the color gradient of a button.
This is different… we’re touching something alive. Something with 85,000 files and nearly 38 million lines of code. And when it breaks? It doesn’t just stall a patch, but can crash millions of systems across the globe, and sometimes even running out there in space. That’s when we realize: the Linux kernel isn’t just another piece of software. It’s the foundation. The bedrock on which modern systems are built. It’s not code. It’s infrastructure. It’s blood. We don’t rewrite it. We negotiate. Carefully.
But what if you could change the behavior of your operating system without waiting on upstream patches, or rebooting, recompiling? What if you could trace every packet, every syscall, every file access, live, in production? What if you could stop an attack before it ever happens, without users noticing? These aren’t hypothetical questions. They're the promise of eBPF, a technology that's reshaping how we think about performance, observability, and security from the kernel up.
What Is eBPF ?
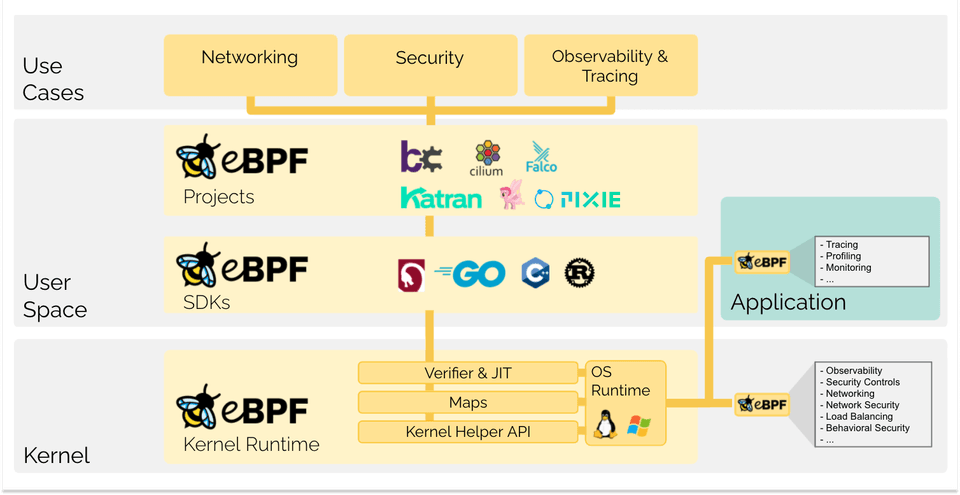
Note: Most images used in the article are from https://ebpf.io/what-is-ebpf/
The term "eBPF" used to stand for extended Berkeley Packet Filter. But that’s a historical footnote now. eBPF has outgrown its origins. Today, it lets us run sandboxed programs inside the Linux kernel, safely, dynamically, without ever modifying the kernel itself. We get programmable control over kernel behaviour. No upstream patch delays. No dangerous kernel modules.
Just clean, fast hooks into the heart of the system. It began with packet filtering. But it didn’t stop. What started as a firewall tool became a full-blown virtual machine inside the kernel. A verifier keeps it safe. A JIT compiler keeps it fast. And a growing set of hooks gives it reach, deep into networking, observability, and security. eBPF gives the kernel a programmable interface, without giving up performance, safety, or stability.
The Problem eBPF Solves

The Linux kernel governs everything from process scheduling to network stack behavior. But changing how it works used to mean:
Writing kernel code
Persuading the upstream community
Long waiting for release cycles
Rebooting machines
Risking downtime
eBPF removes that friction. Teams can patch vulnerabilities, capture metrics, and build in-line security mechanisms, without recompiling or rebooting.
For example, imagine a zero-day bug in how the kernel handles a crafted network packet. You could wait for a patch. Or you could write an eBPF program to detect and drop that packet in real-time, no kernel patch needed.
How eBPF Works
1. Compiled to eBPF bytecode.
It starts in user space. Programs written in high-level languages are compiled down, transformed into eBPF bytecode using toolchains like Clang. Only then are they loaded into the kernel.
2. Verify the Program
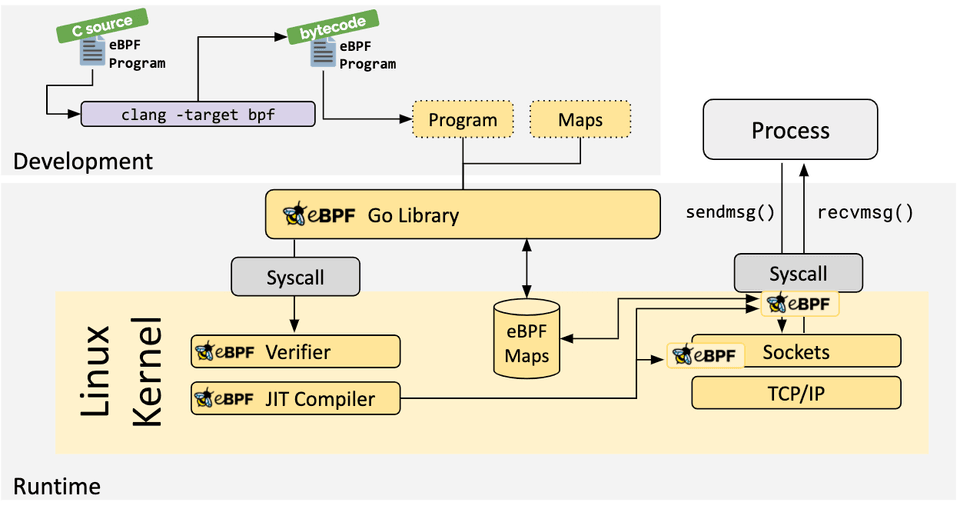
We’re in kernel space now, a privileged territory. That means one thing above all, security is non-negotiable. Every eBPF program faces a gatekeeper, the eBPF verifier. Before anything runs, it inspects the bytecode line by line and checks for.
Only authorized programs get in.
Programs must always terminate. No infinite loops or crashes.
Weather memory stays in bounds.
Checks the license. It inspects helper calls.
And if something fails? The verifier doesn't just reject it, but also shows you why, with every detailed logs.
3. Run at Near-Native Speed
The bytecode is low-level, but not yet machine code. After verification, eBPF hands it off to the JIT compiler. That’s where the real transformation happens. The bytecode becomes native machine code, tailored for the target system. This means minimal overhead. No context switches. No user space delays. It's just kernel code calling more kernel code.
4. Attach to Events
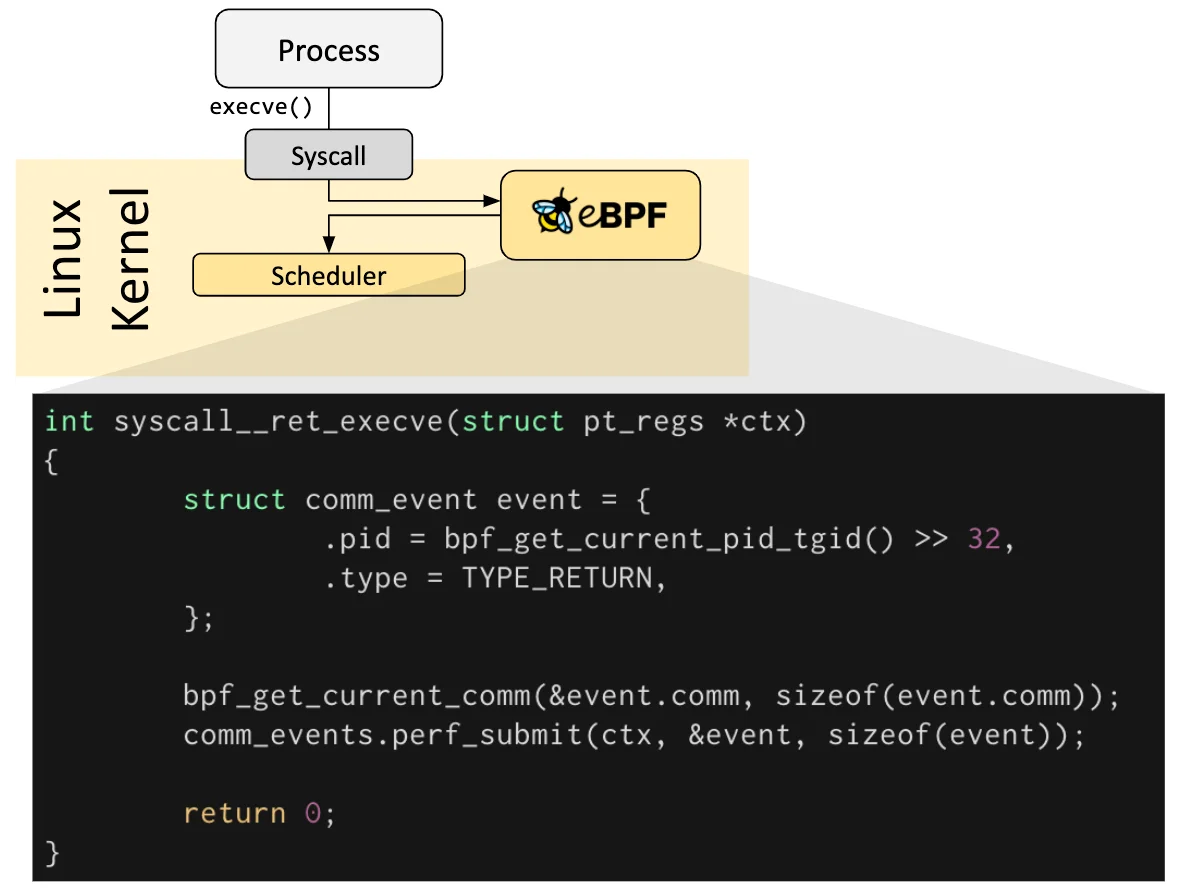
eBPF lets us attach programs to kernel events. These might be:
A system call like
execveA packet arrival at the network interface
A new process starting
A file being read
Understanding eBPF Hooks and Probes.
Most eBPF programs begin the same way, you decide what kernel event you want to observe or modify. That decision defines two things—the hook you’ll attach to, and the probe type you’ll use to get there.
Hooks
A hook is a location or event in the kernel where an eBPF program can be attached. These are the point in kernel execution, where you want to observe or modify behavior. Think of it like a socket, something you can plug into. For examples:
sys_enter_execve(a tracepoint hook)tcp_sendmsg(a kprobe hook)XDP receive path (network hook)
cgroup or LSM (security hooks)
Probes
It is a mechanism which defines how your eBPF program connects to a hook. These are like your your anchor into the kernel. There are different types of probes, each enabling attachment to specific kinds of hooks:
kprobe: dynamically attach to the entry of any kernel function.
kretprobe: attach to the return of a kernel function.
tracepoint: attach to predefined trace hooks in the kernel.
fentry/fexit (fprobes): attach to function entry/exit via BTF
raw tracepoint: low-level tracepoint access with minimal overhead

Therefore, choosing the suitable probe affects the performance, portability, and even whether your code runs on another kernel version.
eBPF Maps
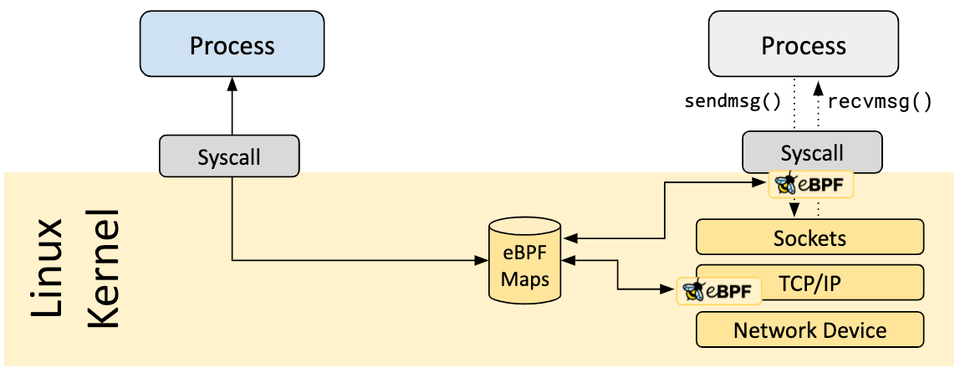
Like any other stateful system, to hold state or pass data to user space and other eBPF programs. eBPF relies on maps, key-value data structures to store data: packet counters, connection metadata, backend server health, timestamps, and more. These maps act as the memory of your kernel-resident logic.
But here’s the catch: every node maintains its own local copy of an eBPF map. This works fine in isolation, but production environments aren’t single-node sandboxes.
Well unopniated, eBPF is fast, dynamic, and powerful. No Matter What. But step back for a moment. Zoom out from a single machine to a fleet of them. In large-scale systems, where workloads shift dynamically across nodes, a deeper question emerges: What happens to state in a distributed eBPF system?
Things like, How do we ensure that decisions, like IP blacklisting or DNS rate-limiting—are applied consistently across every node in the cluster, when each node tracks its own request state?
Imagine a firewall that blocks abusive clients after 1000 requests. A client could hit node A with 800 requests, then jump to node B and make 800 more, never triggering any rate limits. To enforce a global threshold, all nodes must share state.
This brings us to a less-discussed, but very real limitation in today’s eBPF ecosystem:
At the moment there’s no built-in mechanism for synchronizing eBPF maps across machines, but alot of community works are in progress.
Helper Functions
Directly calling kernel functions from eBPF programs isn’t allowed, unless they’re explicitly registered as kfuncs. But eBPF doesn’t leave us stranded. It provides a rich set of predefined helper functions that let programs safely and efficiently interact with kernel internals.
These helpers are built into the eBPF runtime. They aren’t part of the verifier. They aren’t maps. They’re part of the program itself, but its trusted toolkit.
There are many helpers available, each tied to specific program types. Some of the most used include:
bpf_get_current_pid_tgid()- Getting the current process ID and thread IDbpf_ktime_get_ns()- Accessing current kernel time and datebpf_probe_read_kernel()– safely read kernel memorybpf_map_lookup_elem()– map interactionbpf_redirect()– used in XDP for packet redirection.Looking up, updating, or deleting elements in a map, and more…
Helper availability can vary between kernel versions, which makes portability a concern. Moreover, tools like bcc, bpftool, Cilium, and Falco rely heavily on helper functions to implement production-grade observability and security logic inside the kernel.
However, the list of available helper functions continues to grow with each kernel release. New helpers are often added to support emerging use cases in networking, tracing, security, and file system introspection.
BTF, the Invisible Backbone of Portable eBPF

It would be unfair to talk about eBPF without mentioning BTF (BPF Type Format), one of its most important, and often overlooked, enablers. It might sound like a small piece of the puzzle, but it’s one of the key reasons eBPF works so well across different Linux systems today. So what is BTF, really?
Let’s break it down with a simple idea. Think writing an eBPF program is like writing a recipe. You’ve got the steps nailed: add salt, stir for 2 minutes, grill the tofu. But then you go to cook it in a different kitchen. Now the stove is electric, not gas. The salt jar is labeled “sodium.” And the grill? It’s missing.
Your recipe didn’t change. But the environment did. That’s exactly the problem eBPF faced for years: the Linux kernel is constantly evolving. Internal data structures change—fields are renamed, layouts shift, offsets move. Even a tiny change in a struct between kernel versions could break an eBPF program completely.
This is where BTF steps in. It’s like a detailed map of the current kernel’s internal data types and structure layouts. It gives eBPF programs a way to understand the kernel they're being loaded into—without needing hardcoded knowledge of how things are laid out in memory. It’s a format that describes C types, structs, unions, enums, and more, in a way the kernel and eBPF loader can use dynamically.
So instead of guessing what the environment looks like, eBPF programs can ask the kernel, and adapt. Before BTF, the only way to deal with kernel version differences was brute force: compile a different eBPF object for each kernel version. Toolkits like bcc used runtime compilation to handle this, but it was messy, slow, and error-prone.
Then came CO-RE (Compile Once, Run Everywhere) powered by BTF, it changed everything. With CO-RE and libbpf, we can now compile a single eBPF program once, and load it on different kernel versions without touching the code again. At load time, libbpf reads the kernel’s BTF data, adjusts memory offsets, relocates struct accesses, creates maps, sets up probes, and connects everything together, automatically. So no more rebuilds and rewrites.
BTF turned eBPF from version-sensitive and fragile into something much more powerful: portable, stable, and production-ready.
Note: Some older kernels ship without embedded BTF data. In that case, you’ve got two options, but CO-RE only works when the loader has BTF visibility into the target system.
Recompile the kernel with
CONFIG_DEBUG_INFO_BTFUse an external BTF source like BTFHub to supplement missing info
BTF also powers tools like bpftool to show readable variable names and trace output. It even lets you write tracepoints without duplicating kernel structs, your code uses what’s already in the system.
eBPF in Action:
Dropping Packets
With eBPF, we can drop specific network packets dynamically. Want to drop ICMP ping requests? Write a small program. Compile. Load. Done. No reboot. No downtime. Want to stop dropping them? Load a different eBPF program.
Runtime Security Enforcement
Want to prevent a pod from making external TCP connections? With tools like Tetragon, we can use eBPF to monitor and synchronously kill a process before the connection completes. Not after. Before. That’s real-time enforcement from inside the kernel.
Observability Without Overhead
eBPF is a game-changer for tracing and performance diagnostics. Traditional tracing tools often require modifying the application, restarting services, or running costly agents. eBPF-based observability tools, like bcc, bpftrace, and Cilium—run in the kernel and attach to live processes. Brendan Gregg’s work at Netflix proved that you can find and fix performance issues at massive scale using only eBPF.
No agents
No sidecars
No context switching
No extra copies of data
You can capture stack traces, monitor syscalls, track TCP retransmits, all without touching the application itself.
Why This Matters for Cloud Native Ecosystem.
In containerized environments, all pods share the same kernel. That kernel sees everything. With eBPF, we can see everything too, without sidecars, without agents, and without YAML-driven restarts. This is crucial for:
Detecting and stopping intrusions in real time, even inside containers.
Routing packets efficiently in Kubernetes without relying on iptables.
Tracing issues across thousands of containers from a single kernel instrumentation point.
Using eBPF to build sidecarless meshes with less CPU, memory, and complexity.
eBPF gives us node-level visibility into every process, every pod, every syscall, across the entire system. Moreover security tools like Falco and Tetragon use eBPF to monitor runtime behavior. But with eBPF’s growing capabilities, we can do more than observe. We can enforce policy inside the kernel, dropping packets, blocking syscalls, killing processes, before damage is done. And because eBPF lives in the kernel, attackers can’t opt out. Even if a pod disables user space security tools, it can't escape kernel-level observation.
Is Sidecar Dead?

The sidecar pattern has long been a cornerstone of Kubernetes-based microservice architectures. When Kubernetes doesn’t offer out-of-the-box features for things like observability, governance, or traffic control, we often reach for the sidecar. It’s like a companion container deployed alongside the main app container in the same Pod.
It might host a service mesh agent like Envoy, managing traffic, enforcing policies, and collecting telemetry. Some of the popular implementations like Istio, Linkerd, Traefik, all of which use sidecars to weave service mesh functionality into each microservice. While sidecars solve real problems, they’re not the only ideal solution, and here’s why…
Resource Overhead: Sidecars results in ~2X the container count. For example, each Envoy proxy in Istio, adds about 0.35 vCPU and 40MB/1000 requests. For ten microservices, that's 3.5 vCPUs, 400MB memory, plus 1 vCPU and 1.5GB RAM for the control plane. That’s an entire extra VM, just for sidecars 😅.
Latency: Every request flows through the sidecar, adding about 2.65ms latency (P90). That may seem small for some, but in real-time systems operating at scale, it’s significantly huge number.
So, sidecars have a cost to pay in terms of more compute, more memory, and slower response times. However, with eBPF-based implementations, we can manage service mesh functionality without sidecars, giving us direct control over networking and observability needs at the pod or kernel level.
So, is sidecar dead? Not yet… but it's under pressure. And whether you should use eBPF as a complete replacement for sidecars depends entirely on your requirements. Because not all systems are designed to do the same thing, and yes it really depend…
Final Thoughts
eBPF isn’t just a tool, it’s a model shift. It redefines what’s possible in kernel-level observability, performance, and security. Whether you're running a single server or thousands of Kubernetes pods, eBPF lets you rewrite the rules of infrastructure as required, without rewriting the kernel or modules. In a world where performance, resilience, and security can't wait for kernel upgrades, eBPF is the answer. Not because it’s easy. But because it works.
Subscribe to my newsletter
Read articles from Yash RV directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yash RV
Yash RV
Yash is passionate about Distributed Systems and Observability, and creates content covering topics such as DevOps, and Cloud Native technologies.